






泰迪杯作为数据挖掘挑战赛,本届竞赛提供了三个大数据类型题目,其中AC都涉及文本处理以及智能问答系统,需要选手对这方面有一定了解才好上手。因此,B题数据分析处理就作为了大多数选手的选择。本文将为大家带来详细的B题解题思路,并尽可能为大家找到小技巧,可以规避大规模计算的。
基于穿戴装备的身体活动监测
作为大数据竞赛,首先第一步就是进行数据清洗工作,需要对给出的数据进行。对于本题目,由于涉及数据量过大,我们下面以P001为例进行说明。
数据清洗主要包含缺失值直接使用python【】或matlab【】自带函数查找。对于异常值可以分为阈值处理或者模型处理。
| 功能 | Python | MATLAB |
| 判断单个值是否为NaN | pd.isna(val) / np.isnan(val) | isnan(val) |
| 判断数组中位置 | df.isna() / df.isnull() | isnan(A) |
| 筛选含缺失值的行 | df[df.isna().any(axis=1)] | A(any(isnan(A),2), :) |
| Python代码 | Matlab代码 |
| import pandas as pd # 1. 读取数据 file_path = r'G:\1\B题-全部数据\附件1\P001.csv' df = pd.read_csv(file_path) # 2. 显示缺失值统计 print("每列缺失值数量:") print(df.isnull().sum()) # 3. 删除包含缺失值的行 df_cleaned = df.dropna() # 4. 输出处理结果 print(f"\n原始数据行数: {len(df)}") print(f"删除缺失值后的数据行数: {len(df_cleaned)}") print(f"共删除了 {len(df) - len(df_cleaned)} 行含缺失值的数据。") | % 1. 读取数据 filePath = 'G:\1\B题-全部数据\附件1\P001.csv'; data = readtable(filePath); % 2. 显示每列缺失值数量 disp('每列缺失值数量:'); disp(sum(ismissing(data))); % 3. 删除含缺失值的行 data_cleaned = rmmissing(data); % 4. 输出行数对比 originalRows = height(data); cleanedRows = height(data_cleaned); fprintf('\n原始数据行数: %d\n', originalRows); fprintf('删除缺失值后的数据行数: %d\n', cleanedRows); fprintf('共删除了 %d 行缺失值数据。\n', originalRows - cleanedRows); |
阈值处理:查阅文献,找到理论存在X Y Z方向加速度最大值,将该值设定为阈值超过该数据的认定为异常数据,方便起见直接删除处理。下表来自网络收集仅供参考
| 传感器量程 | 最大可记录加速度(每轴) |
| ±2g | 约 ±2 × 9.8 = ±19.6 m/s² |
| ±4g | 约 ±4 × 9.8 = ±39.2 m/s² |
| ±8g | 约 ±8 × 9.8 = ±78.4 m/s² |
| ±16g | 约 ±16 × 9.8 = ±156.8 m/s² |
模型处理:首先对X Y Z方向加速度进行分布方式检验,不同的分布方式对应不同的检验模型。正态分布数据使用3σ原则判定,非正态分布使用箱线图判定,将部分边缘值判定为异常值。(运行时间长、可以误判,不是太推荐)
下面进行每个问题详细的解题
问题一,统计分析志愿者的活动情况
具体问题:根据加速度记录数据,统计汇总附件1中各个志愿者的身体活动信息,数值保留小数点后4位。记录总时长(小时)睡眠总时长(小时)高等强度运动总时长(小时)中等强度运动总时长(小时)低等强度运动总时长(小时)静态活动总时长(小时)。
对于问题一单纯的进行统计分析即可,难度在于我们需要对100个1G左右文件分别进行分析,并存储于结果表格,我自己写了其中一个的记录代码,大家可以自行尝试,单一文件运行时间为10min+【13th Gen Intel(R) Core(TM) i7-13700HX 2.10 GHz 32.0 GB】
因此,本问题通过对数据分析发现,同一秒内记录次数为100次,我们可以单独计算不同活动类型以及出现的次数,计算频数以及利用频数计算时间长度,就可以有效规避大量无用计算。
