






- 香港科技大学(广州)人工智能研究院
- 香港科技大学计算机科学与工程系 Contrastive Imitation Learning for Language-guided Multi-Task Robotic Manipulation
摘要
开发能够在自然语言指令和对复杂现实世界环境的视觉观察引导下,执行各种操作任务的机器人,仍然是机器人学领域的一项重大挑战。这类机器人智能体需要理解语言命令,并区分不同任务的要求。在这项工作中,我们提出了 Σ - agent,这是一种用于多任务机器人操作的端到端模仿学习智能体。Σ - agent 融入了对比模仿学习(contrastive IL)模块,以强化视觉 - 语言和当前 - 未来状态的表征。我们还引入了一种高效的多视图查询 Transformer(MVQ - Former),用于聚合具有代表性的语义信息。在 18 个 RLBench 任务的不同设置下,Σ - agent 相较于最先进的方法有显著改进,在 10 次和 100 次演示训练中,成功率分别比 RVT [1] 平均提高了 5.2% 和 5.9%。Σ - agent 在 5 个现实世界操作任务中,使用单一策略也实现了 62% 的成功率。代码将在论文被接受后发布。
关键词:对比模仿学习;多任务学习;机器人操作
Keywords: Contrastive Imitation Learning, Multi-task learning, Robotic Manipulation
1. 引言
机器人操作学习的最终目标之一,是使机器人能够根据人类给出的自然语言指令执行各种任务。这要求机器人能够理解并区分语言命令和视觉线索中的细微差异。然而,由于模拟环境中可用的奖励有限,且缺乏大量现实世界数据,训练机器人颇具难度。模仿学习是一种有效的离策略 offpolicy 方法,它避免了复杂的奖励设计和低效的智能体 - 环境交互 [2, 3, 4, 1]。在本文中,我们专注于 3D 物体操作的模仿学习。
以往的工作主要集中在提高机器人智能体的感知能力上,但忽略了区分不同指令和相关任务的能力发展。这些研究中的一部分致力于增强从 2D 预训练视觉表征到现实世界的迁移能力 [2, 7, 8, 9]。尽管如此,为了在模拟和现实世界环境中都保留几何细节,在指令引导的操作中,3D 视觉学习占据主导地位 [4, 3, 10, 1, 11, 12, 13, 14]。例如,C2FARM [4] 利用 3D 卷积神经网络,基于预先构建的体素空间聚合视觉表征。PerAct [3] 在 RGB - D 图像上构建体素化观测和离散动作空间,利用 Percevier [15] Transformer 对特征进行编码。此外,PolarNet [11] 直接对从 RGB - D 重建的点云特征进行编码,以预测动作。然而,这些工作并未探讨如何训练视觉表征,使其与语言特征对齐,并区分多个任务。
以往的方法 [2, 3, 16, 11, 1, 12, 13, 14] 可以概括为,通过行为克隆(BC)损失,监督智能体学习一个参数化策略![]() ,该策略基于根据目标策略收集的数据模仿目标策略
,该策略基于根据目标策略收集的数据模仿目标策略。策略学习遵循一种事实上的模式,即将视觉表征
、语言表征
和视觉 - 语言交互
映射到低级末端执行器动作。为了解决上述对齐问题,我们从对比强化学习(contrastive RL)方法 [17, 18, 19, 20] 中获得灵感,在原始的语言条件策略学习中引入了一种端到端的对比模仿学习(contrastive IL)策略。
强化学习(Reinforcement Learning,RL)是机器学习中的一个领域,强调智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励。对比强化学习(contrastive RL)是强化学习的一种变体方法,通过对比不同的状态、动作或轨迹来改进智能体的学习过程,增强其决策能力。论文中引用的参考文献 [17, 18, 19, 20],对对比强化学习进行了研究:
- 文献 [17]:B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov. Contrastive learning as goal - conditioned reinforcement learning. Advances in Neural Information Processing Systems, 35: 35603–35620, 2022. 提出将对比学习视为目标条件强化学习,把学习一个分类器来区分正未来状态和随机状态,作为目标条件强化学习中估计未来状态概率密度的一种方式,将对比学习与目标条件强化学习相联系,为对比强化学习提供了新的视角,使得智能体在学习过程中能更明确地朝着目标状态前进。
- 文献 [18]:C. Zheng, B. Eysenbach, H. Walke, P. Yin, K. Fang, R. Salakhutdinov, and S. Levine. Stabilizing contrastive RL: Techniques for offline goal reaching. arXiv preprint arXiv:2306.03346, 2023. 聚焦于离线目标达成任务中对比强化学习的稳定性问题,深入分析其内在机制,探索稳定离线策略学习的关键要素,提出相应的技术来稳定对比强化学习,使智能体在离线学习场景下也能更有效地达成目标。
