







状态一致性
有状态的流处理,内部每个算子任务都可以有自己的状态,对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。一条数据不应该丢失,也不应该重复计算。再遇到有故障时可以恢复状态,恢复以后的重新计算,结果应该也是可以完全正确的。
状态一致性的分类
- AT-MOST-ONCE(最多一次)
- 当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重复丢失的数据。At-most-once语义的含义是最多处理一次事件
- AT-LEAST-ONCE(至少一次)
- 在大多数的真实应用场景,我们希望不丢失事件。这种类型称为at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次
- EXACTLY-ONCE(精确一次)
- 恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次的语义不仅仅意味着没有发生事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
一致性检查点(checkpoint)
Flink 的 Checkpoint 机制是其可靠性的基石。当一个任务在运行过程中出现故障时,可以根据 Checkpoint 的信息恢复到故障之前的某一状态,然后从该状态恢复任务的运行。 在 Flink 中,Checkpoint 机制采用的是 chandy-lamport(分布式快照)算法,通过 Checkpoint 机制,保证了 Flink 程序内部的 Exactly Once 语义
和上文一样的图,大家可以自行理解(戳我直达)

端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理实现的,也就是说都是在Flink流处理内部保证的;而在真实的应用中,流处理应用除了流处理器以外还包含数据源(例如kafka)和输出到持久化系统。端到端的一致性保证意味着结果的正确性贯穿六整个流处理应用的始终;每一个组件都保证了它自己的一致性。整个端到端的一致性取决于所有组件中一致性最弱的组件
端到端的精确一次(exactly-once)保证
- 内部保证 -----checkpoint
- source端 -----可重设置数据的读取位置
- sink端 -----从故障恢复时,数据不会重复写入外部系统
- 幂等写入
- 事务写入
(比如上篇文章说的,处理到数据6,7的时候任务挂了,从checkpoint=5恢复,会重新消费6、7的数据,端到端的状态一致性保证,并不意味着不重复处理数据)
幂等写入(Idempotent Write)
所谓的幂等操作,是一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说后面重复执行就不起作用了。比如HashMap,一个key多次写入,产生的效果是一样的。
事务写入(Transaction Write)
- 应用程序中一系列操作,所有操作必须全部成功,否则在每个操作中所有的更改都会被撤销;具有原子性,要么都成功,要么都失败。
实现思想:构建事务对应着checkpoint,等到checkpoint真正完成的时候,才把对应的结果写入Sink系统中。
实现方式:1-预写日志(Write-Ahead-Log WAL),2-两阶段提交(Two-Phase-Commit 2PC)
- 预写日志,把结果数据先当作状态保存,然后在收到checkpoint完成的通知时,一次性写入sink系统。简单且易于实现,由于数据提前在状态后端中做了缓存,所以无论什么时候sink系统,都能使用这种方式一批搞定。DataStreamAPI提供了一个模版类:GenericWriteAheadSink
- 两阶段提交(Two-Phase-Commit 2PC):
- 对于每个checkpoint,sink任务会启动一个事物,并将接下来所有接受的数据添加到事务里。然后将这些数据写入外部sink系统,但不提交他们-----这时只是“预提交”
- 当它们收到checkpoint完成的通知时,它才正式提交事务,实现结果的真正写入
这种方式真实实现了exactly-once,它需要一个提供事务支持的外部sink系统。Flink提供了TwoPhaseCommitSinkFunction接口。
2PC 对外部sink系统的要求
- 外部系统必须提供事务支持,或者sink任务必须能够模拟外部系统上的事务。
- 在checkpoint的间隔期间内,必须能够开启一个事务并接受数据写入
- 在收到checkpoint完成通知之前,事务必须是一个“等待提交的状态”。在故障恢复的情况下,这可能需要一些时间。如果这个时候sink系统关闭事物(例如超时),那么未提交的数据就会丢失。
- sink任务必须能够在进程失败后恢复事务
- 提交事务必须是幂等操作
不同的Source和Sink的一致性保证

