







 本文介绍了如何使用Python和小米手环6实现心跳数值在PC屏幕上实时显示。通过PULSOID应用将手环心跳数据传输到PC,并利用Websocket建立连接,展示在透明窗体上,方便用户随时关注健康状况。注意,此方法可能不适用于游戏场景,以免触发窗体检测导致封号。
本文介绍了如何使用Python和小米手环6实现心跳数值在PC屏幕上实时显示。通过PULSOID应用将手环心跳数据传输到PC,并利用Websocket建立连接,展示在透明窗体上,方便用户随时关注健康状况。注意,此方法可能不适用于游戏场景,以免触发窗体检测导致封号。
Mi_Smart_Band_6(小米手环6)心跳数值PC屏幕显示
INTRODUCE
为了让用户能明显的看到自己打游戏时的心动值(×,或者写代码时的心动值(ps:我在写这个项目的时候心动值一度到过130),等等,可以让用户快速了解自身状态并作出判断,也可以检测身体健康程度(这样就可以一天写24小时的代码了),还可以在项目的末尾增加心率过高或者过低自动求救的功能(未完成),目前网上都是用obs的浏览器源来进行直播时的心跳显示,这里我们是直接采用pyqt将获取的心跳显示于一个透明窗体直接置顶,这样就可以实时观看了。
