







 本文介绍了Pytorch中的张量概念,神经网络的基本组成,包括输入层、隐藏层和输出层,并探讨了深度学习的含义。线性层、ReLU和Softmax等关键运算在神经网络中的作用也被阐述。此外,文章还讨论了模型的训练、保存和加载,以及ONNX格式在模型交换中的应用。
本文介绍了Pytorch中的张量概念,神经网络的基本组成,包括输入层、隐藏层和输出层,并探讨了深度学习的含义。线性层、ReLU和Softmax等关键运算在神经网络中的作用也被阐述。此外,文章还讨论了模型的训练、保存和加载,以及ONNX格式在模型交换中的应用。
本文以 Pytorch 为线索,介绍人工智能和深度学习相关的一些术语、概念。不过由于特别长,所以持续更新ing。
关于发展历史您也可以阅读深度学习神经网络之父 Jürgen Schmidhuber 所写的《Annotated History of Modern AI and Deep Learning(现代人工智能和深度学习的注释版历史)》,个人认为这篇博客虽然对于新手来说非常不友好,但是非常全面,非常建议您阅读一下,尽管很多看不懂的地方,但是对于新手来说也会大有收获。
tensor(张量)
Tensor(张量)是一种专门的数据结构,与数组和矩阵很像。张量其实可以理解成数组和矩阵的扩充,因为数组最多只能是二维,也就是一个矩阵,但是神经网络有时候需要更高纬度,这个时候数组就不够用了(在 C 中可以使用指针实现哦)。
在 Pytorch 中,张量是一个类,能够通过数组、numpy 转换得到,张量甚至可以与 numpy 共用内存地址。
在 Pytorch中,shape是表示张量纬度的元组。如下生成输出的是一个 2 行 3 列的张量:
>>> shape = (2,3,)
>>> zeros_tensor = torch.zeros(shape)
>>> print(f"Zeros Tensor: \n {zeros_tensor}")
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
neural network(NN,神经网络)
从字面上来看,NN(这里往后一律将神经网络称为 NN ,这是为了避免在阅读过程中出现误解)是模拟人类的神经元进行计算:信号传递到神经元,通过神经元的计算再输出。但是在 NN 中,这些“神经元”都有了新的称呼:输入层、隐藏层(也就是处理数据的部分)、输出层。
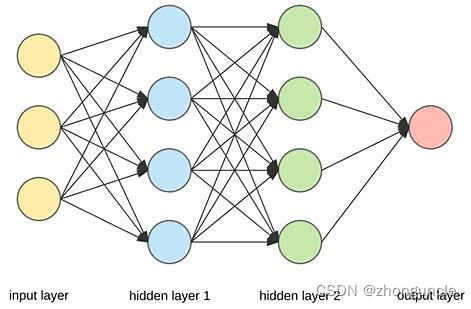
此外,虽然有一些 NN 的研究和发展确实参考了人类的神经系统,但是现在 NN 的研究与人类神经系统关系不大了。
1805 年,Adrien-Marie Legendre 发表了最小二乘法(least squares method),也被称为线性回归,现在被称为线性 NN。
这个最早发表的 NN 有两个层:一个包含了多个输入单元的输入层,以及一个输出层。
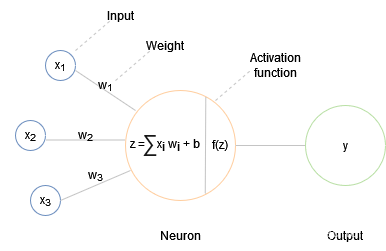
工作流程为:每个输入单元是一个实数,将输入与误差函数的相乘,在与权重的相加,然后将得到的总和输出(也就是下图右侧的式子)。

这与今天的线性 NN 在数学上一模一样:基本算法、误差函数(bias)、权重(自适应参数)。下图中的“Activation function”是基本算法,方程中的“b”是 bias,“weight”是权重:
但是如果根据 NN 的概念来看,第一个 NN 出现在 1801年:德国数学家卡尔·弗里德里希·高斯(就是高斯算法的那个高斯)就使用最小二乘法(可以理解成利用“浅层”学习进行模式识别),以此计算预测出谷神星的位置,因此成名。
而 NN 这一术语则是由 Aizenberg 等人于 2000 年第一次提出(这比很多人年龄都小了)。
