







本文章说明通过增加网络宽度可能有利于图像信息集成,首先根据MR块改写除了MSC块,MR块为一个并行的卷积模型,两侧卷积核大小相同但由于卷积权值不同所以可以卷积出不同的局部特征信息进行融合后以残差的形式与卷积出的特征进行融合从而充分提取局部特征,而改进后的MSC块是通过改变两侧并行卷积核的大小使卷积能够提取不同感受域下的不同信息
本文为了验证效果做了一个实验即用L3R5,L3R3,L5R5,L7R7以及一个不并行的残差块做了一个实验将这些块放入同一个网络中从而比较峰值信噪比

从效果可以看出在左右卷积核差的越大的情况下psnr越高同时参数也越多因此选取一个参数较少psnr较高的模式即L3R5可能会得到很好的效果(图中增加很小是因为这是四个块增加的程度而深度网络中含有很多这种块所以增大幅度很大)另外这里不同大小卷积核卷积时存在一个特征图大小不匹配的问题,不过通过卷积可以解决,即卷积可以卷积出任意大小的特征图,例如用一个33和一个55的卷积核去卷积一个88的图片设步长为1那33的卷积核在每行上都要卷积5次在列上也要卷积5次即得到一张55的特征图,而55的卷积核可以通过padding(即补0)来扩张卷积出的特征图大小即令padding=2这时图片变成了1010所以也得出了55的特征图,。而在MSC中就是用这种方法令不同卷积核卷积出的特征图大小相同即等于初始浅层特征提取得出的特征图大小。此处还涉及到了一个恒等映射的问题,此处通过上一层提取特征相加之后/2得到图像平均信息后直接传给输出形成 残差,而残差快存在一个恒等映射,即残差网络其实就是把输入直接输入到输入位置假设输入为x,期望输出为y,学习目标为r,因此残差之前可以写成r=y可如果添加了残差网络的学习目标就变成了y=r+x即学习目标从学习全部的y转变成了学习他们之间的差值y-x,即从学习一张图片变成另外一张图片到学习两张图片的残差后加到初始图片上自然大大减少了参数,再来说下恒等映射:残差块的连接点在线性激活之后非线性激活(激活函数)之前,将输入用跳转连接导入输入输出后进行激活时公式就变成了r(x+n)其中r为relu,x为输入n为经过卷积后的特征,此时激活函数激活这两部分输入部分x正常激活,而n由于relu小于0时为0所以大量数据被归0此处最优化时为全部为0此时y=x即恒等映射不增加参数,而当然不可能全部被归0仍会有一部分特征保留下来加到输入x上这就是残差,以极小的参数实现了特征的增加,当然恒等映射仅存在于理论中。 最后一层将前面所有提取到的特征经行融合即相加/2,之后再与最后的两层卷积层相加输出提取到的残差特征

作者提出的系统的作用阶段是在上采样之后反向传播之前,主要用来提高上采样后的图像质量,首先经过卷积层进行浅特征提取之后经过多个并行结构进行深层特征提取但是要注意随着深度的加深形成残差的图像会越来越清晰但是会与初始时的图像信息相差越来越大,所以本文并未直接输出失真图片,而是采用了每个块都输出一个特征图与初始hr图像形成残差生成高分辨率图像之后将所有图片进行加权融合从而生成hr图像
 损失函数为:
损失函数为: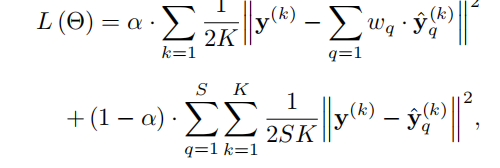 该损失函数前半部分主要用于比较生成图片与真实图片的逐元素差值,k代表批次,q代表块生成的图片的数,后半部分主要用来约束真实图片与块生成的高分辨率图片,这里主要是保证所有残差快生成的都为高分辨率图像防止出现一些很不清晰一些很清晰最后得出较为清晰的图片这样就和失真的效果一样例如只有一张图片高清但是失真其他都模糊最后得出高清图片这就与直接输出相同了,因此要用损失函数进行约束,q代表块生成特征图,k代表批次
该损失函数前半部分主要用于比较生成图片与真实图片的逐元素差值,k代表批次,q代表块生成的图片的数,后半部分主要用来约束真实图片与块生成的高分辨率图片,这里主要是保证所有残差快生成的都为高分辨率图像防止出现一些很不清晰一些很清晰最后得出较为清晰的图片这样就和失真的效果一样例如只有一张图片高清但是失真其他都模糊最后得出高清图片这就与直接输出相同了,因此要用损失函数进行约束,q代表块生成特征图,k代表批次















10-27
 6450
6450
6450
06-10
1021
1021
09-15
792
792
11-26
2219
2219
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









