






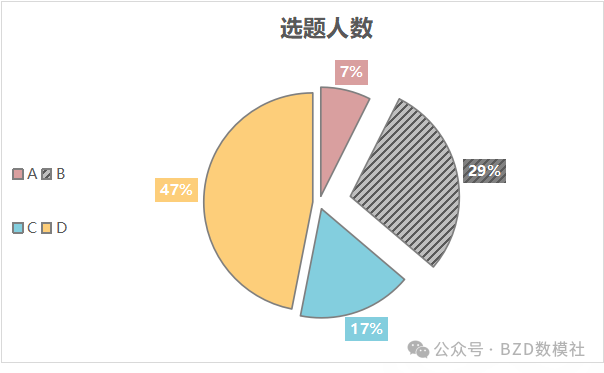
经过36个小时,各个平台的相关选题投票、相关文章阅读量等各项数据进行统计,利用之前的评估办法(详见注释)。在开赛后36小时,我们基本确定各个赛题选题人数,以帮助大家更好地分析赛题局势。
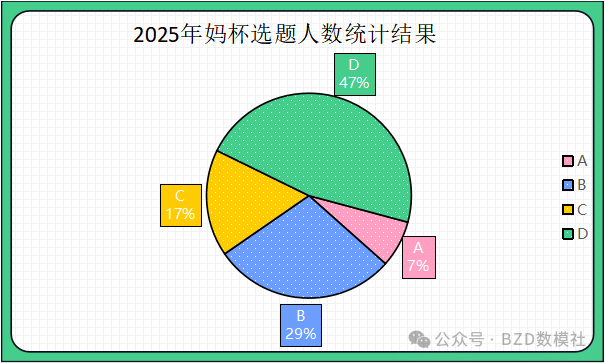
| 题目 | 人数 |
| A | 18 |
| B | 70 |
| C | 41 |
| D | 114 |
通过网盘分享的文件:MathorCup-华中杯竞赛分享代码+论文
链接: https://pan.baidu.com/s/193nGe1uwvt8BV-xk_4P6ug?pwd=bqsw 提取码: bqsw

