







| Team Number : | Mathorcup |
| Problem Chosen : | D |
短途运输货量预测及车辆调度问题
短途运输存在于物流网络的最后环节,是在同城或同省的末端场地之间进行,即将货物从末分拣点发往营业部。此环节有着运输距离短、资源可复用、时效重点保障的特点。由于处于网络末端环节,短途运输对每个包裹的履约时效及客户体验有着十分重要的作用;同时,该环节也占有着大量的运力资源,对运输活动的合理优化也可以显著提升运输效率,降低运输成本。针对问题1,首先对数据进行预处理,
问题1需要预测未来1天各条短途线路的货量,并将预测的货量拆解到10分钟颗粒度。首先对数据进行预处理,对数据集的异常值进行处理,并在建模的过程中进行归一化操作。由于数据是时序性的,对比LSTM和XGboost的误差与运行效率,选择机器学习模型XGboost作为货量预测模型。最终将预测结果填写在表格当中。
问题2的目标是基于预测的货量数据,进行车辆调度,确保每条线路的需求能够得到满足,并尽量减少总成本。主要涉及多目标和优化约束,使用整数规划来建立和求解这个问题。
问题3主要是为了在现有调度模型的基础上,引入一种新的标准容器,来提升自有车辆的利用率,并评估其对运输效率的影响。优化目标与问题2相同,即通过整数规划来最小化总成本,同时加入是否使用标准容器的决策变量,来确保在最小化运输成本的同时提升自有车辆的利用率。最终,通过模型计算出每条线路的发运车辆数量及是否使用标准容器,并将这些结果应用到调度模型中。
问题4是分析评估货量预测出现偏差时,对调度模型优化结果的影响。在问题4中,我们评估了货量预测误差对调度模型优化结果的影响。通过对货量进行不同幅度的扰动(分别增加和减少20%),进行敏感性分析,分析货量波动对总成本和车辆调度的影响。
关键词:XGboost,多目标优化,整数规划,优化约束,敏感性分析
一、问题求解与分析
4.1 问题1求解与分析
4.1.1 问题1分析
针对问题1,需要预测未来1天各条短途线路的货量,并将预测的货量拆解到10分钟颗粒度。首先对数据进行预处理,对数据集的异常值进行处理,并在建模的过程中进行归一化操作。由于数据是时序性的,对比LSTM和XGboost的误差与运行效率,选择机器学习模型XGboost作为货量预测模型。最终将预测结果填写在表格当中。
4.1.2 问题1建模与求解
1、数据预处理
针对我们给出的附件的数据,首先要做的就是对数据进行预处理操作。需要对附件中的“预知货量”数据进行清洗和归一化处理。对于数据中的异常值(如发运异常或包裹取消),可以使用滑动窗口法或者数据平滑技术来降低其影响。然后拆解至10分钟颗粒度,将每日的货量预测结果按时间段拆解,可以使用线性插值法或者根据历史数据的时段分布,使用加权平均法进行拆分。
表1
| 字段名称 | 附件1缺失值 | 附件2缺失值 | 附件3缺失值 |
| 线路编码 | 0 | 0 | 0 |
| 起始场地 | 0 | — | — |
| 目的场地 | 0 | — | — |
| 发运节点 | 0 | — | — |
| 车队编码 | 0 | — | — |
| 在途时长 | 0 | — | — |
| 自有变动成本 | 0 | — | — |
| 外部承运商成本 | 0 | — | — |
| 日期 | — | 0 | 0 |
| 分钟起始 | — | 0 | — |
| 包裹量 | — | 0 | 0 |
从表1可以看出,所有附件中的字段均无缺失值,数据完整性良好。接下来对数据的异常值进行检测并删除,采用IQR方法,其核心思想是通过数据分布的离散程度来识别潜在的异常点。具体而言,IQR方法首先将数据集按大小排序,并计算其第一四分位数(Q1,即25%分位数,表示有25%的数据小于该值)、第三四分位数(Q3,即75%分位数)以及两者的差值(IQR = Q3 - Q1,反映中间50%数据的分布范围)。随后,通过设定一个经验性阈值(通常为1.5倍IQR),定义正常数据的合理边界:下限为Q1 - 1.5×IQR,上限为Q3 + 1.5×IQR。任何落在该区间外的数据点即被视为异常值。
随后对其进行归一化操作,这里采用最小最大归一化操作,将数据压缩到指定的范围(通常是0 到 1 )。数学公式如下:
其中,
是原始数据点,
和
是数据集
中的最小值和最大值,
是归一化后的值。
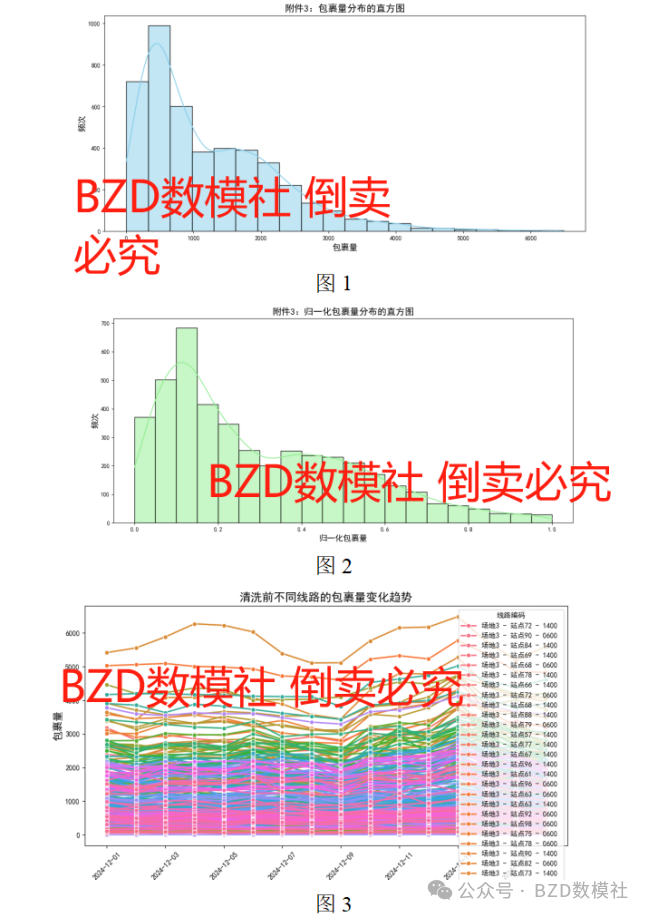
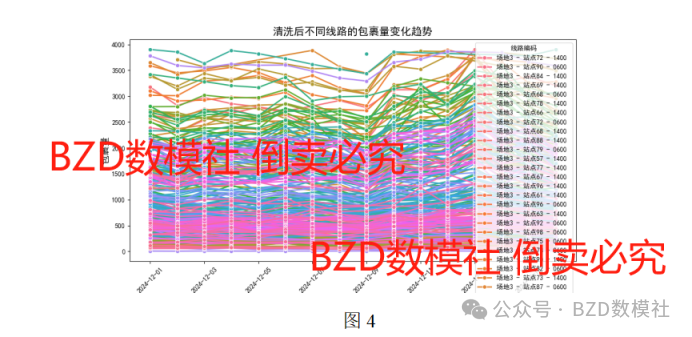
从图1-图4可以看出清洗之后的数据集(如附件3变量包裹量)的分布情况,图5是采用seaborn的热力图分析,观察数据的分布情况,便于后续选择合适的方法进行分析与建模。
