









Binary Analysis with Architecture and Code Section Detection Using Supervised Machine Learning [SPW 2020]
Bryan Beckman and Jed Haile, Idaho National Laboratory National and Homeland Security, Critical Infrastructure
本篇论文详细介绍一种既可以识别二进制框架又能定位文件中重要代码段的技术. 这种对未知二进制的识别使用了一种称为字节直方图的技术,以及各种机器学习(ML)技术,我们称之为“What is it Binary”或WiiBin。字节直方图的优点是计算简单,不依赖文件头或元数据,当原始文件只有一小部分可用时比如二进制文件中存在加密或者压缩的段,允许获得可接受的结果. 利用WiiBin,我们能够精确地(>80%)确定测试二进制文件的体系结构,即使文件中只有20%的传染性部分(contagious portion)存在。通过使用WiiBin框架,我们还能够确定代码段在二进制文件中的位置。最终,从二进制文件中收集到的信息越多,就越容易成功地进行逆向工程。
一句话: WiiBin: 识别二进制的体系结构和定位关键代码段.
导论
目前有各种技术和工具可以确定二进制文件的体系结构, 包括IDA Pro、Binwalk和Ghidra。本文基于之前的工作"使用机器学习自动分类目标代码"[1], 在原先工作上进行扩展以进一步提升架构识别精度. 除了架构预测之外,同样的直方图技术还首次用于确定二进制文件中代码/指令段存在的位置。
字节直方图是通过迭代二进制中的每个字节, 并记录每个可能字节在256值长向量中的出现次数生成的,其中向量中的每个元素表示从0x00到0xFF的十六进制字节值。然后根据处理的字节总数,将每个向量值归一化为0到1之间的值。当绘图时,得到的矢量创建一个类似于质谱仪(mass spectrometer)输出的图形。
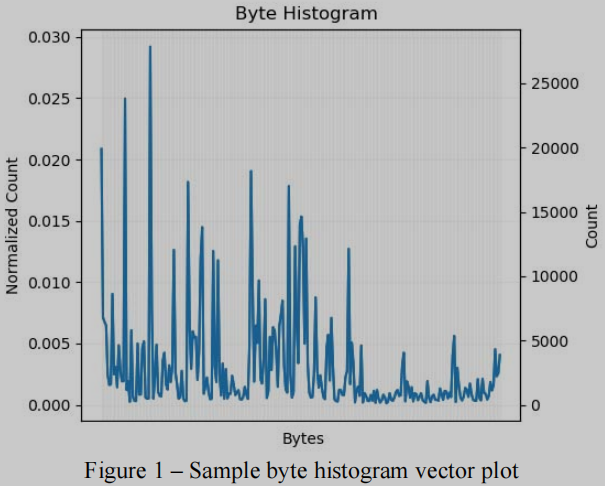
这个字节直方图向量可以被视为生成它的文件的伪指纹。这种直方图结构能够将每个文件的大量数据编码成结构化机器学习算法可以利用的格式。结果将是根据特征的相似性对其他未知二进制进行分类。
之前完成的研究中[1],端序的概念被证明是精确识别mips和mipsel之间差异的一个非常有效的组成部分。为了识别字节序,对二进制文件中相邻的字节对进行计数。大量的表示0x0001和0xFFFE的对通常是一个大端序体系结构,而那些具有大量的0x0100和0xFEFF对表示小端序架构。为了提高体系结构检测的准确性,我们还使用了熵分析技术Binwalk[2]。使用这个工具,我们可以定位并过滤出二进制文件中包含高熵和/或低熵的部分。高熵部分通常是那些被压缩或加密的部分。那些低熵的通常对应于在二进制代码段之间填充一个常数值。(但是, 在计算字节直方图时,在熵极值处看到的所有这三种效应都是无用的,反而会破坏或污染字节直方图。)
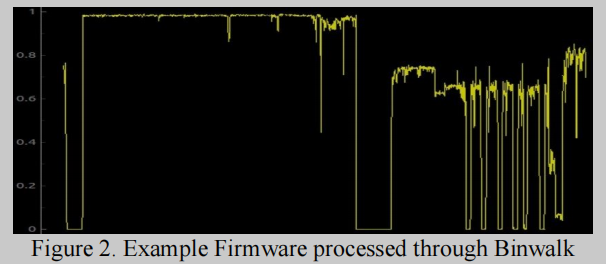
此外本方案不需要完整的二进制文件来确定架构信息, 文件可能是通过网络传输时收集的部分文件,也可能是在未删除之前已损坏或部分覆盖的文件。这些不完整或损坏的文件可能缺少通常用于确定二进制体系结构的关键部分,如ELF头、PE头或其他元数据。
方案
架构检测和代码段定位的建议方法是在所有的训练和测试中使用完整的二进制文件,包括任何头文件、字符串等。这与仅利用二进制代码部分的做法相反,该部分将包含通过字节直方图准确识别体系结构所需的指令和操作码。只要二进制文件或二进制文件的一部分包含代码段或代码的子集,我们就应该能够高度准确地识别文件的体系结构。

当0x0001字节对数目比0x0100字节对更多时, 则给大端序赋值1, 小端序赋值0, 反之反过来
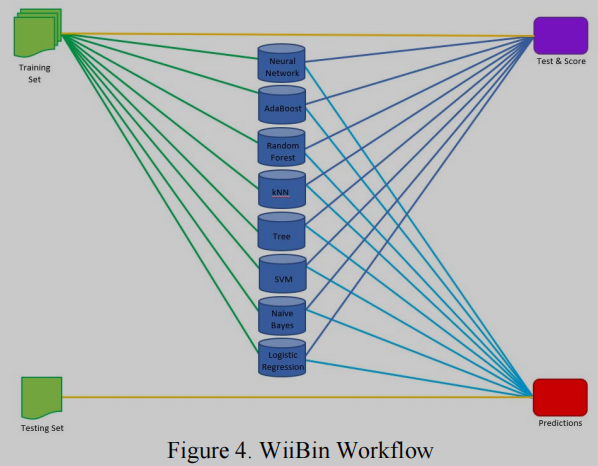
在开发过程中,WiiBin的机器学习实现是由BioLab的Orange提供的, 包括8种ML算法,包括神经网络、AdaBoost、随机森林、kNN、树、支持向量机、Naïve贝叶斯和逻辑回归.