- 文献 [19]:B. Eysenbach, R. Salakhutdinov, and S. Levine. C - learning: Learning to achieve goals via recursive classification. In International Conference on Learning Representations, 2020. 提出 C - learning 方法,通过递归分类来学习实现目标,将对比学习融入到目标实现的学习过程中,智能体在每一步决策时,通过对比不同分类结果来选择更有利于实现目标的动作,为对比强化学习的算法设计提供了新的思路。
- 文献 [20]:R. Yang, Y. Lu, W. Li, H. Sun, M. Fang, Y. Du, X. Li, L. Han, and C. Zhang. Rethinking goal - conditioned supervised learning and its connection to offline RL. In International Conference on Learning Representations, 2021. 重新思考目标条件监督学习及其与离线强化学习的联系,从理论上深入探讨了目标条件学习与离线强化学习的关系,为对比强化学习在不同学习范式下的应用和融合提供了理论基础,有助于智能体更好地利用监督学习的知识进行强化学习,提高学习效率和性能。
具体而言,除了使用 BC 损失监督表征和策略的联合学习外,我们还集成了一个额外的对比 IL 分支,以监督特征提取 和交互
(图 2(b))。对比对齐通过最小化正样本对之间的距离,有助于区分多任务表征,如图 1 所示。
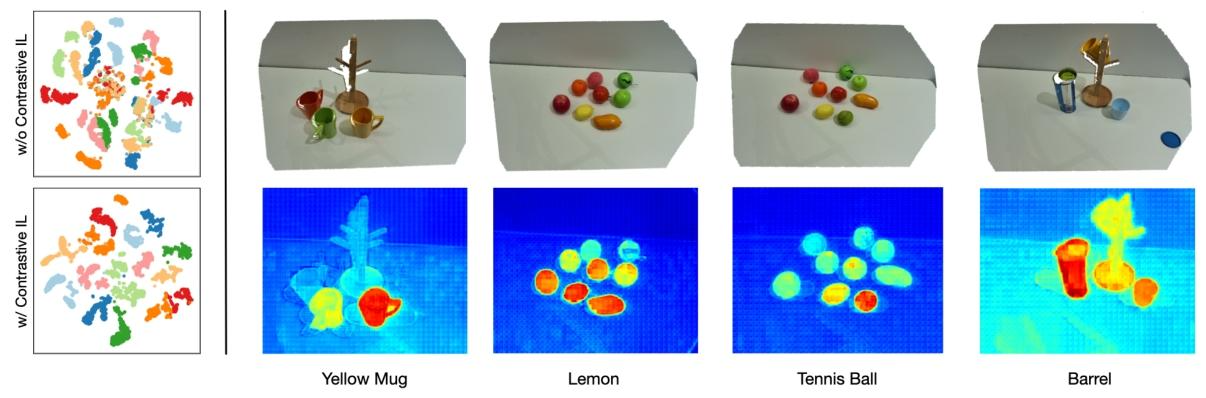
图1:左图:使用t-SNE[5]对有无对比模仿学习(contrastive IL)的多任务表征学习进行可视化,采用对比模仿学习时,属于不同任务的特征分离更为明显。右图:利用Grad-CAM[6]对感兴趣区域进行可视化,展示了精确的物体级理解。
t-SNE(t-Distributed Stochastic Neighbor Embedding)即 t 分布随机邻域嵌入,是一种用于数据降维和可视化的强大技术,在机器学习和数据挖掘领域应用广泛,尤其适用于高维数据的可视化分析。其核心原理与应用场景如下:
- 原理:基于数据点之间的相似性,将高维空间中的数据点映射到低维空间(通常是二维或三维),同时尽可能保留数据点之间的相对位置关系。它通过构建高维数据点之间的概率分布,使得相似的数据点在分布上更接近,然后在低维空间中找到一个近似的分布,让低维表示能反映高维数据的结构。例如,在处理图像数据时,t-SNE 可以将图像的高维特征向量(如经过神经网络提取的特征)映射到二维平面上,使得相似内容的图像在二维平面上聚集在一起。
- 应用场景:在多任务表征学习的研究中,可用来可视化不同任务的特征分布。如论文《用于语言引导的多任务机器人操作的对比模仿学习》中,通过 t-SNE 可视化发现,使用对比模仿学习时,不同任务的特征在低维空间中分离得更明显,这有助于理解对比模仿学习对任务特征区分能力的提升作用;在图像分类任务里,t-SNE 能帮助研究人员直观地观察不同类别图像的特征分布,判断模型对不同类别特征的学习效果;在文本分析中,t-SNE 可将文本的高维词向量或文档向量映射到低维空间,展示不同主题文本的分布情况,辅助文本聚类和主题发现
Grad-CAM(Gradient-weighted Class Activation Mapping),即梯度加权类激活映射,是一种用于解释深度神经网络决策依据的技术。它通过生成热力图,直观呈现图像中对模型预测结果具有关键影响的区域,揭示模型在做出决策时重点关注的图像部分,辅助理解模型的决策过程。
1. **核心原理**:基于神经网络中卷积层的特征图和梯度信息进行计算。在模型对输入图像进行预测时,首先获取特定类别的输出分数,然后计算该分数对卷积层特征图的梯度。这些梯度反映了特征图中每个元素对预测分数的重要性程度。通过对梯度在空间维度上进行全局平均池化,得到每个通道的重要性权重。将这些权重与相应的特征图进行加权求和,再经过ReLU激活函数处理,就生成了Grad-CAM热力图。热力图中颜色越深的区域,表明该区域对模型做出当前预测的贡献越大。
2. **应用领域**:在计算机视觉领域,常用于图像分类、目标检测和语义分割等任务的模型解释。在图像分类任务中,它能清晰展示模型是依据图像中的哪些部分做出分类决策,例如判断一张包含猫和狗的图片时,Grad-CAM热力图可以指出模型主要关注的是猫或狗的哪些身体部位;在医学图像分析中,帮助医生理解模型对医学影像(如X光、CT扫描)的诊断依据,确定模型关注的病变区域,辅助疾病诊断;在自动驾驶领域,用于解释目标检测模型对道路场景中车辆、行人等目标的识别和定位依据,有助于提升自动驾驶系统的安全性和可靠性。在论文《用于语言引导的多任务机器人操作的对比模仿学习》中,利用Grad-CAM可视化感兴趣区域,展示了模型精确的物体级理解能力,即模型能够准确关注到与任务相关的物体区域,为研究模型对任务的理解和执行机制提供了直观依据。