其中,
是核函数(通常用高斯核),
是带宽参数,
是数据点的数量
问题一的目标是建立一个货量预测模型,预测未来1天内各条短途线路的货量,并将这些预测结果拆解到10分钟颗粒度。具体的求解过程如下。由于数据是时序性的,对比LSTM和XGboost的误差与运行效率,选择机器学习模型XGboost作为货量预测模型。GBoost 是一种高效的梯度提升算法,专为速度和性能而设计,常用于机器学习比赛和实际应用。XGBoost 是 Gradient Boosting Machine (GBM) 的改进版本,其主要优势在于处理大规模数据集时表现出色,同时支持正则化来防止过拟合。X
使用训练好的模型来对未来一段时间内的包裹量进行预测。模型将利用预知的未来包裹量数据(附件3)作为输入,对未来的包裹量进行调整。最后,将模型预测的结果填充到结果表1和结果表2中,分别填充“货量”和“包裹量”数据。
表2 结果表1部分数据
| 场地3 - 站点83 - 0600 | 2024-12-16 00:00:00 | 4604.35473 |
| 场地3 - 站点83 - 1400 | 2024-12-16 00:00:00 | 911.126255 |
表2 结果表2部分数据
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 21:10:00 | 111.6857203 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 21:20:00 | 80.11741293 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 21:30:00 | 139.480292 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 21:40:00 | 39.52683944 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 21:50:00 | 29.50406848 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:00:00 | 72.84888563 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:10:00 | 166.1219747 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:20:00 | 127.367296 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:30:00 | 75.10632163 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:40:00 | 92.73864651 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 22:50:00 | 15.09804921 |
| 场地3 - 站点83 - 0600 | 2024-12-15 00:00:00 | 23:00:00 | 176.5187485 |
4.4.3 问题4结果分析
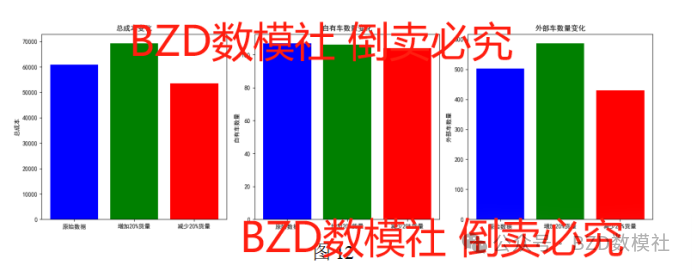
在问题4的分析中,我们通过货量的变化(±20%)对调度模型的影响进行评估。结果显示,当货量增加20%时,总成本显著增加至69,300元,增加了8,400元。这主要是由于更多的车辆需求,尤其是外部承运商车辆的增加。与此同时,自有车数量略有减少,从107辆减少到106辆,而外部车数量则从502辆增加到587辆,说明货量增加时依赖外部承运商的需求大幅上升。
相反,当货量减少20%时,总成本下降至53,400元,减少了7,500元。此时,自有车和外部车的数量均有所减少,自有车数量减少至104辆,外部车数量降至430辆。这表明货量减少能够有效降低车辆需求,从而优化成本结构。
表5
| 情景 | 总成本(元) | 自有车数量 | 外部车数量 | 成本变化(元) |
| 原始数据 | 60,900 | 107 | - | |
| 增加20%货量后 | 69,300 | 106 | 587 | |
| 减少20%货量后 | 53,400 | 430 | -7,500 |

















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