单一文件计算时间为100s左右,提升了十倍的计算效率
计算结果如下所示
| ID | TotalTime | SleepTime | HighIntensityTime | ModerateIntensityTime | LowIntensityTime | StaticActivityTime |
| P001 | 24.7159 | 10.5833 | 0 | 3.7303 | 3.0009 | 7.4013 |
| P002 | 16.1406 | 6.25 | 0.3567 | 1.1702 | 1.8108 | 6.5529 |
| P003 | 20.5242 | 6.6667 | 0 | 6.7723 | 2.7376 | 4.3476 |
| P004 | 18.9362 | 6.5 | 0 | 2.5809 | 3.1359 | 6.7194 |
| P005 | 17.0661 | 4.3333 | 0 | 1.8884 | 3.9005 | 6.9439 |
| P006 | 15.8555 | 4.0833 | 0 | 2.2976 | 3.5885 | 5.8861 |
| P007 | 21.0392 | 8.25 | 0.4209 | 0.4161 | 5.0036 | 6.9486 |
| P008 | 18.0499 | 6.6667 | 0.0461 | 1.9845 | 2.0668 | 7.2858 |
| P009 | 8.5696 | 6 | 0 | 0.238 | 0.3069 | 2.0247 |
| P010 | 18.6444 | 9.3333 | 0 | 1.9 | 5.4168 | 1.9942 |
| P011 | 13.6566 | 6.1667 | 0 | 0.295 | 1.0817 | 6.1132 |
% 3. 计算不同活动类型
unique_annotations = unique(annotations); % 获取不同类型的活动
num_annotations = length(unique_annotations); % 活动类型数量
| 类型名称 | 出现次数 |
| 7030 sleeping;MET 0.95 | 3810002 次 |
| home activity;eating;13030 eating sitting alone or with someone;MET 1.5 | 74004 次 |
| home activity;household chores;preparing meals/cooking/washing dishes;5035 kitchen activity general cooking/washing/dishes/cleaning up;MET 3.3 | 954511 次 |
| home activity;miscellaneous;sitting;11580 office work such as writing and typing (with or without eating at the same time);MET 1.5 | 144105 次 |
| home activity;miscellaneous;sitting;9055 sitting/lying talking in person/using a mobile phone/smartphone/tablet or talking on the phone/computer (skype chatting);MET 1.5 | 308709 次 |
| home activity;miscellaneous;sitting;9060 sitting/lying reading or without observable/identifiable activities;MET 1.3 | 338112 次 |
| home activity;miscellaneous;standing;9050 standing talking in person on the phone/computer (skype chatting) or using a mobileo phone/smartphone/tablet;MET 1.8 | 7501 次 |