TOOL
python+Mi_Smart_Band_6(原则上支持广播的手环应该都行)+PULSOID(Android也可以)
Start
1.将手环所测心跳传至PC
这里我们用了PULSOID,iOS用户可以直接在AppStore里面下载,Android用户可以前往Google下载。
PC端直接点击上方超链接过去注册登录就好了。
然后我们再对手机操作(以IOS为例)
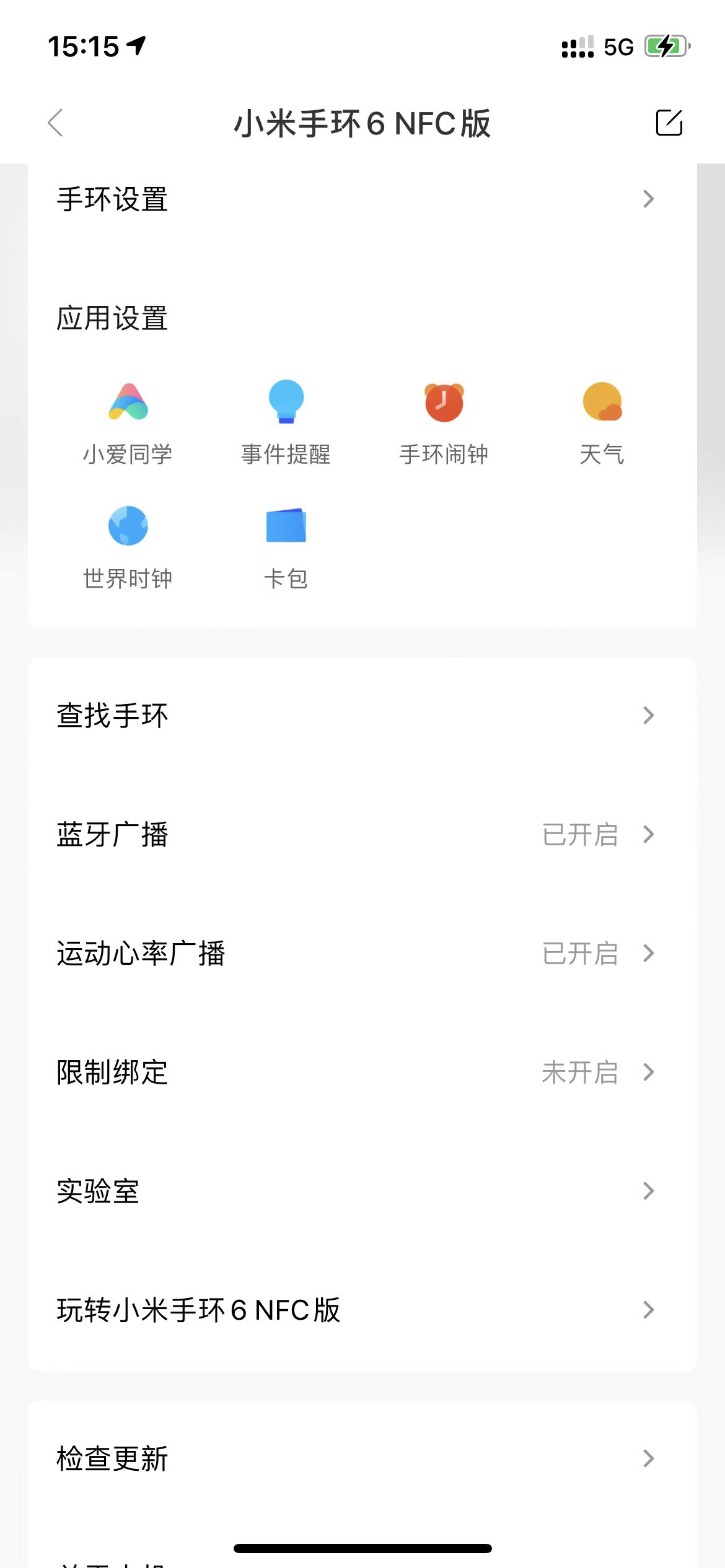
首先需要打开XiaoMiBand的蓝牙广播和运动心率广播