在 Pytorch 中,命名空间 torch.nn 提供了构建自定义神经网络所需的所有构建模块。也就是 Pytorch 的开发者提前写好了现有的各种模块,这样就不用自己一个个去写了,只要使用即可。但是如果你想出了一种新的层或者模型,那么就得自己编写构建了。
deep learning(深度学习)
深度学习全名为“深度前馈网络架构的学习”,也就是就是在 NN 中有多个非线性隐藏层,这也解释了为什么上文中将最小二乘法称为“浅层”学习。
虽然“深度学习”这一名词最早由 Dechter 引入,但是第一次深度学习是出现在 1965 年的苏联。Alexey Ivakhnenko 和 Valentin Lapa 为包含了多个隐藏层的深度 MLP(多层感知器)引入了第一个通用的学习算法。
NN 的输入层
NN 的输入层由张量展开(flatten)获得,如下:

只有展开之后,输入数据才能很好地被隐藏层处理。
在 Pytorch 中由nn.Flatten实现。例如下面是将 3 张 28x28 的图片展开成 3 个存储了 784 个像素的一维数组,然后放在一个多维数组中:
>>> flatten = nn.Flatten()
>>> flat_image = flatten(input_image)
>>> print(flat_image.size())
torch.Size([3, 784])
NN 的各种模型层(Model layers)
NN 中的每一层都相当于一种模型,会对数据进行处理、计算、输出等操作。
Pytorch 提供了很多模型供我们使用,包括线性层、非线性层、变形金刚(Transformer)、并行数据处理层等各种构建神经网络所需的模块。详细还请查看 torch.nn :

这里以线性操作中的 Linear(处理数据) 和 Softmax(缩放数据得到可能性),以及非线性操作中的 ReLU 为例进行介绍,其他模块同理。
Linear
Linear 是一个使用权重和 biases 将输入值线性转换的模块。数学含义如下:
w e i g h t ∗ i n p u t + b i a s weight*input+bias weight∗input+bias
例如下面是使用 Pytorch 将输入的 28*28 个特征(也就是上文中的 784 个像素)通过线性层nn.Linear转换成 20 个特征输出,并且hidden1表示第一个隐藏层:
>>> layer1 = nn.Linear(in_features=28*28, out_features=20)
>>> hidden1 = layer1(flat_image)
>>> print(hidden1.size())
torch.Size([3, 20])
Softmax
Softmax 用于计算 NN 输出结果的可能性,只用于 NN 的输出层,计算出的可能性区间为 [ 0 , 1 ] [0, 1] [0,1](表示每一类的模型预测密度)。数学含义如下:
f ( x i ) = e x i ∑ j e x j f(x_i)=\tfrac{e^{x_i}}{\sum_j e^{x_j}} f(xi)=∑jexjexi
上面使用 linear 将 784 个输入特征转换成了20个输入特征,但是最后输出的内容应该是根据可能性来判断出来。所以这时候需要 Softmax 对上一层传过来的返回值进行处理,从而得到各种类型的可能性,然后选择可能性最大的结果作为输出。
下图中左侧为概括出的模型,右侧为详细模型运行流程:
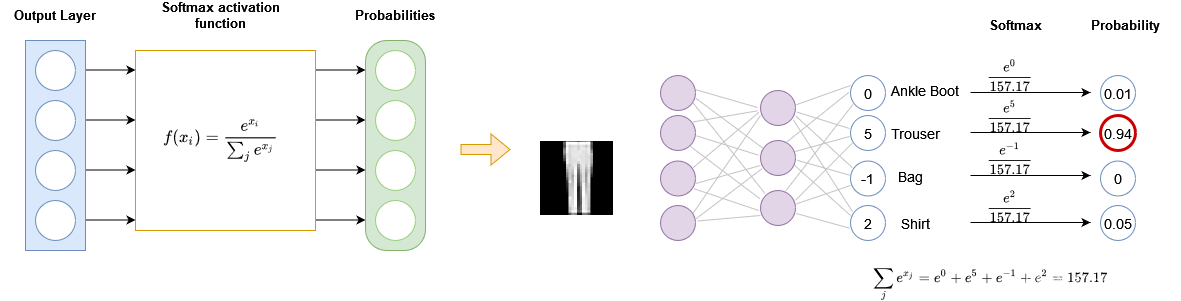
可以看到,这里 Softmax 将得到的值(区间为 [ − ∞ , ∞ ] [-\infty, \infty] [−∞,∞])带入上面那个数学公式进行计算,得到的结果就是可能性。
ReLU
非线性操作(Non-linear activations)是为了在输入层和输出层之间创建复杂的映射表,通常放在线性转换之后。这样可以方便 NN 学习复杂多样的多项式。