Flink-Kafka端到端的一致性保证
- 内部-----利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部状态的一致性
- source -----kafka consumer作为source,可以将偏移量保存下来,如果后续出现故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink -----kafka producer 作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
以kafka举例

- JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存
- 当checkpoint启动时,JobManager会将检查点分界线(barrier)注入到数据流,barrier在算子之间传递下去
- 当barrier到达时,算子会对当前的状态做一个快照,保存到状态后端(StateBackend),checkpoint机制可以保证内部的状态一致性
- 每个内部的transform任务遇到barrier时,都会把状态存到checkpoint里;sink任务首先是把数据写入到外部kafka,这些数据都是属于预提交的事务;遇到barrier时,把状态保存到状态后端,并开启新的预提交事务。
------此时checkpoint过程还未结束,只是算子任务的快照完成了
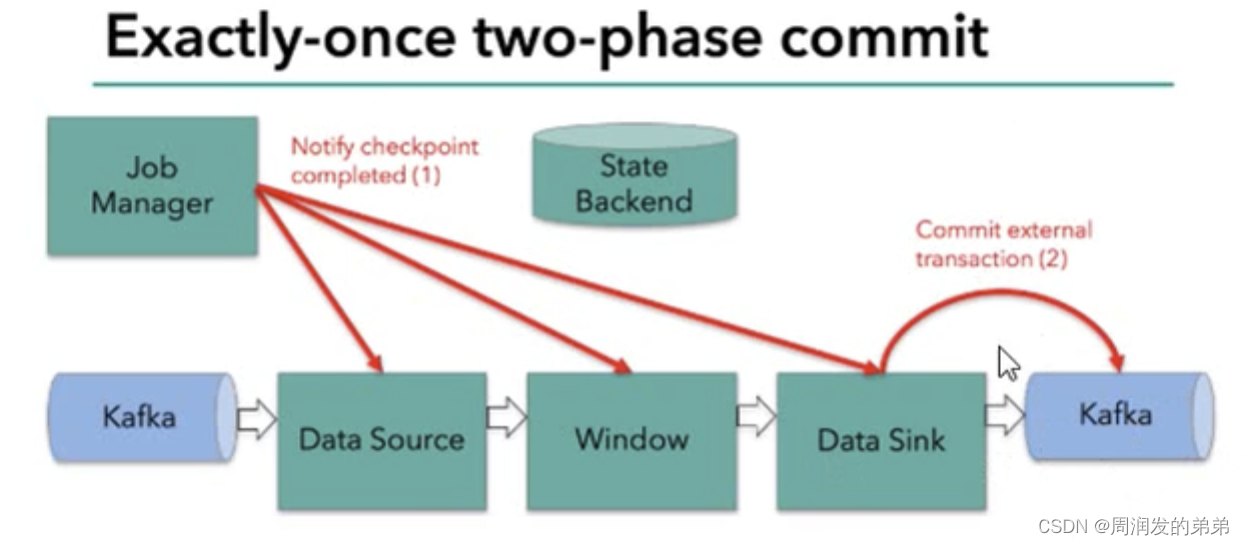
- 当所有算子任务的快照完成,也就是这次的checkpoint完成时,JobManager会向所有任务发送通知,确认这次checkpoint完成
- sink任务收到确认通知,正视提交之前的事务,kafka中的未确认数据改为“已确认”
这里也设计2PC的提交步骤,我们一起来列举一下
- 第一条数据来了之后,开启Kafka的事务,正常写入kafka分区日志但标记未提交,这就是“预提交”
- JobManager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知JobManager
- sink连接器收到barrier,保存当前状态,存入checkpoint,通知JobManager,并开始下一阶段的事务,用于提交下一个检查点的数据
- JobManager收到所有任务的通知,发出确认信息,标识checkpoint完成
- sink任务收到JobManager的确认消息,正视提交这段时间的数据
- 外部Kafka关闭事务,提交的数据可以正常消费了
















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