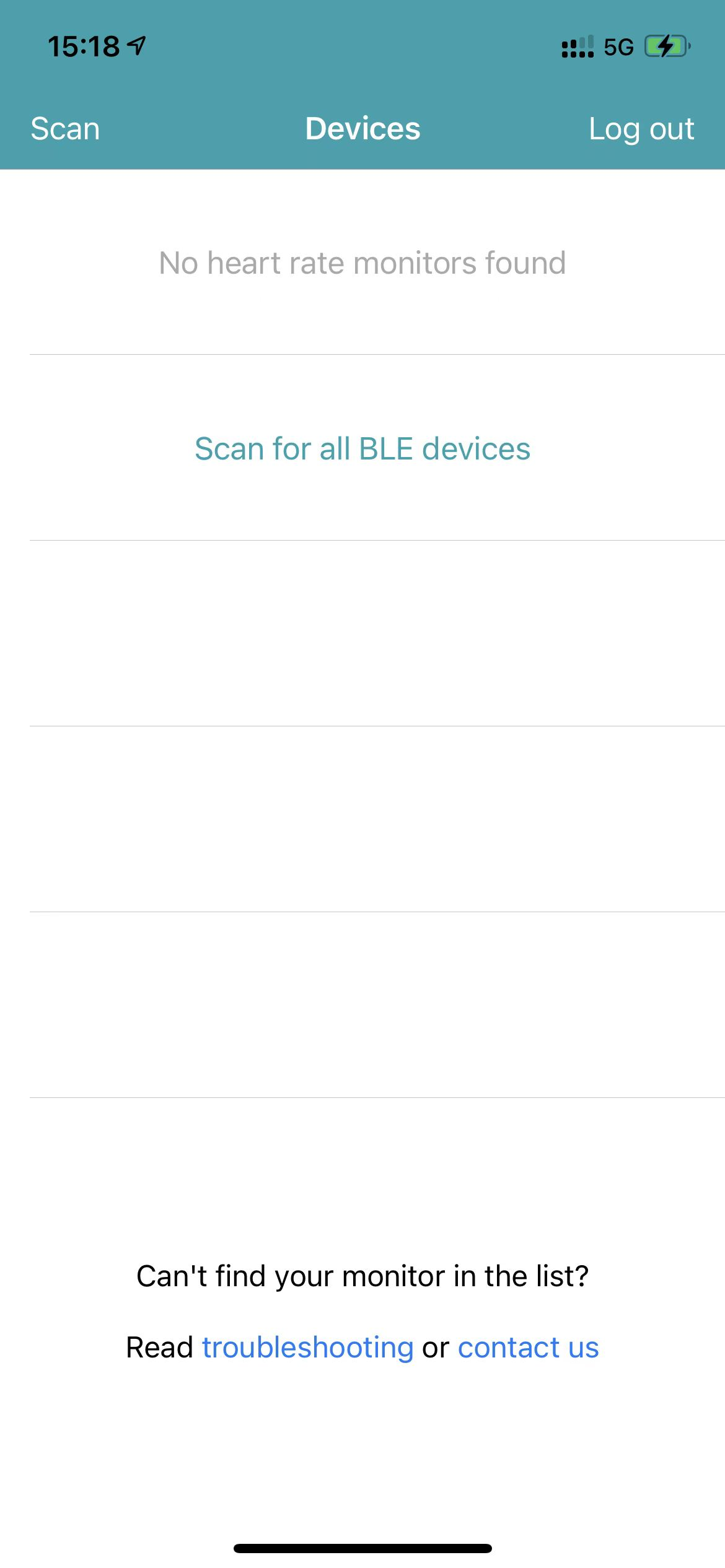
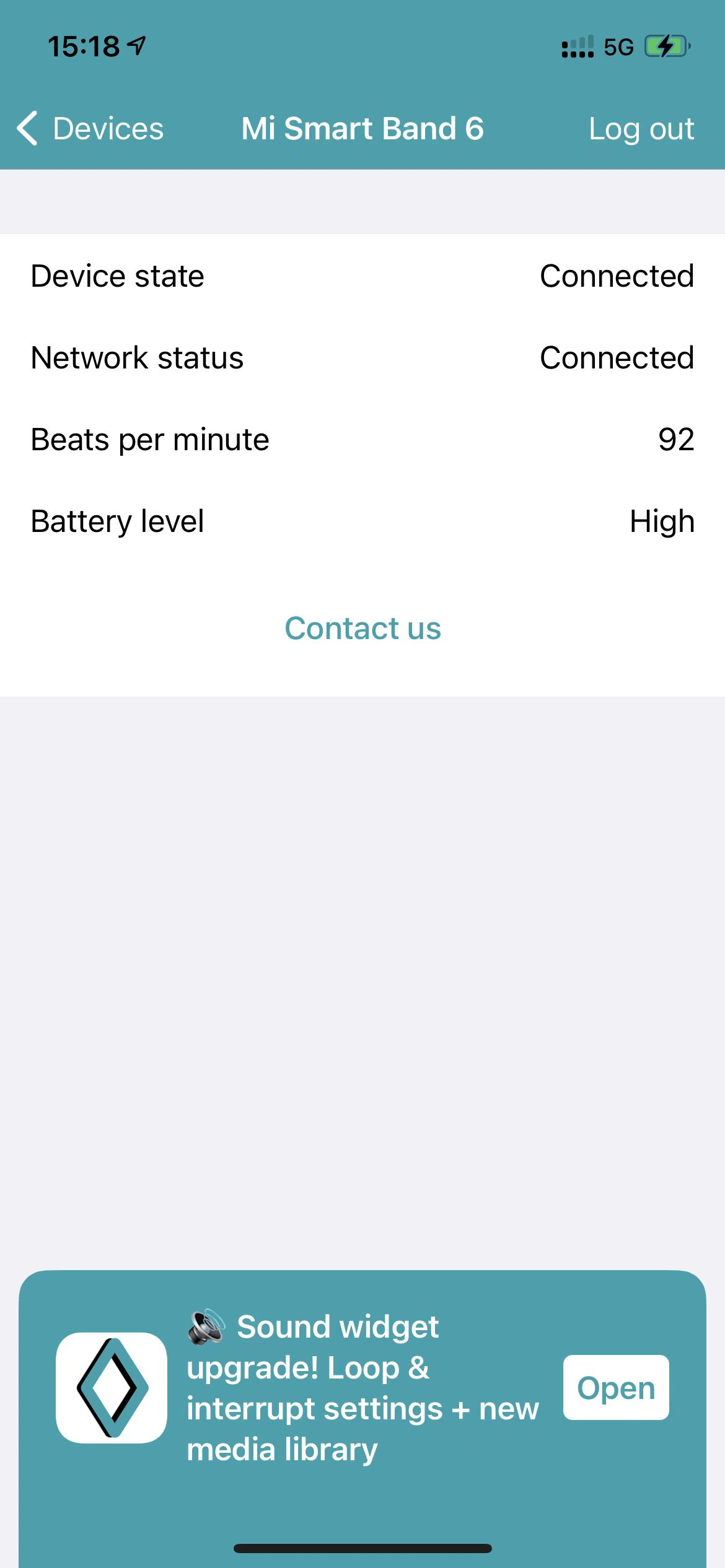
这里打开完毕之后来到PULSOID界面,登录完毕点击Scan for all BLE devices
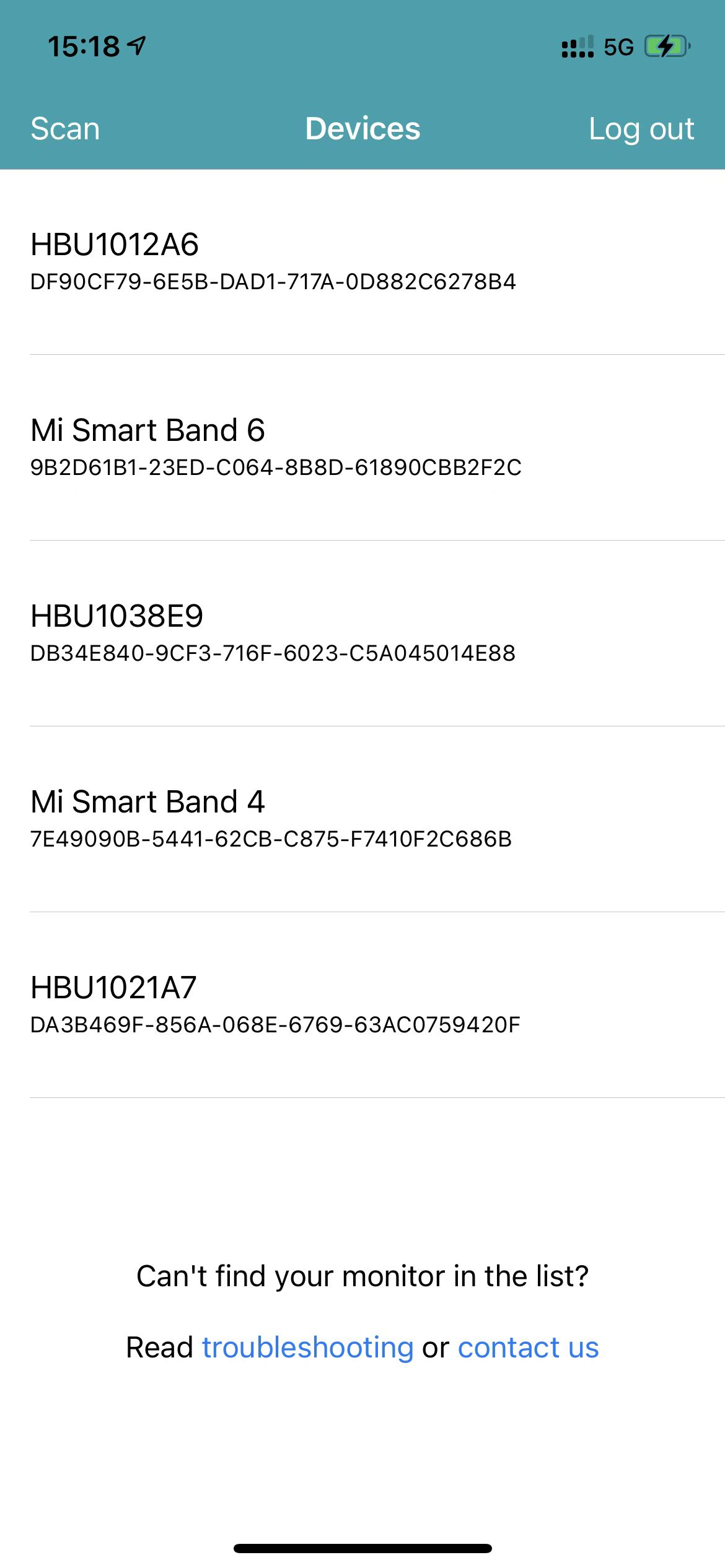
然后这里不出意外的话,应该可以看到我们的Mi_Smart_Band_6了,连接上去就好了
连接成功手机就没啥事儿了。