ReLU 操作函数将线性操作层得到的计算结果中的负值替换成 0。数学含义如下:
线性层输出结果: x = w e i g h t ∗ i n p u t + b i a s R e L U 输出结果: f ( x ) = { 0 if x < 0 , x if x ≥ 0 \begin{align*} 线性层输出结果:x&=weight*input+bias \\ ReLU 输出结果: f(x)&= \begin{cases} 0 & \text{if } x < 0,\\ x & \text{if } x \ge 0 \end{cases} \end{align*} 线性层输出结果:xReLU输出结果:f(x)=weight∗input+bias={0xif x<0,if x≥0
比如说有这样一个张量:
tensor([ 0.2190, 0.1448, -0.5783, 0.1782, -0.4481, -0.2782, -0.5680, 0.1347,
0.1092, -0.7941, -0.2273, -0.4437, 0.0661, 0.2095, 0.1291, -0.4690,
0.0358, 0.3173, -0.0259, -0.4028])
在经过 ReLU 计算之后,得到的结果是:
tensor([0.2190, 0.1448, 0.0000, 0.1782, 0.0000, 0.0000, 0.0000, 0.1347, 0.1092,
0.0000, 0.0000, 0.0000, 0.0661, 0.2095, 0.1291, 0.0000, 0.0358, 0.3173,
0.0000, 0.0000])
训练神经网络
上文提到 linear 的数学含义是:
w
e
i
g
h
t
∗
i
n
p
u
t
+
b
i
a
s
weight*input+bias
weight∗input+bias
这里有两个因素可以影响输出结果:
w
e
i
g
h
t
weight
weight 和
b
i
a
s
bias
bias 这两个参数。那么这两个值是如何确定的呢?当然你可以一个个自己设置,然后再根据结果调整参数,最后得到能使结果最接近预想值的参数,但是这样想想都很麻烦。
或者也可以通过特定算法(称为学习算法)进行迭代调整获得合适的参数,使得结果越来越接近预想值。每一次迭代称之为 1 epoch(世)。而这个迭代的过程就是训练神经网络。
最常见的学习算法是反向传播算法(back propagation),由于只是介绍概念就不在这里详细介绍反向传播算法的原理了(应该会单独写一篇,写了会贴链接在这)。
保存和加载模型
在训练完神经网络模型之后,需要保存模型用于推断。有几种方法保存和加载模型:整体保存、结构和参数分开存放,以及 ONNX。ONNX 的保存和加载请查看“ONNX”部分。
整体保存
Pytorch 可以保存整个模型,然后再加载。方法如下:
# 保存整个模型到`PATH`
torch.save(model, PATH)
# 从`PATH`加载模型
model = torch.load(PATH)
# 设置“eval”模式用于推断
model.eval()
结构和参数分开保存
这种方法是保存训练学习到的模型参数存放到到一个内部状态字典中,也就是保存源代码和学习得到的参数即可。这也是最常用的保存模型的方法。
这样保存模型的话,加载模型就有两步:
- 重新创建模型结构(因为只保存了学习到的参数);
- 加载状态字典到模型结构中(也就是加载学习到的参数)。
方法如下:
# 保存模型参数到`PATH`
torch.save(model.state_dict(), PATH)
# 重新声明创建模型结构(如果上文没有模型代码,那么需要载入)
model = TheModel(...)
