







文章转自微信公众号:【机器学习炼丹术】
参考目录:
- 论文名称:“Non-local Neural Networks”
- 论文地址:https://arxiv.org/abs/1711.07971
0 概述
首先,这个论文中的模块,叫做non-local block,然后这个思想是基于NLP中的self-attention自注意力机制的。所以在提到CV中的self-attention,最先想到的就是non-local这个论文。这个论文提出的动机如下:
卷积运算和递归操作都在空间或时间上处理一个local邻域;只有在重复应用这些运算、通过数据逐步传播信号时,才能捕获long-range相关性。
换句话说,在卷积网络中,想要增加视野域,就要不断的增加卷积层数量和池化层数量,换句话说,增加视野域就是增加网络的深度。这样必然会增加计算的成本,参数的数量,还需要考虑梯度消失问题。
- long-time相关性在NLP中,就是指一句话中,两个距离很远的单词的相关性,在CV中则是指一个图片中距离很远的两个部分的相关性。一般CNN识别物体,都是只关注物体周围的像素,而不会考虑很远的地方,这也就是CNN的一个特性,局部视野域。在某些情况下,这是天然优势,当然也可能变成劣势。
1 主要内容
本次我们学习先看代码,然后再从论文中解析代码。
1.1 Non local的优势
- 通过少的参数,少的层数,捕获远距离的依赖关系;
- 即插即用
1.2 pytorch复现
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
1.3 代码解读
输入特征图为BatchxChannelxHeightxWidth,我们先把这个输入特征图x分别放入:
- query卷积层,得到BatchxChannel//8xHeightxWidth
- key卷积层,得到BatchxChannel//8xHeightxWidth
- value卷积层,得到BatchxChannelxHeightxWidth
我们要逐个像素的计算query和key的相似度,然后相似度高的像素更为重要,相似度低的像素就不那么重要,每个像素我们用channel//8这个长度的向量来表示。(这里可能比较抽象,毕竟self-attention的原版是NLP领域的,non-local是从NLP中照搬过来的,所以不太好直接理解)
相似度计算是通过向量的乘法来表示的,那么我们肯定不能把这个HeightxWidth这么多像素一个一个计算像素的相似度。所以我们把BatchxChannel//8xHeightxWidth转换成BatchxChannel//8xN的形式,这里的N是HeightxWidth,N表示图中像素的数量。
然后我们用torch.bmm()来做矩阵的乘法:(N,Channel//8)和(Channel//8,N)两个矩阵相乘,得到一个(N,N)的矩阵。
这个(N,N)矩阵中的第i行第j列元素的值,是图中i位置像素和j位置像素的相关性!然后我们把value矩阵和这个(N,N)再进行一次矩阵乘法,这样得到的输出,就是考虑了全局信息的特征图了。
第二次矩阵乘法中,是(Channel,N)和(N,N)的相乘,得到的输出的特征图中的每一个值,都是N个值的加权平均,这也说明了输出的特征图中的每一个值,都是考虑了整张图的像素的。
1.4 论文解读
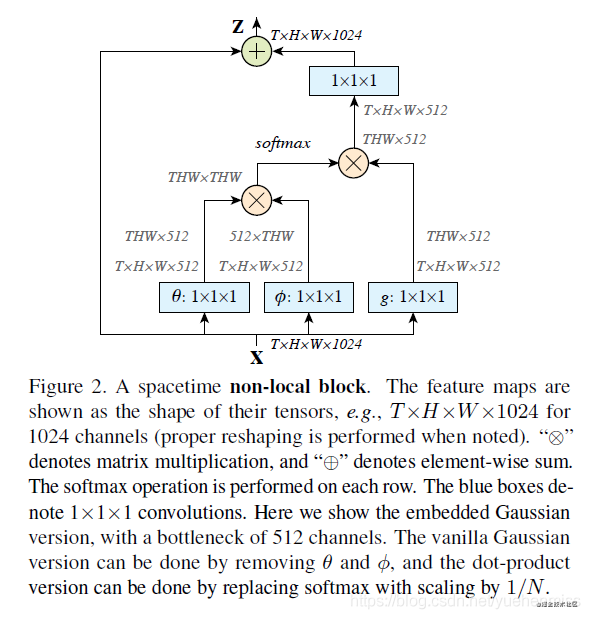
上图是论文中对于non-local的结构图。可以看到,先通过1x1的卷积,降低一下通道数,然后通过 θ 和 ϕ \theta和\phi θ和ϕ分别是query和key,然后这两个卷积得到(N,N)的矩阵,然后再与 g g g(value)进行矩阵乘法。
好吧我承认和代码在通道数上略微有些出入,但是大体思想相同。
2 总结
- 经过了non-local的特征图,视野域扩大到了全图,而且并没有增加很多的参数。
- 但是因为经过了BMM矩阵呢的乘法,梯度计算图急速扩大,因此计算和内存会消耗很大。因此,我在网络的深层(特征图尺寸较小的时候),才会加上一层non-local层。但是!!!论文中说,尽量放在靠前的层,所以在计算力允许的情况下,往前放。
- 这个方法在一部分的任务中,确实有提升,我自己试过,还可以。
- 后续又有很多来降低这个计算消耗的算法,之后我们在讲,喜欢的点个关注和赞吧~















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