基于对比 IL,我们提出了一种端到端训练的语言条件多任务智能体,用于完成 6 自由度操作,称为用于多任务操作智能体的对比模仿学习(SIGMA - agent,简称为 Σ - agent)。Σ - agent 遵循最先进的基线模型 RVT [1],并利用从 RGB - D 重建重新渲染的虚拟图像来明确表示视觉信息。我们提出了一种多视图查询 Transformer(MVQ - Former)[21, 22, 23],以最小化标记数量,实现高效的对比 IL。Σ - agent 框架为如何将对比学习融入现有的模仿学习方法提供了指导,同时推理过程保持不变。
在 RLBench [24] 和现实世界任务上的实验证明了 Σ - agent 的有效性。RLBench 上的结果表明,在为 18 个任务(有 249 个变体)使用单一策略的设置下,Σ - agent 在 10 次演示(平均提高 5.2%)和 100 次演示(平均提高 5.9%)训练中,均显著优于先前的智能体。此外,我们将对比 IL 模块集成到现有方法(PolarNet [11]、RVT [1])中,并在其他模拟环境(Ravens [25])中对 Σ - agent 进行实验。显著的改进表明了我们的方法在各种模型和环境中的普遍适用性。Σ - agent 在现实世界机器人实验中,针对 5 个任务使用单一策略,平均也实现了 62% 的多任务成功率。
2. 相关工作
2.1 语言条件下的机器人操作
语言条件下的机器人操作,由于其在人机交互中的广泛适用性,已成为机器人学领域的一个关键研究分支 [26, 2, 3, 1, 11, 16, 12, 13, 14, 27, 28, 29, 30]。先前的许多研究都深入探讨了基于视觉的表征,以及在策略学习中视觉 - 语言交互的策略。例如,RT - 1 [31] 通过预训练的 FiLM EfficientNet 模型对多模态标记进行编码,并将它们输入到 Transformer 中进行多模态信息聚合。后来的版本 RT - 2 [32] 利用大语言模型(LLMs)的自回归生成能力,将视觉标记投影到语言空间,并使用 LLMs 直接生成动作。人们精心策划了各种基准测试,以对语言条件下的操作进行评估 [24, 25, 33, 34, 35, 36]。在本文中,我们主要关注 RLBench [24],它提供了数百个具有挑战性的任务和多样的变体,涵盖物体的姿态、形状、颜色、大小和类别,用于基于 RGB - D 相机评估智能体。
在这个具有挑战性的基准测试中,人们付出了诸多努力。C2FARM [4]、PerAct [3] 和 GNFactor [14] 利用 3D 体素表征进行策略学习。C2FARM [4] 以粗到细的方式,在两个体素化级别上检测动作。PerAct 利用 Perceiver 网络 [15] 对 3D 体素特征进行编码,以预测下一个关键帧的位置,其体素分辨率比 C2FARM [4] 更低。为了优化对 3D 场景几何结构的理解,GNFactor [14] 结合了一个广义神经特征场模块,基于 PerAct [3] 将 2D 语义特征提炼到神经辐射场(NeRFs)[37] 中。除了体素化特征,基于 3D 点云表征的策略学习也受到了广泛关注,如 PolarNet [11]、Act3D [12] 和 ChainedDiffuser [13]。PolarNet 在由 RGB - D 构建的 3D 点云上训练智能体,并采用预训练的 PointNext [38] 来提取逐点特征。Act3D [12] 和 ChainedDiffuser [13] 都采用粗到细的采样策略,在空间中选择 3D 点,并通过相对空间注意力对其进行特征化,而 ChainedDiffuser [13] 则使用扩散模型合成末端执行器轨迹。我们的工作遵循 RVT [1],它从重建的 3D 点云重新渲染虚拟视图图像,并使用 Transformer 网络对图像进行处理。
2.2 强化学习中的对比学习
大量先前的工作将表征学习目标与强化学习目标相结合 [39, 40, 41, 42, 43, 44]。在这些表征学习方法中,对比学习受到了极大的关注 [40, 41, 45, 46, 43, 47]。最近,将表征学习和强化学习目标统一的范式,已成为强化学习领域的一个研究热点 [19, 45, 18, 48, 49, 50, 51]。例如,C - learning [19] 将目标条件强化学习视为估计未来状态的概率密度,学习一个分类器以区分正未来状态和随机状态。Eysenbach 等人 [17] 证明,对比表征学习可以用作值函数估计,将学习到的表征与奖励最大化联系起来。Zheng 等人 [18] 提出在离线目标达成任务中稳定对比强化学习,深入分析了对比强化学习的内在机制,以探索稳定离线策略学习的要素。需要注意的是,上述对比强化学习方法主要关注通过奖励更新的强化学习。与我们的工作最相似的之一是 GRIF [52],它通过对比学习学习与轨迹中收集的转换对齐的语言表征。然而,我们的对比 IL 在三个方面与 GRIF [52] 不同。第一,对比 IL 是一种端到端的训练范式,而 GRIF [52] 将对比表征预训练和策略学习解耦为两个阶段。第二,我们本文针对的是 3D 多任务设置,而 GRIF [52] 使用 RGB 图像和单策略训练。最后,GRIF [52] 对(状态,目标)对和语言指令进行对比学习。对于对比 IL,我们进行对比学习以优化特征提取和视觉 - 语言特征交互。附录 D 中提供了更多相关工作。