| home activity;miscellaneous;standing;9050 standing talking in person/on the phone/computer (skype chatting) or using a mobile phone/smartphone/tablet;MET 1.8 | 49103 次 |
问题二,构建身体活动 MET 值估计模型
根据附件 1 中 100 位志愿者的性别、年龄及时间与加速度计数据,构建一个机器学习模型,实现实时估计个体在某个时间段内的 MET 值。
MET=F(Y,X,T,x,y,z)
具体问题1:对附件 2 中 20 位志愿者的性别、年龄信息及时间与加速度计数据进行 MET 值预测。
具体问题2:将 20 位志愿者的 MET 值预测结果进行整理,统计汇总各个志愿者的运动强度信息,数值保留小数点后 4 位。
第二小问类似于问题一的步骤直接使用相同的代码改变文件名、路径就可以实现,本节主要针对问题二第一小问进行讲解。
训练数据问题:由于将附件1全部数据合并数量级过于庞大,可以进行随即采样,每个样本仅随机选取100000行数据,大概10MB左右数据集,进行训练。代码跑通后可尝试增加训练数据集。
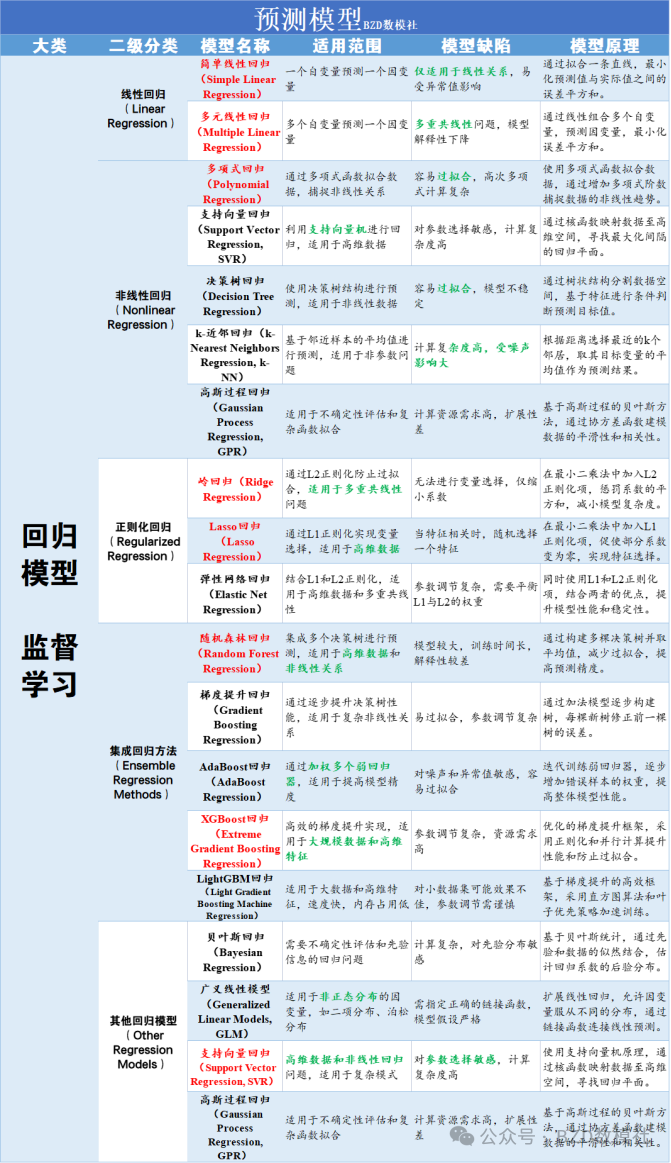
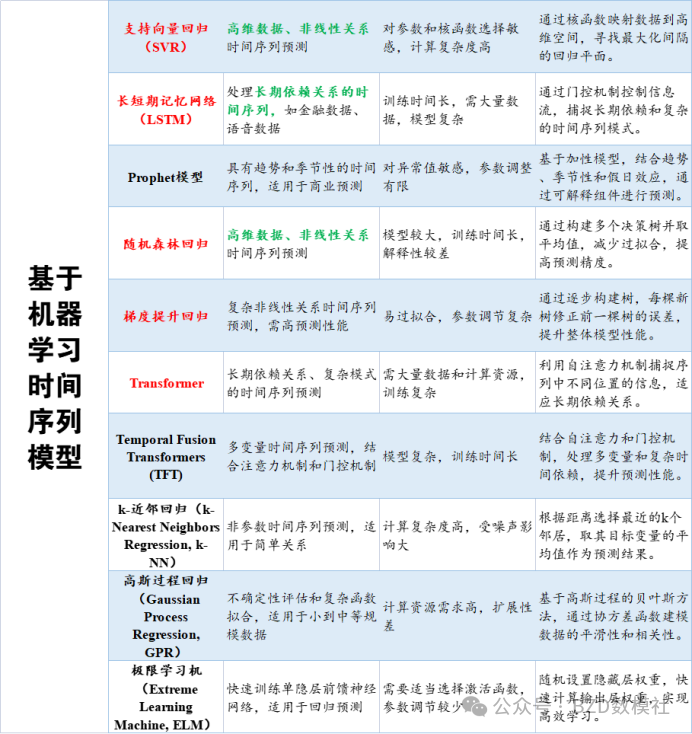
模型问题:大家可以参考文末的我整理的预测模型大纲,理论上任何一个都是可以求解该题目,差别在于预测精度。下面我们以最简单易懂的回归模型为例进行说明【实际代码使用模型可能会更复杂一些,以增加预测精度】
1、数据处理:加速度数据和志愿者的年龄、性别信息进行整理合并
2、构建输入特征:加速度的统计特征、性别、年龄等。
3、构建目标变量:每个时间段对应的MET值
4、模型选择:使用回归模型(如线性回归、随机森林回归或支持向量机回归等)来预测MET值。
5、精度检验:使用MSE、RMSE、MAE等评估指标来衡量模型预测精度【时间宽裕、机器允许理论上可以使用多模型精度对比,择优选择】
对于该问题,我们选择随机森林进行预测展示,主要分为三部
数据合并+模型训练+模型预测
import pandas as pd
import numpy as np
import os # 用于创建文件夹
from tqdm import tqdm # 导入tqdm进度条
# 文件路径
metadata_path = r'G:\1\B题-全部数据\附件1\Metadata1.csv'
file_dir = r'G:\1\B题-全部数据\附件1' # 数据文件夹路径
# 输出目录路径
output_dir = r'G:\1\B题-全部数据\附件1\result_2'
# 1. 检查并创建输出目录(如果不存在)
if not os.path.exists(output_dir):
os.makedirs(output_dir) # 创建目录
# 2. 读取Metadata1.csv文件,提取ID、性别、年龄信息
metadata = pd.read_csv(metadata_path)
metadata = metadata[['pid', 'age', 'sex']] # 提取所需的列
# 3. 初始化合并后的数据框
all_data = pd.DataFrame()
# 4. 获取所有文件名(P001到P100)
file_paths = [os.path.join(file_dir, f'P{i:03d}.csv') for i in range(1, 101)]
# 5. 使用tqdm显示进度条
for file_path in tqdm(file_paths, desc="合并文件进度", unit="文件", ncols=100):
# 6. 读取加速度数据文件,强制指定'time'列为字符串类型
df = pd.read_csv(file_path, dtype={'time': str}, low_memory=False)
# 7. 提取MET值(从annotation列中提取MET值)
df['MET'] = df['annotation'].str.extract(r'MET (\d+\.\d+)').astype(float) # 提取MET值并转为数字
# 8. 合并志愿者ID、性别、年龄信息
volunteer_id = file_path.split('\\')[-1].split('.')[0] # 从文件名提取志愿者ID(如P001)
volunteer_metadata = metadata[metadata['pid'] == volunteer_id].iloc[0]