研究人员将使用一个脚本来选择每个测试数据文件的10%、20%、80%和90%的连续子部分。意味着新的子测试集只包含来自完整测试数据集的每个文件的随机连续部分。在处理由这些子测试集生成的字节直方图之后,能够确定需要多少文件来预测其架构,并且准确率超过80%。
此外还测试一种邻接相关的技术,用于识别二进制文件中代码/指令段出现的位置。该技术将使用一个实现滚动窗口的脚本,将输入二进制分割为一个10KB二进制的自定义测试集,每个测试集与相邻的10KB二进制有50%的重叠。这些重叠的二进制文件将被处理, 转换成字节直方图向量,并最终通过WiiBin运行。将输出数据与Binwalk熵图的数据对齐,将显示出8种ML算法(神经网络、AdaBoost、随机森林、kNN、树、支持向量机、Naïve贝叶斯和逻辑回归)在每个部分的架构上的最佳一致性。
实验
架构判断
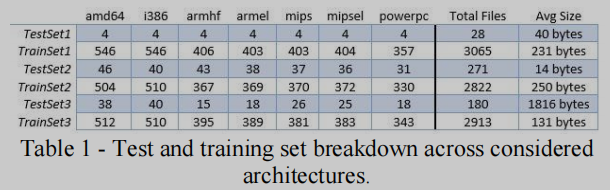
实验所选择的体系结构是操作技术(OT)组件和环境的通用体系结构,包括amd64、i386、armhf、armel、mips、mipsel和powerpc指令集。收集了由Debian 7.0二进制文件组成的数据集。这个集合是通过为每个感兴趣的体系结构下载预编译的Debian映像来收集的。然后对这些图像进行解压缩,并从生成的.deb文件中提取原始二进制文件。只有文件名中带有版本号的文件被选择包含在主数据集中。从主数据集中选取了三个测试集和三个训练集。
不考虑端序检查时, 大部分ML算法都可以达到80%的准确率
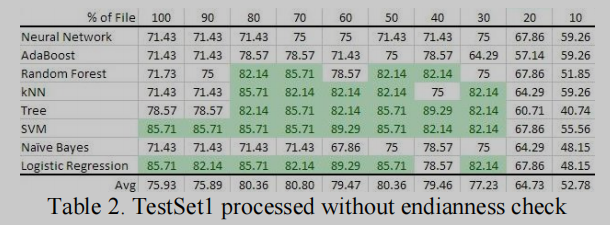
TestSet1显示仅使用原始文件的20%就可以提供精确的体系结构预测(>80%)。

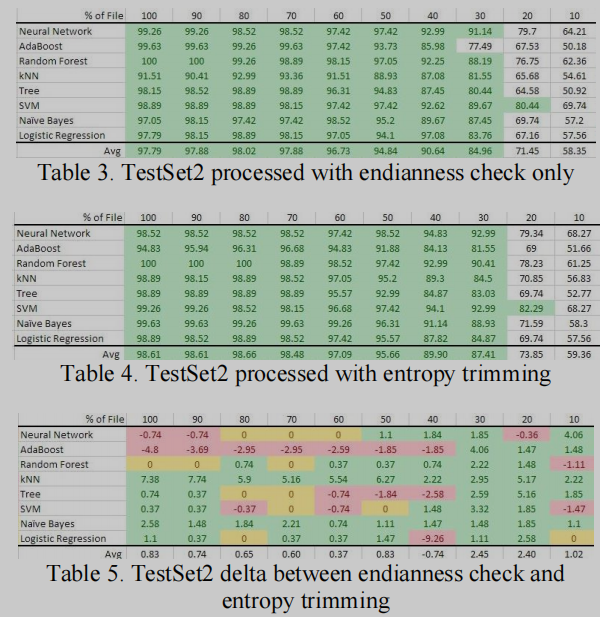
为了改进考虑端序的结果准确率, 利用Binwalk的熵特征忽略所有高熵数据(>0.9)和所有低熵数据(<0.1), 大部分结果都有提升
代码定位
WiiBin在二进制文件中识别包含代码/指令/操作码的部分的能力取得了显著的效果。该检测过程利用前面描述的滚动窗口技术从单个二进制文件生成新的测试集。这个单一的二进制文件被编程地分割为多个10KB的重叠子二进制文件。