# 加载保存的参数到`PATH`
model.load_state_dict(torch.load(PATH))
# 设置“eval”模式用于推断
model.eval()
ONNX
ONNX 全称 Open Neural Network Exchange(开放神经网络交换),是用来分享神经网络和机器学习的格式。ONNX 是为了解决在不同平台加速神经网络训练和推理的不便。如果没有 ONNX,那么就需要花大量时间来优化在不同框架、不同设备上的性能。这不仅需要大量的时间,只需要了解不同的编程语言、不同平台的特性等等。
ONNX 是把模型结构和参数存在一起了,这与上一节将结构和参数分开存放的方法不一样。
在 Pytorch 中使用以下方法输出模型为 ONNX:
onnx_model = 'data/model.onnx'
onnx.export(model, input_data, onnx_model)
其中,model是准备导出的模型,onnx_model是导出后的模型。
这里保存模型为data/model.onnx(这是个路径)。
加载模型进行推断也只用一步,使用onnxruntime.InferenceSession创建一个 session 即可:
# 创建session(加载模型)
onnx_model = 'data/model.onnx'
session = onnxruntime.InferenceSession(onnx_model, None)
# 设置输入数据和输出数据
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# 开始推断
result = session.run([output_name], {input_name: x.numpy()})
# 这里的`classes`是数据的分类列表
# 将推断结果赋值给`predicted`
predicted = classes[result[0][0].argmax(0)]
# 将预想结果赋值给`actual`
actual = classes[y]
# 输出预想值和实际值
print(f'Predicted: "{predicted}", Actual: "{actual}"')
当然这部分内容很多,更多信息可以查看:
Pytorch 官方文档 TORCH.ONNX
以及 ONNX RUNTIME 官方介绍 Inference with ONNXRuntime(使用ONNXRuntime推断)
加速训练或推理