GRIF(Goal Representations for Instruction Following: A Semi-supervised Language Interface to Control)是一种用于指令跟随的目标表征方法,旨在通过对比学习学习与轨迹中收集的转换对齐的语言表征,为控制任务提供一种半监督的语言接口,使智能体能够更好地理解和执行语言指令。在论文《用于语言引导的多任务机器人操作的对比模仿学习》中,GRIF 作为相关研究被提及,用于与文中提出的对比模仿学习(contrastive IL)进行对比分析
- 学习方式:GRIF 将对比表征预训练和策略学习解耦为两个阶段,先进行对比表征预训练,学习与收集的轨迹转换对齐的语言表征,之后再进行策略学习;而文中的 contrastive IL 是一种端到端的训练范式,在训练策略的同时优化特征提取和视觉 - 语言特征交互。
- 应用场景:GRIF 利用 RGB 图像和单策略训练,适用于特定的基于 RGB 图像的任务场景;而文中研究聚焦于 3D 多任务设置,处理更复杂的 3D 环境下的多任务操作。
- 对比学习对象:GRIF 对(状态,目标)对和语言指令进行对比学习;contrastive IL 则针对特征提取和视觉 - 语言特征交互进行对比学习,以优化多任务机器人操作中的特征表示和任务区分能力。
3. 方法
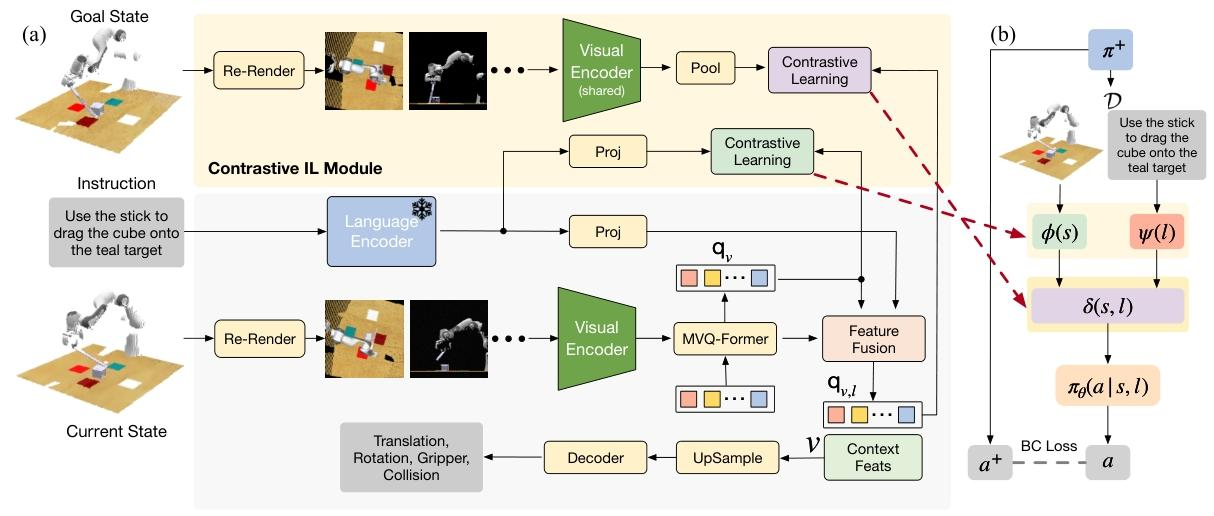
图 2 展示了 Σ - agent 设计的概述(图 2(a))以及与先前语言引导模仿学习范式的差异(图 2(b))。在本节中,我们将介绍 Σ - agent 的组件。附录 C 中提供了关于 Σ - agent 的更多详细信息。
图2:(a) Σ - agent的流程。(b) 语言条件多任务操作模仿学习的概述,其中学习表征ϕ、ψ、δ以及策略网络θ,以便策略
模仿目标策略$
$。对比模仿学习(contrastive IL)模块旨在优化视觉表征ϕ(视觉编码器)和视觉 - 语言联合表征s(多视图查询Transformer(MVQ - Former)和特征融合)。请注意,对比模仿学习模块仅用于智能体的训练,对推理过程没有影响。对比模仿学习模块中用于未来状态的视觉编码器与当前状态的视觉编码器共享参数。语言编码器在训练过程中保持冻结。
3.1 预备知识
我们假设一个由状态 \(\)、动作 \(
\) 和语言指令
定义的语言条件马尔可夫决策过程(MDP)。\(S\)、\(A\) 分别是状态和动作空间,\(L\) 表示语言指令集。目标是学习一个策略
![]() ,以最大化预测动作的预期奖励。遵循先前的工作 [3],我们利用行为克隆在没有特定奖励的情况下最大化 Q 函数。因此,策略学习的目标可以表示为:
,以最大化预测动作的预期奖励。遵循先前的工作 [3],我们利用行为克隆在没有特定奖励的情况下最大化 Q 函数。因此,策略学习的目标可以表示为:
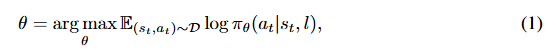
其中,\(\theta\) 表示策略网络的参数,\(\) 表示为行为克隆收集的演示中的转换 transitions 。请注意,
是从专家策略 \(
\) 中采样得到的,我们训练 \(\theta\) 以使 \(
\) 模仿
。在本文中,状态 \(s_{t}\) 包括来自前方、左肩、右肩和手腕位置对齐的 RGB 和深度图像。我们遵循 RVT [1],采用从 RGB - D 输入重新渲染的虚拟图像输入到模型中。动作空间 \(A\) 由笛卡尔坐标中的平移 \(a_{t}^{trans } \in \mathbb{R}^{3}\)、四元数表示的旋转 \(
\)、夹爪打开状态 \(
\) 和碰撞状态 \(
\) 组成。
“previous work [3]” 指的是参考文献 [3] 中提及的研究。这一引用出自论文《Perceiver-Actor: A multi-task transformer for robotic manipulation》,作者是 M. Shridhar、L. Manuelli 和 D. Fox,发表于 2022 年的 CoRL 会议。该研究聚焦于机器人操作领域,提出了 Perceiver - Actor 这一用于机器人操作的多任务 Transformer 模型,为后续相关研究奠定了基础,在本文中有多处被参考借鉴。
- 策略学习方式:本文在设定策略学习目标时参考了 [3] 的做法,利用行为克隆来最大化 Q 函数,以学习机器人操作策略。在复杂的机器人操作任务中,通过模仿专家演示数据来优化策略,避免了复杂的奖励设计过程。
- 数据处理与增强:在实验环节,本文的模拟实验部分借鉴了 [3] 的数据处理和增强方式。如在 RLBench 实验中,像 [3] 一样从提取的关键帧的重放缓冲区进行行为克隆,而非使用所有帧;并且采用了相似的平移和旋转数据增强方法,在训练过程中对数据进行扰动,提升模型的泛化能力。
- 动作预测与模型评估:在动作预测方面,本文参考了 [3] 的思路,将旋转预测转换为分类问题,并利用交叉熵损失等进行训练。在模型评估时,也借鉴了 [3] 在 RLBench 上的实验设置和评估指标,通过在多个任务上测试模型的成功率来衡量性能。
3.2 视觉和语言编码器
我们按照 RVT [1] 的方法,从 5 个立方视角(前方、左侧、右侧、后方和顶部)获取重新渲染的虚拟图像。每个视图图像包含 RGB、深度和 \((x, y, z)\) 坐标通道。视觉编码器由一个补丁嵌入层和一个两层的自注意力 Transformer 组成。我们将图像分割成 \(20×20\) 的补丁,并利用一个 MLP 层对补丁标记的嵌入进行投影,以进行自注意力计算。对于自注意力 Transformer,每个补丁标记仅关注同一虚拟视图图像中的其他标记,目的是聚合来自同一视图的信息。视觉编码器采用归一化初始化,从头开始训练。
