







Transformer论文详解,论文完整翻译(七)
第三章 模型结构(四)
3.3 位置相关的前馈神经网络
除了子层的attention之外,每个encoder和decoder层包括了一个全连接前馈网络,每个网络在每个位置中是单独并且相同的。网络包括了两个线性转换和一个ReLU激活函数。
3.4 Embedding和Softmax
与其他序列转换模型相似,我们使用学习embedding的方法将输入和输出token转换成d(model)维度的向量。我们也使用了通常的线性转换学习和softmax函数将decoder输出转换成预测下一个token的概率。在我们的模型中,我们对两个embedding层和pre-softmax线性转换层共享了相同的权重。在embedding层中过,我们将这些权重乘以了d(model)的平方根。
3.5位置Encoding
因为我们的模型不包含循环和卷积,为了使模型能够使用到序列的顺序,我们必须加入一些序列token的相对或者绝对位置信息。为此,我们将位置encoding加入到了输入的embedding,在encoder和decoder的最底层。位置encoing和embedding有着相同的维度d(model),因此两种可以相加。有许多种位置encoding的选择。
在本文中,我们使用了不同频率的sin和cos函数:
(个人理解,每个词有512个维度,偶数用sin,奇数用cos,最后每个维度用函数算一个值,512个值拼接起来)
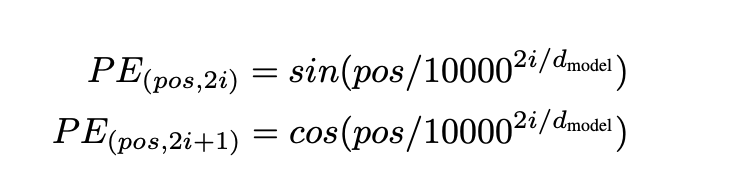
其中pos是位置,i是维度。因此,每个维度的位置encoding都是符合正弦的。几何级数的波长是从2 pai 到 10000乘 2 pai。我们选择了这个函数是因为我们假设它可以让模型更容易学习通过相关位置。因为对于任意一个固定的k,PE(pos+k)可以被线性表示成一个PE(pos)的线性函数。
我们也使用可学习的位置embedding做了实验去替代,发现两种方法结果基本相同。我们选择了正弦方法因为它可以允许模型在偶遇比训练更长的序列时可以推断。
(个人总结,请勿转载)















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









