







SegaBERT论文详解及翻译
(喜欢看小结的同学可以直接往下翻)
摘要
预训练模型取得了SOTA的结果在多种nlp任务中。它们中的大多数基于Transformer结构,使用token的序列输入位置来区分token。然而,句子索引和段落索引对于标识一篇文档中的token位置也同样重要。我们假设使用更好的位置信息做text encoder可以生成更好的篇章表示。为了证实这个观点,我们提出了一个segment-aware BERT,使用了段落索引,句子索引和token索引去代替了transformer中的token位置信息来进行embedding。我们预训练SegaBERT在mask之后的语言模型任务的BERT中,没有加入其他任务。实验结果展示出,在多个NLP任务上,我们的预训练模型比原始的BERT模型更好。
第一章 介绍
大型自然语言模型,经过大量文本数据训练,在迁移学习上展示了很大的潜力,并且在多个NLP任务中取得了SOTA结果。和像Skip-Gram和Glove这些传统的word embedding方法相比,预训练LM可以学到文本的表示并且可以作为文本的encoder在下游任务上进行fine-tuning,例如OpenAIGPT,BERT,XLNET和BART。因此,预训练LM已经成为了NLP的一个便捷方法。
大多数这些预训练模型使用了多层的Transformer和预训练的自监督方法。(例如MSM,mask语言模型)Transformer网络起初被用于seq2seq结构进行机器翻译,它的输入通常为一个句子。因此,初始化时区分token使用了输入序列的位置索引。
然而,在LM预训练背景下,不同段落和不同句子的输入通常为512到1024个token。虽然这些token位置embedding可以帮助transformer注意到token的顺序(通过输入序列区分token),句子顺序,段落顺序,句子级的token位置(个人理解:序列的token位置不一定是句子的token位置,输入不一定为一句),句子在段落中的位置,和段落在文章中的位置都被忽略了(隐藏的)。这些切分的信息对于语言理解来说是必要的,可以帮助文本encoder的生成更好的文本的表示。
因此,我们提出了一个新的关注切分(segment-aware)的BERT,将token在句中的索引,句子的索引和段落的索引都encode在了一起,用在预训练和fine-tuning阶段。我们预训练SegaBERT以MLM为目标,和BERT设置相同,除去了下一句的预测和其他任务的加入。根据实验结果,我们的预训练模型,SegaBERT,在生成语言理解和机器阅读理解上优于BERT结果(GLUE上1.17平均提升),在SQUAD上有1.14/1.54提升(匹配/F1值)。
第二章 模型
我们的SegaBERT是基于BERT结构的,是一个基于多层transformer的双向mask语言模型。对于长文本序列,SegaBERT调整了切分信息,如句子位置,段落位置,对于每个token去学习一个更好的文本表示。
原始的BERT使用了位置学习的embedding去编码一个token的位置信息。替代了使用全局token的索引,我们引入了三种形式的embedding,token索引,句子索引和段落索引,见图1。因此,在SegaBERT中,全局token位置被这三部分唯一确定: token在句中的索引,句子在段落中的索引和段落在长文本中的索引。

输入表示:输入x是一个token序列,有可能是一个或者多个句子或者段落。类似于BERT的输入表示,token t 的输入表示xt,通过对应位置的embedding进行求和,包括token embedding Et,token索引embedding Pt(t),句子索引embedding Ps(t),和段落索引Pp(t)。两种特殊tokne[cls]和[sep]被加入到文本序列中(第一个token之前和最后一个token之后)。和BERT相同,文本token通过词的切片(多头),最大长度为512.
encoder 结构:多层双向的Transformer encoder 将输入encode成文本表示。L层的Transformer,最后一层的token t 的隐向量Ht(L)用来作为文本表示。经过更大的切分体现在了输入表示,encoder有了一个更好的文本化能力。
训练目标: 和BERT类似,我们使用mask的LM作为我们的训练目标。另外的训练目标,下一句的预测,我们的模型没有使用到。
训练步骤:
对于SegaBERT-base,我们使用英文Wikipedia进行训练。对于SegaBERT-large,使用英文Wikipedia和BookCorpus。文本被预处理成类似于BERT的形式,token通过WordPiece变成了子token。对于每篇Wikipe,我们首先切分成Np个段落,所有段落I的token都被分配了相同的段落Embedding Pi(P)。每篇文章的段落索引从0开始。相似的,每个段落也被切成了Ns个句子,所有句子I的token被分配了相同的句子索引Pi(s)。每个段落的句子索引从0开始。第I个token的token序列embedding为Pi(t)。最大的段落索引,句子索引和token索引为50,100,256。
我们处理我们的实验包括两种模型大小:SegaBERT-base和SegaBERT-large。我们使用L表示Transformer层数,H表示隐层大小,A表示attention头的数量。
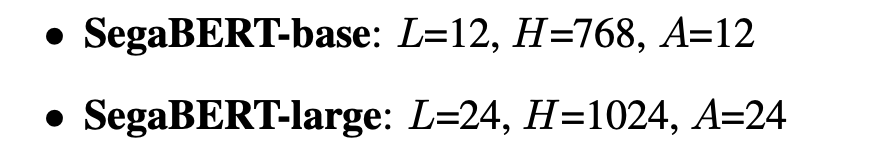
预训练使用了 16 个Tesla V100 GPU。我们SegaBERT-base训练了500K步,SegaBERT-large训练了1M步。对于优化器,我们选择了Adam,学习率为 1e-4,0.9,0.999,我们使用了warm-up,在1%的步骤,并且使用了线性衰减学习率。
(论文部分结束,实验结果见下面小结)
SegaBERT论文小结
目标:
更好的利用token的位置信息
结构:
模型结构类似于BERT,依然使用了Transformer结构,改进的地方在于token的embedding
BERT中使用了三种embedding
(token在序列中的位置embedding,segment的embedding,
token的自身embedding)
SegaBERT使用多种embedding来更好的表示位置
(即使用多个位置embedding来代替位置和segment的embedding)
SegaBERT使用了四种embedding,
(token在句中的位置embedding,
句子位置embedding,
段落位置embedding,
token的自身embedding)
训练目标:
类似于BERT的mask的LM,但是去掉了下句预测
输入:
输入可以输入一个或者多个句子,而不是BERT中的两个句子,最大序列长度同样为512
参数设置
embedding参数:
三个位置embedding从0开始,段落索引,句子索引,词索引最大值分别为50,100,256
结构参数:
SegaBERT-base:L,H,A相同
SegaBERT-large:A从16增加到了24(头的数量)
训练集:
SegaBERT-base:英文Wikipedia
SegaBERT-large:英文Wikipedia和BookCorpus
训练参数:
SegaBERT-base:500K steps
SegaBERT-large:1M steps
优化器:Adam,lr = 1e-4(1%warm-up,linear decay)
实验结果:
GLUE:
Large-model, 均值提升了1.2(82.1到83.3)
Base-model,均值提升1.0(80.9到81.9)
SQUAD v1.1:
Large-model,EM提升了1.14,F1提升了1.54(84.1到85.3,90.9到92.4)
(注:对比实验中XLNet可以达到89.7,95.1)
个人理解:
加入了更多也更详细的位置信息,另外large-model头的数量也有所增加,都可能会在效果上有所提升















 7542
7542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