对于语言编码器,我们遵循先前的工作 [3, 16, 11, 1, 12],使用来自 CLIP [53] 的预训练语言编码器,以进行公平比较。在训练过程中,语言编码器保持冻结。然后,通过一个可训练的 MLP 对编码器输出的语言标记嵌入进行投影,以便与视觉标记进行交叉注意力计算。
3.3 多视图查询 Transformer(MVQ - Former)
利用从视觉编码器中提取的视觉特征,我们遵循查询 query Transformer [23, 53, 21, 22] 预定义一组可学习的查询 query 。
下面是对参考文献 [23, 53, 21, 22] 的具体分析:
- 文献 [23]:N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213– 229. Springer, 2020. 该文献提出了基于 Transformer 的端到端目标检测方法,其中可能涉及到 query Transformer 相关的机制,通过可学习的查询来定位和识别目标物体,为 query Transformer 在计算机视觉领域的应用提供了重要参考。
- 文献 [53]:A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 主要研究从自然语言监督中学习可迁移的视觉模型,可能在视觉和语言信息交互过程中使用了 query Transformer 技术,以实现更有效的信息提取和模型训练。
- 文献 [21]:J. Li, D. Li, C. Xiong, and S. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022. 提出了用于统一视觉 - 语言理解和生成的预训练模型 Blip,query Transformer 可能在其视觉和语言特征融合、信息检索等环节发挥作用,帮助模型更好地理解和处理跨模态信息。
- 文献 [22]:J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023. 是对 Blip 的进一步改进,延续了跨模态学习的思路,query Transformer 可能在其优化的视觉 - 语言交互机制中起到关键作用,提升模型在多模态任务中的性能。
这些查询由对比 IL 模块使用,通过减少原始视觉标记的数量来最小化计算复杂度。可学习查询的数量设置为 5,每个虚拟视图对应一个,用于聚合视图内的信息。图 2 中的 MVQ - Former 由两个交叉注意力层组成,其中查询标记共同关注提取的视觉特征。我们将 MVQ - Former 产生的查询表示为 。
查询标记、视觉标记和语言标记随后被连接在一起,并输入到 4 个自注意力层进行特征融合。在此过程中,查询与视觉和语言特征充分交互,此时的查询被命名为 。\(q_{v}\) 和 \(q_{v, l}\) 将用于后续描述的对比 IL。最后,自注意力层之后的上下文特征(表示为 v)被输入到解码器中进行动作预测。
3.4 对比模仿学习
对于由语言指令条件控制的多任务智能体,我们提出关键问题:对于精确、细粒度的控制而言,有效的任务表征是什么?有两个因素至关重要。第一,智能体需要具有判别力的特征,以准确感知当前状态。第二,对齐任务和语言表征,对于智能体理解任务之间的相关性并进行区分至关重要。
学习目标:为此,我们引入对比学习来优化特征编码,并对齐视觉 - 语言嵌入。受对比强化学习 [19, 17, 20, 18] 的启发,我们提议将对比表征学习集成到当前的模仿学习框架中,以端到端的方式训练策略。
对比 IL 包括状态 - 语言和(状态,语言) - 目标
对比学习,以优化特征提取和交互,如图 2 所示。对于
,我们将相似性函数定义为
(
:温度参数),其中 \(\phi\) 和 \(\psi\) 分别是状态和语言指令的表征。状态和语言指令之间的对比 IL 目标为:
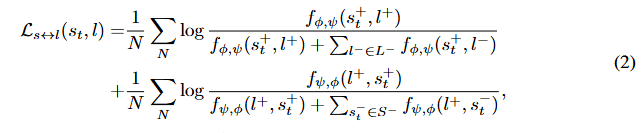
其中, 是训练中的批次大小,
,
![]() 表示相应的正状态和指令。
表示相应的正状态和指令。 和
分别代表当前批次中的所有负语言和状态样本。从本质上讲,这促使网络通过在联合嵌入空间中对齐状态和语言对,学习更具判别力的表征。
对于 ,我们从
中随机采样未来状态作为目标 \(g\),应用网络 \(\phi\) 对目标表征进行编码。\(\delta\) 对
的联合表征进行编码。负样本来自同一批次中的其他任务。与公式 2 类似,我们将目标与状态、语言对之间的对比训练损失表示为:
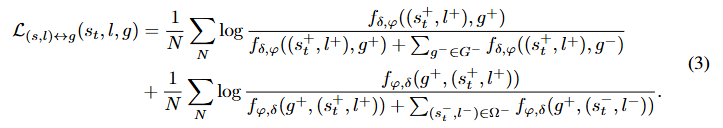
旨在优化视觉 - 语言交互\(\delta\)的表征,这对于智能体理解视觉和语言信息至关重要。\(G^{-}\)和\(\Omega^{-}\)表示当前批次中目标状态和\((s_{t}, l)\)的负样本空间。基于\(\mathcal{L}_{s \leftrightarrow l}\)和\(\mathcal{L}_{(s, l) \leftrightarrow g}\),我们将公式 1 中的学习目标重新表述为:
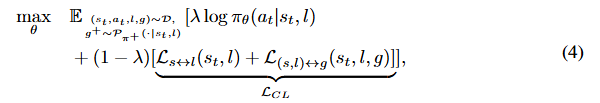
其中是系数。正目标状态\(
\)符合目标策略\(
\)的转移概率
。更多讨论可在附录 C.2 中找到。
模块细节