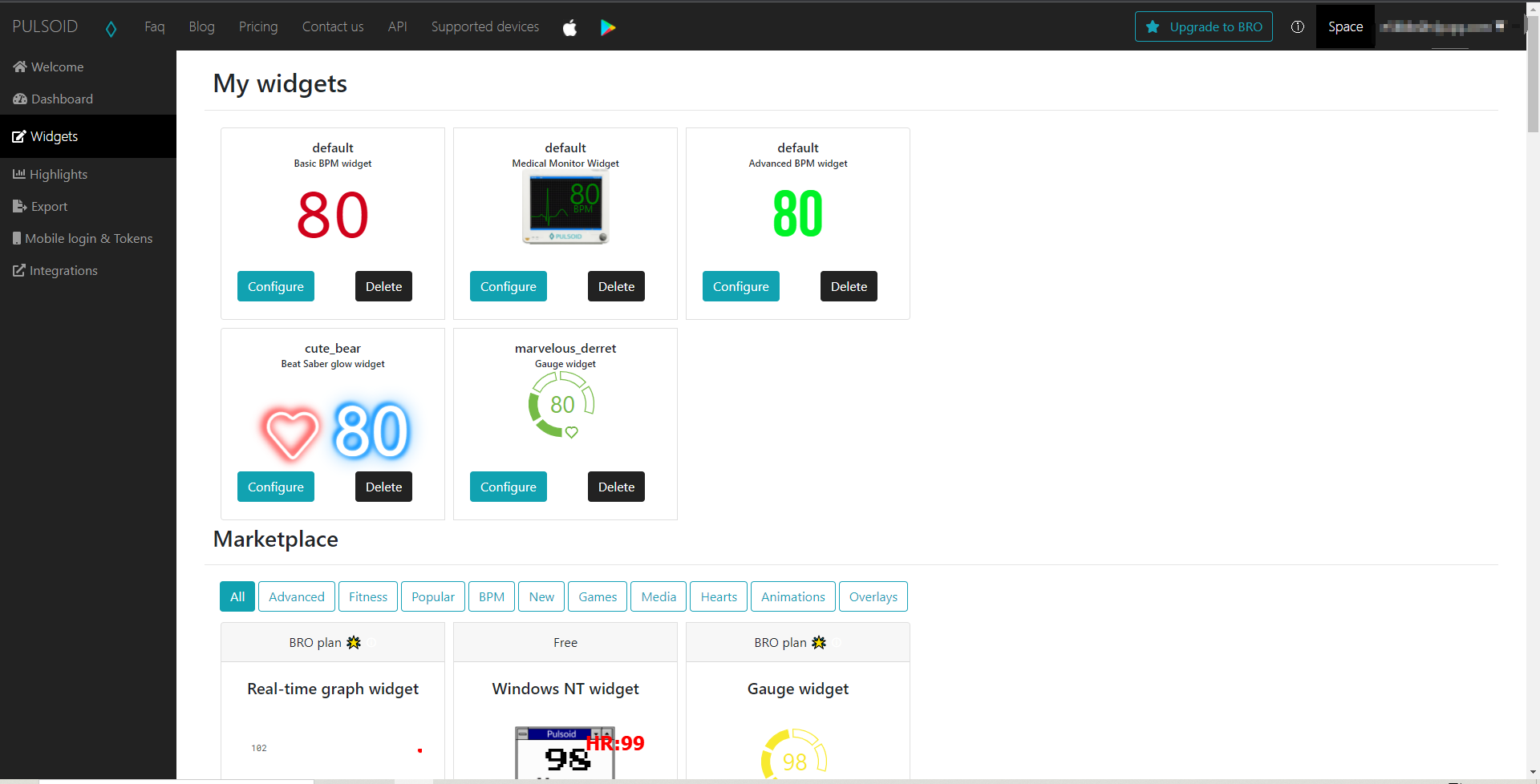
然后在PC端随便选一个Free的主题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ySUCuveE-1642142559358)(https://cdn.jsdelivr.net/gh/EaKal-7/Image_bag@main/img/20220113152721.png)]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