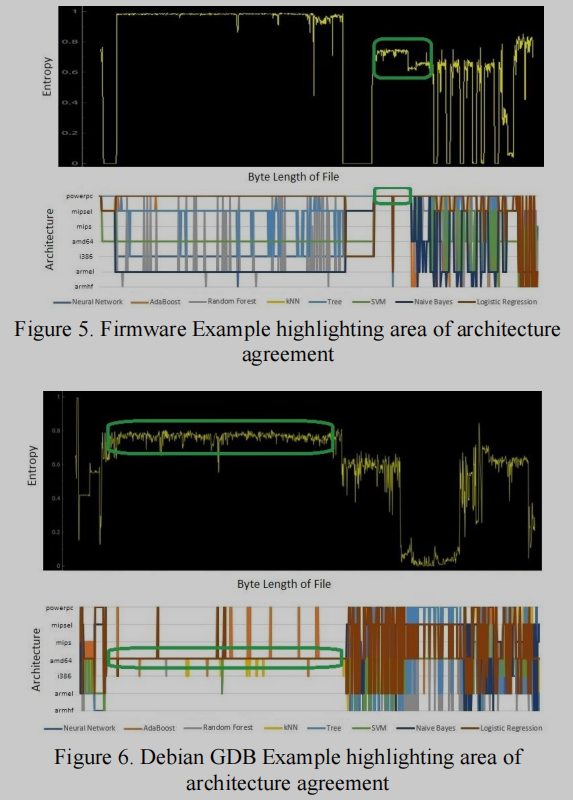
架构一致性最高的部分在熵图和一致性图上都圈了起来。这些部分指出了代码/指令数据存在的区域,因为八种ML算法中的大多数能够就检测到的体系结构达成一致。最一致的点可以被认为是代码/指令存在的区域。在没有找到操作码的情况下,每个ML算法都有自己的架构解释,因此也存在分歧。
表6显示了对其他体系结构(armv4l, armv4tl, armv5l, armv6l, i486, i586, m68k, mips, mipsel, powerpc, sh4, sparc, x86_64)编译的BusyBox[4]构建的测试结果(它能够识别我们所选的七个体系结构)。
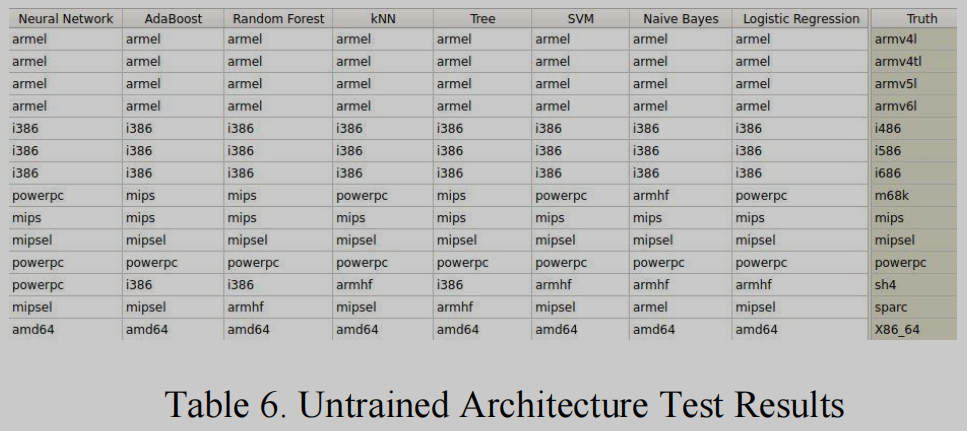
在测试中,所有未知的ARM变体都被检测为ARM。所有未知的x86变体都被识别为i386,所有已知的架构都被正确识别。甚至m68k体系结构也被确定为其近亲PowerPC,这表明即使未知的体系结构也可以与类似或派生的体系结构相关联。
总结
Related Works
[1] J. Clemens, “Automatic classification of object code using machine learning,” DFRWS 2015 USA. [Online].
Available: https://www.sciencedirect.com/science/article/pii/S1742287615000523. [Accessed Aug 10, 2019]
[2] Binwalk, https://www.refirmlabs com/binwalk/
[3] Orange, https://orange.biolab.si/
[4] BusyBox, https://busybox.net/
















 6913
6913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