前面提到了神经网络不论是训练还是推理,主要就是计算张量。你可能还记得自己计算矩阵的时候,一个个计算多费劲,就想有好几个自己一起算,对于计算机来说也是这样。所以对于训练神经网络来说,并行计算能力非常重要。而并行计算能力一般和算数逻辑单元(ALU,例如 Nvidia 的 Cuda Core)相关(并不是唯一相关,还与显存带宽有关。详情可以查看我的另外一篇博客《在笔记本和 Mac mini 2018 上 Pytorch 实现的简单 NN 性能测试》)。
CPU 设计目的是串行计算,这是为了尽可能快地实现一些操作,多核 CPU 也就是为了可以并行执行几十个这样的串行计算(线程),进而提高吞吐量;而 GPU 设计目的就是为了在同等价格和功耗的范围内提供比 CPU 更多的吞吐量和内存带宽。
CPU 核心的大部分晶体管都是用来实现数据缓存和流量控制器。并且由于 X86 是复杂指令集,尽管这样可以使用较少的指令完成任务,但是实现一个核心所需的晶体管就多出了很多(指令要用晶体管实现的)。虽然 ARM 这种精简指令集会好一些,但是也没好到哪去。所以尽管光刻等芯片制造技术进步了很多,但是现在核心最多的单插槽 CPU 是 128 个物理核心(Ampere Altra Max)。
而 GPU 提高吞吐量是通过几百上千个 ALU 来弥补的单核性能不足的问题,例如轻薄本用的 MX250 的 Cuda 核心数量都有 384 个。并且 Nvidia、Apple 等厂商还在 GPU 中放入了专门计算张量的模块,很多晶体管被用来提升并行计算能力,这样并行计算性能提升更高。所以一般训练模型会使用显卡进行加速。
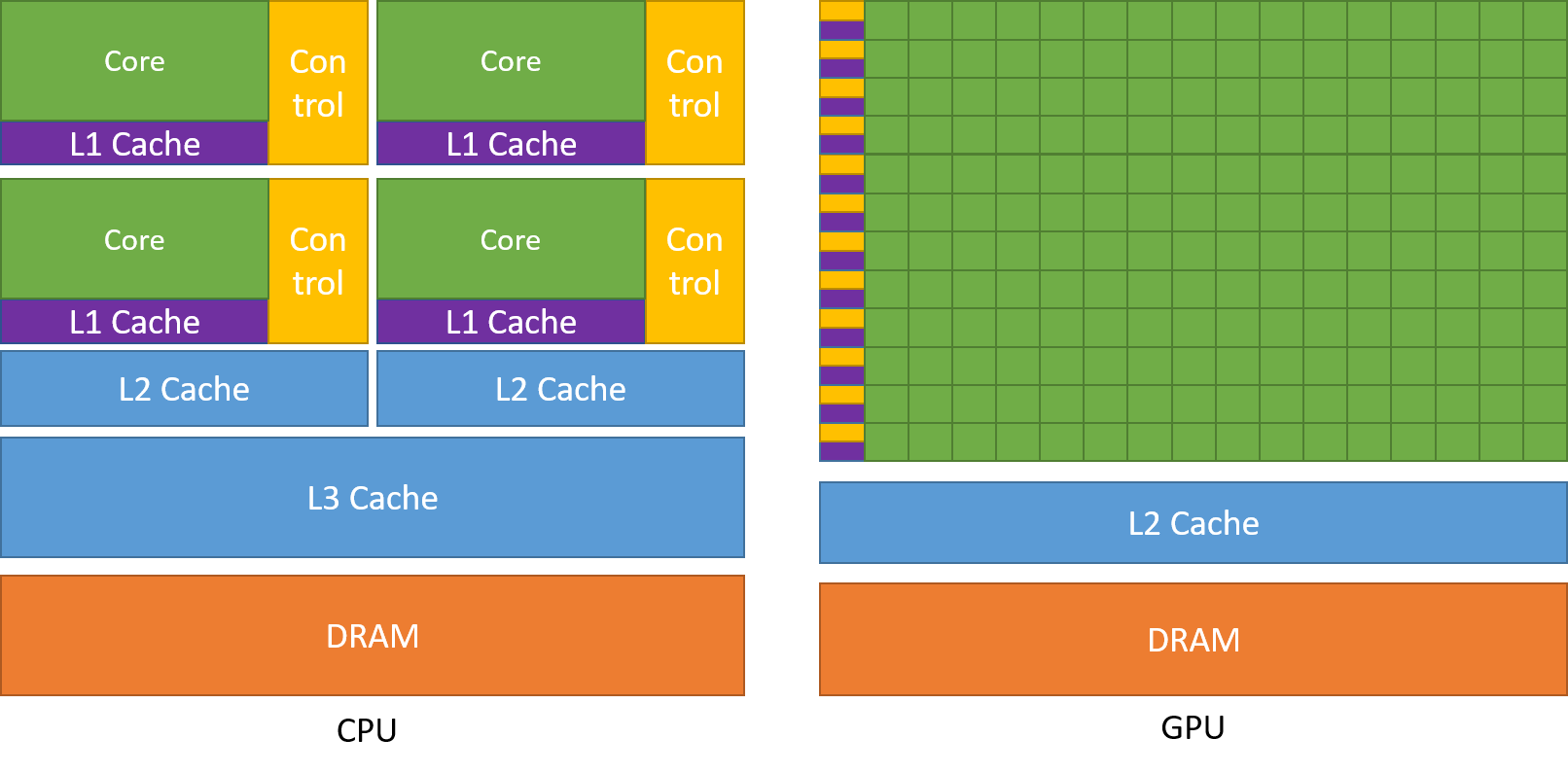
当然还有能效更优的 FPGA。这里就引用英伟达开发者文档中的话:CPU 擅长串行计算,GPU 适合并行计算。虽然 FPGA 能效更佳,但是编程灵活性太低了,所以 GPU 是最均衡的选择。
不同平台加速训练的框架如下:
需要注意几点:
- Apple 的 MPS 加速只支持 Apple 芯片或搭载了 AMD 显卡的 Mac,Intel 的核显不支持(虽然核显支持 Metal)。
- Intel 的 Intel® Extension 不光可以利用 GPU 加速,也可以利用 CPU 加速(通过 AVX-512 和 AMX)。如果你只想使用 CPU 进行加速,不用额外的设置;如果想使用 GPU 加速,那么需要使用
xpu这个设备名。当然前提是你的 Pytorch 包含了 Intel® Extension,如果没有可以自己编译一下:https://github.com/intel/intel-extension-for-pytorch。
希望可以帮到有需要的人哦~

















 4878
4878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