df['ID'] = volunteer_id
df['Sex'] = volunteer_metadata['sex']
df['Age'] = volunteer_metadata['age']
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import joblib # 用于模型保存和加载
# 1. 加载训练数据
train_data_path = r'G:\1\B题-全部数据\附件3\result_2\merged_data.csv'
df = pd.read_csv(train_data_path)
# 2. 编码性别和年龄
df = df.dropna(subset=['MET']) # 保证没有空值
le_sex = LabelEncoder()
le_age = LabelEncoder()
df['Sex'] = le_sex.fit_transform(df['Sex'])
df['Age'] = le_age.fit_transform(df['Age'])
# 3. 特征和标签
features = ['Sex', 'Age', 'x', 'y', 'z']
X = df[features]
y = df['MET']
# 4. 训练模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X, y)
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import joblib # 用于模型保存和加载
model = joblib.load('met_model.pkl')
le_sex = joblib.load('le_sex.pkl')
le_age = joblib.load('le_age.pkl')
# === 输入文件信息 ===
file_path = r'G:\1\B题-全部数据\附件2\P101.csv'
pid = 'P1021'
age = '38-52'
sex = 'F'
# === 读取加速度数据 ===
df_test = pd.read_csv(file_path, dtype={'time': str})
df_test['Sex'] = le_sex.transform([sex])[0]
df_test['Age'] = le_age.transform([age])[0]
# === 构造特征矩阵 ===
df_test['Sex'] = df_test['Sex']
df_test['Age'] = df_test['Age']
X_test = df_test[['Sex', 'Age', 'x', 'y', 'z']]
# === 预测 MET 值 ===
df_test['MET_Pred'] = model.predict(X_test)
问题三,基于加速度计数据的睡眠阶段智能识别
具体问题:设计并实现一个算法,该算法能够根据个体的加速度计数据,准确识别和分析个体的睡眠阶段及睡眠状态,为改善睡眠质量提供科学依据。
该部分首先使用类似于聚类分析模型对睡眠模式进行分类,根据加速度模长的变化趋势和预定义的阈值,识别睡眠阶段(如快速眼动期、深度睡眠期、浅睡眠期等)。
通过Kmeans初步进行聚类分析 得到结果如下所示
| 志愿者ID | 睡眠总时长(小时) | 睡眠模式一总时长(小时) | 睡眠模式二总时长(小时) | 睡眠模式三总时长(小时) |
| P101 | 7.5 | 0.2799 | 5.7886 | 1.4315 |
| P102 | 6.5 | 1.0896 | 3.3584 | 2.052 |
| P103 | 9.85 | 2.7317 | 4.3758 | 2.7425 |
| P104 | 8.0833 | 1.0929 | 3.5192 | 3.4712 |
问题四,基于加速度计数据的久坐行为健康预警
具体问题:基于附件 1 文件夹中 100 位志愿者的加速度计数据及对应的活动行为,自动识别久坐行为状态,并在适当的时候发出预警,帮助用户了解和改善自己的活动习惯。
设置静态行为的阈值(<1.0MET < 1.6),并结合时间段(每次静态行为超过30分钟则认为是久坐)。对每位志愿者的加速度数据进行久坐行为检测。
问题三四仅由于还未开始实践、仅为初步思路,后续会根据实际求解过程进行完善。

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









