







AI 绘画-PulID手办定制
1. 效果展示
本次测试主要结果展示如下:
- 牛仔风

- 古风

2. 基本原理
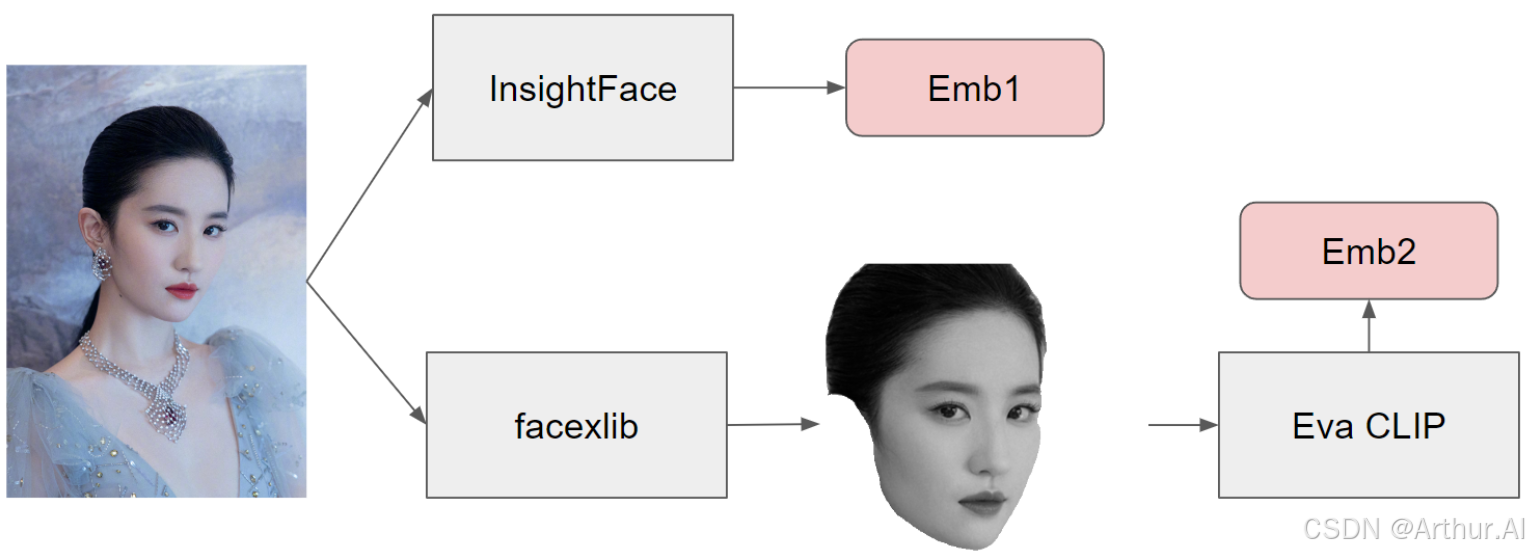
PuLID是一种类似于 ip-adapter 的恢复面部特征的方法。它同时使用 insightface 嵌入和 CLIP 嵌入,类似于 ip-adapter faceid plus 模型所做的。但是,在将图像传递给 CLIP 之前,还需要使用 facexlib 从背景环境中屏蔽面部。PuLID 还使用 Eva CLIP 而不是普通 CLIP。在 attn 覆盖中,PuLID 还做了比 IPAdapter 更多的事情,因为它将张量零填充并添加到隐藏状态的正交中。如果您有兴趣,可以阅读他们的论文,了解如何处理这个问题。
3. 环境安装
环境安装及依赖
pip install opencv-python transformers accelerate insightface
git clone https://github.com/ToTheBeginning/PuLID.git
cd PuLID
conda create --name pulid python=3.10
conda activate pulid
pip install -r requirements.txt
依赖模型下载
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="InstantX/PuLID", filename="ControlNetModel/config.json", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/PuLID", filename="ControlNetModel/diffusion_pytorch_model.safetensors", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/PuLID", filename="ip-adapter.bin", local_dir="./checkpoints")
4. 代码实现
主要测试代码:
核心部分需要调整的参数有:lora的权重、adapter的权重、prompt、negative_prompt以及输入图片的landmark信息
import sys
import cv2
import numpy as np
import torch
from pulid import attention_processor as attention
from pulid.pipeline import PuLIDPipeline
from pulid.utils import resize_numpy_image_long, seed_everything
torch.set_grad_enabled(False)
class PulidInference:
def __init__(self):
self.pipeline = PuLIDPipeline()
self.pipeline.pipe.load_lora_weights("../data/data282269/", weight_name="cute.safetensors", adapter_name="cute")
self.pipeline.pipe.set_adapters(["cute"], adapter_weights=[0.9])
# other params
self.DEFAULT_NEGATIVE_PROMPT = (
'flaws in the eyes, flaws in the face, flaws, lowres, non-HDRi, low quality, worst quality,'
'bad hands, bad fingers,artifacts noise, text, watermark, glitch, deformed, mutated, ugly, disfigured, '
'low resolution, partially rendered objects, deformed or partially rendered eyes, '
'deformed, deformed eyeballs, cross-eyed,blurry'
)
def run(self,*args):
id_image = args[0]
supp_images = args[1:4]
prompt, neg_prompt, scale, n_samples, seed, steps, H, W, id_scale, mode, id_mix = args[4:]