对于语言和状态观察之间的对比训练,我们按照 CLIP [53] 的做法,选择最后一个标记(即 [EOS])作为整个文本的特征表示,然后将其线性投影到多模态嵌入空间。如图 2 (a) 所示,查询沿着标记 token 维度进行投影,以聚合具有代表性的视觉特征。然后,根据公式 2,视觉标记和文本标记在联合嵌入空间中进行训练以实现对齐。
对于目标与状态 - 语言的对比训练,我们使用轨迹中的下一个状态作为目标状态。目标状态的视觉编码器与当前状态的视觉编码器共享相同的骨干网络参数,如图 2 所示。因此,公式 3 中的等于公式 2 中的
。查询
包含当前状态的视觉特征和语言特征,将其投影后与平均池化的目标特征进行对比训练,这个过程符合公式 3。请注意,对比模仿学习模块旨在在训练过程中增强表征,但在推理过程中不启用。
4. 实验
4.1 模拟实验
- 模拟设置:RLBench 是一个基于 CoppelaSim [54] 和 PyRep [55] 构建的机器人操作基准测试平台。我们遵循 PerAct [3] 和 RVT [1] 的协议,在 RLBench 的 18 个任务上对模型进行测试。这些任务包括拾取和放置、拧灯泡、打开抽屉等,均通过控制配备平行夹爪的 Franka Panda 机器人来完成。附录 A.1 中提供了 18 个任务及其变体的详细信息。输入的 RGB - D 观测数据来自位于前方、左肩、右肩和手腕位置的四个 RGB - D 摄像头。除非另有说明,RLBench 实验的输入分辨率为 128×128。
- 实现细节:我们按照 RVT [1] 的方法,对从 3D 点云重建的立方体视角重渲染图像进行训练。我们使用每个任务 10 次和 100 次演示对 Σ - agent 进行评估训练。遵循先前的工作 [24, 56, 3, 1],我们对提取的关键帧的重放缓冲区进行行为克隆,而不是对情节中的所有帧进行操作。与 PerAct [3] 类似,我们在训练过程中采用平移和旋转变换增强,在 ±0.125m 的范围内随机扰动点云进行平移,并沿 z 轴在 ±45° 范围内旋转点云。在训练方案方面,我们使用 96 的批量大小和 9.6×\(10^{-4}\)的初始学习率对 Σ - agent 进行 25K 步训练。采用 LAMB [57] 优化器,使用余弦退火学习率衰减和 2K 步热身。训练在 8×NVIDIA A6000 GPU 上进行,大约需要 22 小时。Σ - agent 在所有 18 个任务及其变体上进行评估。将初始观测值提供给智能体,智能体通过观测 - 动作循环探索以达到最终状态。智能体达到最终状态得分为 100,失败得分为 0,没有部分得分。遵循 PerAct [3],我们报告每个任务 25 个情节的平均成功率以及所有 18 个任务的平均成功率。
- 与最先进方法的比较:由于基于采样的运动规划器的随机性,我们对每个任务在相同的 25 个情节上对 Σ - agent 进行三次评估,并报告平均结果。评估包括两种设置,每个任务使用 10 次或 100 次演示进行训练。我们重新实现了 PolarNet(100 次演示)和 RVT(10 次演示)的结果,因为原始论文中缺少这些数据。其他结果取自相关文献。从表 1 中可以看出,Σ - agent 在 10 次和 100 次演示的训练中,均大幅优于先前的方法,在 18 个任务上的平均成功率分别提高了 5.2% 和 5.9%。在特定任务中,我们的 Σ - agent 在 10 次和 100 次演示设置下,在 18 个任务中的 13 个任务上达到了最先进的性能。
| 方法 | 平均成功率 | 训练时间 |
|---|---|---|
| Act3D[12] | - | 65.1 ~5.5 天 |
| ChainedDiffuser[13] | - | 66.1 ~4.5 天 |
| Σ - agent | - | 68.4~22 小时 |
此外,我们将 Σ - agent 与两个最先进的模型 Act3D [12] 和 ChainedDiffuser [13] 进行比较,这两个模型在 256×256 的输入分辨率下进行训练,并对每个任务在 100 个情节上进行测试。如表 2 所示,我们的 Σ - agent 分别比这两种方法高出 3.3% 和 2.3%,且训练时间缩短了 5 倍。附录 A.2 中展示了 Σ - agent 在其他模拟环境中的结果。
- 基线模型的对比模仿学习:为了验证对比 IL 的有效性,我们将对比 IL 模块集成到其他基线模型中。我们选择 PolarNet [11] 和 RVT [1] 作为基线,以展示点云表示和 3D 重渲染图像表示的改进。主要网络和推理管道保持不变,仅加入对比 IL 模块,在训练过程中参数数量的增加可以忽略不计。如表 3 所示,对比 IL 模块使 PolarNet [11] 和 RVT [1] 在 18 个任务上的平均成功率分别提高了 2.8% 和 1.8%。具体来说,大多数任务的性能都有所提升(18 个任务中有 13 个和 11 个),最大提升幅度达到 13.9%。这些改进表明:第一,我们提出的对比模仿学习可以在多个模型中迁移。第二,这种学习方法对 3D 重渲染图像(RVT [1])和点云表示(PolarNet [11])均有效。
- 未来状态和语言对比学习的消融实验:我们对未来状态和语言对比 IL 的影响进行消融实验,结果如图 3(a)所示。从结果中我们总结出两个关键点:(1)当前观测与语言和目标的对比学习都能提高性能。(2)当前观测与语言指令之间的对比学习加快了智能体训练的收敛速度,在训练早期就实现了更高的性能。这突出了我们提出的对比 IL 能够更好地对齐多模态特征。