基于贪心算法的搬迁问题研究
摘要
随着城市化进程的加速,老城区的更新成为现代城市管理和规划中的重要议题。本文研究了如何利用平移置换策略优化老城区搬迁方案,以实现空间再利用和经济效益的最大化。
对于数据预处理,我们首先基于给出附件数据进行必要分描述性分析以便进行后续建模。对于提供图片文件,使用图像处理、光学字符识别(OCR)、用户交互坐标获取和坐标显示。获取各院落之间的相对位置以及距离数据。
对于问题一,拆迁补偿建模。我们在基于题目给出面积、采光、修缮补偿外,还引入搬迁距离、邻里关系和社区因素、交通便利性。具体而言,我们使用修缮补偿最为最终补偿手段,单一居民最多给予20万修缮费。建立基于熵权法的理想解法,对不同居民的拆迁情况进行建模分析。基于给出数据,我们选出基于约束下,每个居民用户的所有拆迁可能性,一共113个居民,单人搬迁一共3623可能性。基于该数据建立评价模型对修缮费进行配分。最多的居民补偿20万,最低的居民无补偿费。
针对问题二极值的求解,目标是根据给定的搬迁条件和限制,通过优化方法为每个居民选择一个合适的目标地块。直接引入问题一计算出的全部可能性进行遍历求解时间复杂度过高,因此本节引入了贪心算法来决策每个居民的搬迁目标,并尽量在满足居民需求的同时最大化开发商的利益,特别是在腾出完整院落方面。
对于问题三,性价增益的搬迁拐点计算。我们首先基于问题二的结果计算正常情况下的m值。得出具体数值后,我们分别从一个居民开始搬家增加到112个居民进行搬家,分析随着居民搬家个数增多m值的变化趋势。在此,利用问题二的实现代码,初步剔除每个居民信息,分析剔除单个居民后的m值的变化趋势,完成性价增益的搬迁拐点计算
对于问题四规划局希望将该案例推广至全国的老旧街区更新搬迁过程中。为了实现这一目标,我们设计一个智能决策软件,能够自动计算老城区的平移置换决策,并为每个搬迁方案计算出相应的性价比m,从而辅助规划和决策。
最后,模型不仅为老城区的平移置换提供了高效的计算支持,而且在搬迁补偿、毗邻效益等方面的创新考虑,为城市更新的决策提供了新的思路和方法。通过模型的推广,能够为各地城市的老城区更新提供具有普适性的方案和决策支持工具。
关键词:老城区更新、平移置换模型、性价比分析、贪心算法、决策支持系统
妈杯D题
短途运输货量预测及车辆调度问题
短途运输存在于物流网络的最后环节,是在同城或同省的末端场地之间进行,即将货物从末分拣点发往营业部。此环节有着运输距离短、资源可复用、时效重点保障的特点。由于处于网络末端环节,短途运输对每个包裹的履约时效及客户体验有着十分重要的作用;同时,该环节也占有着大量的运力资源,对运输活动的合理优化也可以显著提升运输效率,降低运输成本。针对问题1,首先对数据进行预处理,
问题1需要预测未来1天各条短途线路的货量,并将预测的货量拆解到10分钟颗粒度。首先对数据进行预处理,对数据集的异常值进行处理,并在建模的过程中进行归一化操作。由于数据是时序性的,对比LSTM和XGboost的误差与运行效率,选择机器学习模型XGboost作为货量预测模型。最终将预测结果填写在表格当中。
问题2的目标是基于预测的货量数据,进行车辆调度,确保每条线路的需求能够得到满足,并尽量减少总成本。主要涉及多目标和优化约束,使用整数规划来建立和求解这个问题。
问题3主要是为了在现有调度模型的基础上,引入一种新的标准容器,来提升自有车辆的利用率,并评估其对运输效率的影响。优化目标与问题2相同,即通过整数规划来最小化总成本,同时加入是否使用标准容器的决策变量,来确保在最小化运输成本的同时提升自有车辆的利用率。最终,通过模型计算出每条线路的发运车辆数量及是否使用标准容器,并将这些结果应用到调度模型中。
问题4是分析评估货量预测出现偏差时,对调度模型优化结果的影响。在问题4中,我们评估了货量预测误差对调度模型优化结果的影响。通过对货量进行不同幅度的扰动(分别增加和减少20%),进行敏感性分析,分析货量波动对总成本和车辆调度的影响。
关键词:XGboost,多目标优化,整数规划,优化约束,敏感性分析

基于多模型下的就业状态研究
摘要
随着全球经济一体化和信息技术的迅猛发展,失业问题和就业市场的匹配性问题愈加突出。为了解决这一问题,本文提出了一种基于统计学习和机器学习的方法,通过构建求职者与招聘岗位的匹配模型来提高工作岗位推荐的准确性和实用性。
数据预处理,首先,基于给出的数据集进行数据清洗(缺失值、异常值处理工作)。由于样本之间相互独立使用插值处理无意义,本文对于缺失值、异常值直接进行删除处理。对数据清洗后的数据,进行必要分描述性分析以便进行后续建模。
针对问题一,数据特征分析。基于清洗后的数据,进行特征分析,首先分析不同年龄、性别、学历、专业、行业下的就业情况。为了进一步直观的、客观的展示相关性,我们基于数据为分类数据的特征使用卡方检验进行关联关系判定,进一步选择关键指标进行后续建模。
对于问题二,就测状态检测模型。我们基于问题一识别出的关键指标年龄性别学历专业婚姻状态构建预测模型。分别构建决策树、随机森林、支持向量机(SVM) 或 逻辑回归 来建立预测模型。使用Accuracy、Precision、Recall、F1-score对各模型进行评价。
对于问题三,预测模型的优化,我们利用国家统计局收集了近20年每个月的各种指标,引入除了个人层面因素影响外,宏观经济、政策、劳动力市场状况、宜昌市居民、消费价格指数、招聘信息等构建宏观因素。进行特征分析,并选择问题二中精度最高的随机森林进行构建预测模型。
针对问题四,建立一个人岗精准匹配模型的核心目标是通过分析求职者的各类特征(如学历,经验,技能,薪资期望等)与招聘岗位的要求(如所需技能,行业,工作经验,薪资水平等)之间的关系,从而为求职者推荐最合适的岗位。为了实现这一目标,我们可以使用推荐系统中的技术,余弦相似度以及随机森林方法,设计一个基于特征匹配的模型。
关键词:求职者岗位匹配,随机森林模型,机器学习,数据处理,行业匹配

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