self.pipeline.debug_img_list = []
if mode == 'fidelity':
attention.NUM_ZERO = 8
attention.ORTHO = False
attention.ORTHO_v2 = True
elif mode == 'extremely style':
attention.NUM_ZERO = 16
attention.ORTHO = True
attention.ORTHO_v2 = False
else:
raise ValueError
if id_image is not None:
id_image = resize_numpy_image_long(id_image, 1024)
id_embeddings = self.pipeline.get_id_embedding(id_image)
for supp_id_image in supp_images:
if supp_id_image is not None:
supp_id_image = resize_numpy_image_long(supp_id_image, 1024)
supp_id_embeddings = self.pipeline.get_id_embedding(supp_id_image)
id_embeddings = torch.cat(
(id_embeddings, supp_id_embeddings if id_mix else supp_id_embeddings[:, :5]), dim=1
)
else:
id_embeddings = None
seed_everything(seed)
ims = []
for _ in range(n_samples):
img = self.pipeline.inference(prompt, (1, H, W), neg_prompt, id_embeddings, id_scale, scale, steps)[0]
ims.append(np.array(img))
return ims, self.pipeline.debug_img_list
def pulid_inference(self,face_image, prompt_in,neg_prompt_in,supp_images=None,seed = 55):
scale = 1.2
n_samples = 1
steps = 4
H, W = 1024, 768
id_scale = 0.99
mode = 'extremely style' #'fidelity', 'extremely style' (full body:1.2),slim,simple clothes, black dress,
id_mix = False #MG_ip,pixar,chibi,
prompt='MG_ip,pixar,chibi,portrait,cinematic, best quality,' + prompt_in #cinematic film, cinematic photo, realistic, portrait
neg_prompt = self.DEFAULT_NEGATIVE_PROMPT + neg_prompt_in
# face_image = cv2.imread('../y.jpg')
# cv2.cvtColor(face_image, cv2.COLOR_BGR2RGB, face_image)
#supp_image2 = cv2.imread('../fei3.jpg')
inps = [
face_image,
None,
None,
None,
prompt,
neg_prompt,
scale,
n_samples,
seed,
steps,
H,
W,
id_scale,
mode,
id_mix,
]
ims, debug_img = self.run(*inps)
return ims
if __name__ == '__main__':
pulid = PulidInference()
face_image = cv2.imread('./input3.jpg')
ims = pulid.pulid_inference(face_image, 'cinematic film, 1 girl')
for i in range(len(ims)):
cv2.cvtColor(ims[i], cv2.COLOR_BGR2RGB, ims[i])
cv2.imwrite(f'plu-a-{i}.jpg', ims[i])
实验结果:

5. 总结及扩展
添加不同的lora可以产生不同的效果,比如我们添加一个龙的背景lora,来生成不同风格的写真
import sys
import cv2
import numpy as np
import torch
from pulid import attention_processor as attention
from pulid.pipeline import PuLIDPipeline
from pulid.utils import resize_numpy_image_long, seed_everything
torch.set_grad_enabled(False)
class PulidInference:
def __init__(self):
self.pipeline = PuLIDPipeline()
self.pipeline.pipe.load_lora_weights("../data/data282269/", weight_name="cute.safetensors", adapter_name="cute")
self.pipeline.pipe.set_adapters(["cute"], adapter_weights=[0.9])
self.pipeline.pipe.load_lora_weights("../data/data283423/", weight_name="Sacred_beast_v2.3.safetensors", adapter_name="Sacred")
self.pipeline.pipe.set_adapters(["Sacred"], adapter_weights=[0.9])
# other params
self.DEFAULT_NEGATIVE_PROMPT = (
'flaws in the eyes, flaws in the face, flaws, lowres, non-HDRi, low quality, worst quality,'
'bad hands, bad fingers,artifacts noise, text, watermark, glitch, deformed, mutated, ugly, disfigured, '
'low resolution, partially rendered objects, deformed or partially rendered eyes, '
'deformed, deformed eyeballs, cross-eyed,blurry'
)
def run(self,*args):
id_image = args[0]
supp_images = args[1:4]
prompt, neg_prompt, scale, n_samples, seed, steps, H, W, id_scale, mode, id_mix = args[4:]
self.pipeline.debug_img_list = []
if mode == 'fidelity':
attention.NUM_ZERO = 8
attention.ORTHO = False
attention.ORTHO_v2 = True
elif mode == 'extremely style':
attention.NUM_ZERO = 16
attention.ORTHO = True
attention.ORTHO_v2 = False
else:
raise ValueError
if id_image is not None:
id_image = resize_numpy_image_long(id_image, 1024)
id_embeddings = self.pipeline.get_id_embedding(id_image)
for supp_id_image in supp_images:
if supp_id_image is not None:
supp_id_image = resize_numpy_image_long(supp_id_image, 1024)
supp_id_embeddings = self.pipeline.get_id_embedding(supp_id_image)
id_embeddings = torch.cat(
(id_embeddings, supp_id_embeddings if id_mix else supp_id_embeddings[:, :5]), dim=1
)
else:
id_embeddings = None
seed_everything(seed)
ims = []
for _ in range(n_samples):
img = self.pipeline.inference(prompt, (1, H, W), neg_prompt, id_embeddings, id_scale, scale, steps)[0]
ims.append(np.array(img))
return ims, self.pipeline.debug_img_list
def pulid_inference(self,face_image, prompt_in,neg_prompt_in,supp_images=None,seed = 55):
scale = 1.2
n_samples = 8
steps = 4
H, W = 1024, 768
id_scale = 0.99
mode = 'extremely style' #'fidelity', 'extremely style' (full body:1.2),slim,simple clothes, black dress,
id_mix = False #MG_ip,pixar,chibi,
prompt='MG_ip,pixar,chibi,portrait,cinematic, best quality,' + prompt_in #cinematic film, cinematic photo, realistic, portrait
neg_prompt = self.DEFAULT_NEGATIVE_PROMPT + neg_prompt_in
# face_image = cv2.imread('../y.jpg')
# cv2.cvtColor(face_image, cv2.COLOR_BGR2RGB, face_image)
#supp_image2 = cv2.imread('../fei3.jpg')
inps = [
face_image,
None,
None,
None,
prompt,
neg_prompt,
scale,
n_samples,
seed,
steps,
H,
W,
id_scale,
mode,
id_mix,
]
ims, debug_img = self.run(*inps)
return ims
if __name__ == '__main__':
pulid = PulidInference()
face_image = cv2.imread('./input3.jpg')
ims = pulid.pulid_inference(face_image, 'BJ_Sacred_beast, 1 girl, white hanfu dress,')
for i in range(len(ims)):
cv2.cvtColor(ims[i], cv2.COLOR_BGR2RGB, ims[i])
cv2.imwrite(f'plu-b-{i}.jpg', ims[i])
结果:

6. 资源链接
Online Demo
- Colab: https://github.com/camenduru/PuLID-jupyter provided by camenduru
- Replicate: https://replicate.com/zsxkib/pulid provided by zsxkib
ComfyUI
- https://github.com/cubiq/PuLID_ComfyUI provided by cubiq, native ComfyUI implementation
- https://github.com/ZHO-ZHO-ZHO/ComfyUI-PuLID-ZHO provided by ZHO, diffusers-based implementation
WebUI
- Mikubill/sd-webui-controlnet#2838 provided by huchenlei

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