- 对比 IL 中批量大小的影响:对比训练对批量大小的规模很敏感 [58, 53]。我们改变批量大小,结果如图 3(b)所示。可以得出结论,增大批量大小对提升智能体的性能至关重要,因为它可以包含更多的负样本。
- 系数 λ 的消融实验:在公式 4 中,λ 是调节对比 IL 和行为克隆之间关系的超参数。我们将 λ 的取值范围在 [0, 1] 之间变化,以找到最优值。如图 3(c)所示,我们使用五个不同的 λ 值训练智能体,观察到结果略有不同。我们选择 λ = 0.5 进行智能体训练,因为它是相对最优的值。
4.2 真实世界实验
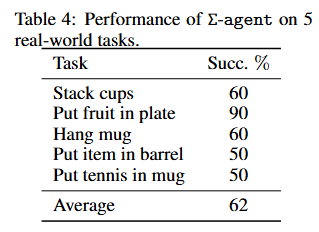
我们在一个 6 自由度的 UR5 机械臂真实机器人上进行实验。Σ - agent 在 5 个真实世界任务上进行验证,这些任务总共包括 9 个变体。对于每个任务,我们收集 10 个人类演示,并使用所有任务演示从头开始用单一策略训练 Σ - agent。附录 B 中提供了真实世界实验设置和数据收集的详细信息。表 4 展示了真实世界实验的结果。我们对每个任务测试 Σ - agent 10 个情节,它在所有任务上的平均成功率达到 62%。分析失败的原因:第一,单个前视摄像头的限制无法为需要瞄准的任务(如 “将网球放入桶中” 和 “将网球放入杯子中”)提供精确的视觉信息。第二,在抓取过程中,不完善的抓取姿势导致物体平移或旋转,加剧了碰撞问题。未来,我们计划在手腕位置添加一个额外的 RGB - D 摄像头,以提供第一人称视角。此外,将物体姿态估计模型集成到 Σ - agent 中,将改善抓取姿势并避免碰撞。真实世界实验的视频可在补充材料中找到。
5. 结论与局限性
在这项工作中,我们提出了对比 IL,这是一种用于语言引导的多任务 3D 物体操作的即插即用模仿学习策略。对比 IL 通过集成对比 IL 模块优化了原始的模仿学习框架,以改进特征提取和交互。基于对比 IL,我们设计了端到端模仿学习智能体 Σ - agent,它利用 RGB - D 输入的重渲染虚拟图像。Σ - agent 在模拟环境和真实世界实验中均有效且高效。然而,我们也发现了一些存在的局限性。第一,RLBench 模拟环境和真实世界环境之间的差异很大。这种差异导致了模拟到现实的迁移失败,在一定程度上限制了模拟训练的意义。第二,基于行为克隆训练的策略需要收集人类演示,这在真实世界实验中尤为复杂。因此,策略学习限制了智能体在大规模不同任务中的工作。
附录 C:其他模型细节
C.1 动作预测
基于特征融合后的上下文特征 \(v\),解码器输出 6 自由度的末端执行器位姿(3 自由度用于平移,3 自由度用于旋转)、夹爪状态(打开或关闭),以及一个用于指示运动规划器是否允许碰撞的二进制值。我们简单地使用一个 2D 卷积层和双线性上采样,对编码后的上下文特征进行解码和上采样,使其恢复到原始渲染图像的大小(220×220)。遵循 RVT [1] 的方法,Σ - agent 预测 5 个虚拟视图的热图,这些热图将被投影回 3D 空间,以预测机器人工作空间中的逐点得分。然后,末端执行器的平移由得分最高的 3D 点确定。旋转、夹爪状态和碰撞指示符则基于最大池化后的图像特征,以及由热图加权的图像特征之和进行预测。假设 \(h\) 是预测的视图热图,用于预测旋转、夹爪状态和碰撞指示符的特征可表示为:
其中, 和
分别表示在标记的空间维度上的求和与最大池化操作。
表示上下文特征与热图之间的逐元素乘法。然后,遵循 PerAct [3] 和 RVT [1] 的方法,我们使用欧拉角表示旋转,并将每个角度离散化为 5° 的区间,用于 \(dx\)、\(dy\)、\(dz\)。在这种情况下,旋转预测被转化为一个分类问题,智能体被训练将角度分类到 216 个类别中
。因此,我们使用一个线性层将特征 \(f\) 投影到一个 220 维的空间中。在这个空间中,216 维用于旋转预测,另外 2 维分别用于二进制夹爪状态预测和二进制碰撞状态预测。对于动作预测的训练损失,我们对平移和旋转使用交叉熵损失,对夹爪状态和碰撞状态使用二分类损失。除了上述损失外,还使用对比损失来监督对比 IL 模块中的表征学习。
C.2 Q 函数分析
与 PerAct [3] 相同,我们对特征进行解码,以估计动作值的 Q 函数,即 。
等同于在折扣状态占用度量下,状态
和指令
转移到下一个状态
的转移概率
[19, 17, 20]:
![]()
当公式 3 中的 是 \(
\) 的下一个状态时,
最大化了
与
之间的相似度。换句话说,训练
的目的是通过最小化对应对
之间的距离,同时最大化负样本对之间的距离,来最大化在语言指令 \(l\) 下从
到
的转移概率。因此,使用
训练
有助于最大化
,从而最大化
。\(f_{\delta, \varphi}\) 可以作为一个额外的评判函数,在表征学习层面帮助策略 \(\pi\) 模仿目标策略 \(\pi^{+}\)。
“under the discounted state occupancy measure [19, 17, 20]”意思是“在折扣状态占用度量下(相关理论见参考文献[19, 17, 20] )”。
- 核心概念:在强化学习里,智能体在环境中不断转换状态。状态占用度量表示智能体在每个状态上花费的时间占总时间的比例。折扣状态占用度量则进一步引入折扣因子,对未来状态的价值进行折扣计算。因为在实际情况中,智能体更关注近期的奖励,未来的奖励对当前决策的影响会随着时间推移而减小。折扣因子通常是介于 0 到 1 之间的数值,它决定了未来奖励的重要程度。比如,折扣因子为 0.9,意味着未来某一时刻的奖励,在当前的价值是其原始价值的 0.9 倍。随着时间推移,折扣后的价值会越来越小。
- 公式关联:在论文中公式 “
” 在折扣状态占用度量的框架下成立。该公式将 Q 函数等同于状态转移概率,表明在这种度量下,Q 函数用于评估在当前状态\(s_{t}\)和语言指令\(l\)下,采取动作\(a_{t}\)转移到下一状态\(s_{t+1}\)的可能性,而这个评估过程考虑了折扣状态占用度量,即对未来状态的价值进行了折扣处理。
- 文献 [19]
- 基本信息:“C - learning: Learning to achieve goals via recursive classification”,发表于 2020 年的 International Conference on Learning Representations。作者是 B. Eysenbach、R. Salakhutdinov 和 S. Levine。
- 核心内容:提出 C - learning 方法,将目标达成学习转化为递归分类问题。该方法基于对比学习思想,通过递归地对不同状态和动作进行分类,引导智能体学习实现目标的策略。在复杂的机器人操作任务中,智能体可以通过 C - learning 不断对比当前状态与目标状态,以及不同动作可能带来的状态变化,逐步学习到最优策略。这种方法将对比学习融入到目标实现的学习过程中,为强化学习算法设计提供了新的思路。
- 与论文关联:为论文中强化学习相关理论和方法提供基础。在折扣状态占用度量方面,C - learning 的递归分类过程可以看作是在不同状态下进行决策的过程,而折扣状态占用度量则为这种决策提供了一种衡量不同状态价值的方式。通过考虑折扣状态占用度量,C - learning 能够更好地平衡当前决策对未来状态的影响,使智能体在学习过程中更有效地朝着目标前进。
- 文献 [17]
- 基本信息:“Contrastive learning as goal - conditioned reinforcement learning”,发表于 2022 年的 Advances in Neural Information Processing Systems。作者是 B. Eysenbach、T. Zhang、S. Levine 和 R. R. Salakhutdinov。
- 核心内容:创新性地将对比学习视为目标条件强化学习,通过学习一个分类器来区分正未来状态和随机状态,从而估计未来状态的概率密度。在机器人操作场景中,智能体可以利用这种方法,明确哪些未来状态是有利于实现目标的(正未来状态),哪些是随机的、不利于目标达成的状态。这样,智能体在决策时能够更有针对性地选择动作,以达到期望的目标状态。
- 与论文关联:为论文中的对比学习和目标条件强化学习提供理论依据。在折扣状态占用度量的背景下,文献 [17] 的研究成果有助于理解如何通过对比学习优化目标条件强化学习的过程。折扣状态占用度量可以帮助智能体在对比不同状态时,更好地评估状态的价值,因为它考虑了未来状态的折扣因素。这使得智能体在选择动作时,不仅关注当前状态与目标状态的相似性(通过对比学习),还能综合考虑未来状态的长期价值(通过折扣状态占用度量)。
- 文献 [20]
- 基本信息:“Rethinking goal - conditioned supervised learning and its connection to offline RL”,发表于 2021 年的 International Conference on Learning Representations。作者是 R. Yang、Y. Lu、W. Li、H. Sun、M. Fang、Y. Du、X. Li、L. Han 和 C. Zhang。
- 核心内容:重新思考目标条件监督学习与离线强化学习的联系,深入探讨了在离线学习场景下,如何利用目标条件监督学习的知识来优化强化学习算法。在实际应用中,很多机器人操作任务的数据是离线的,即智能体无法实时与环境交互获取新数据。该文献的研究为在这种情况下设计高效的强化学习算法提供了理论指导。
- 与论文关联:为论文在多任务学习和离线学习场景下的研究提供理论参考。在折扣状态占用度量方面,文献 [20] 的研究有助于理解如何在离线学习环境中应用折扣状态占用度量来优化目标条件强化学习。在机器人操作的离线学习任务中,折扣状态占用度量可以帮助智能体在有限的离线数据上,更有效地学习不同状态的价值,从而提高策略的学习效率和性能。同时,该文献对目标条件监督学习与离线强化学习联系的探讨,也为论文中多任务学习的研究提供了新的视角,有助于解决多任务学习中不同任务之间的冲突问题
附录 D:强化学习中的相关多任务学习
训练单个智能体执行多个任务,对机器人学习至关重要。多任务学习的主要挑战之一,是不同任务之间存在冲突的表征和梯度。以往的工作通过知识转移 [60, 61]、表征共享 [62, 63, 64] 和梯度调整 [65] 等策略来解决多任务学习问题。随着大型视觉语言模型 [53, 21, 22, 66] 和大语言模型 [67, 68, 69] 的出现,语言指令在策略学习中,作为补充线索用于区分任务表征 [31, 32, 16, 11, 3, 1, 12, 13, 14]。在本文中,我们利用对比学习,增强语言线索的区分功能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









