









论文信息
- 作者:Chiang, Wei-Lin,Liu, Xuanqing,Si, Si...
- 出版信息: KDD '19: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data MiningJuly 2019 Pages 257–266https://doi.org/10.1145/3292500.3330925
- DOI: 10.1145/3292500.3330925
- 论文下载地址:https://dl.acm.org/doi/abs/10.1145/3292500.3330925
- 实验代码:PyTorch实现,GitHub。
目录
背景
- 图卷积网络(GCN)已经成功地应用于许多基于图的应用中;然而,训练一个大规模的GCN仍然具有挑战性。当前的基于随机梯度下降的算法要么计算成本高(随着GCN层数的增加呈指数增长),要么需要很大的空间来保存整个图并将每个节点嵌入到内存中。
- 小批量算法的效率可以用“嵌入利用率”的概念来描述,它与一个批量或批内的节点之间的链接数量成正比。
- 图聚类算法旨在构造节点的分区,从而使同一分区中的节点之间的图链接比不同分区中的节点之间的图链接更多。但对图进行分区后,删除了一些链接。因此,性能可能会受到影响。并且图形聚类算法倾向于将相似的节点聚在一起。因此,集群的分布可能与原始数据集不同,从而导致在执行SGD更新时对整个梯度的有偏估计。
创新点
- 训练图卷积网络的过程中,使用图聚类算法设计batches。
- 进一步提出了随机多聚类框架来提高Cluster-GCN的收敛性。
动机
- 在小批量处理SGD更新中,能否设计一个批处理和相应的计算子图来最大化嵌入利用率?作者通过将嵌入利用率的概念与簇目标联系起来回答了这个问题。
- 为了重新组合簇间的链接,减少不同批次间的方差,减少对SGD收敛的影响。
Cluster-GCN的工作原理
在每个步骤中,它对与图聚类算法识别的稠密子图相关联的节点块进行采样,并限制在该子图中进行邻域搜索。在构建批量进行SGD更新时,没有只考虑一个簇,而是随机选择q个簇。
图

图1 展示的是完整的图(左)和聚类分区的图(右)。可以看到,Cluster-GCN可以避免繁重的邻居搜索,并将重点放在每一个同簇中的邻居上。

表2展示了两种不同的节点分区策略:随机分区和聚类分区。大多数聚类分区批次的标签熵较低,表明每个批次内的标签分布是倾斜的;相比之下,同一批中随机划分有更大的标签熵。可以看出,在相同的epoch数量下,使用聚类划分可以达到更高的精度,这表明使用图聚类是很重要的,分区不应该是随机形成的。
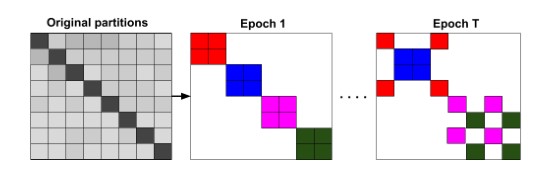
图3是随机多分区方案在Reddit上的实验过程,相同的色块在同一批次。在每个epoch中,随机采样q个簇(本例中使用q = 2)和簇间的链接,以形成一个新的批处理。说明了对于每个epoch,选择不同的簇组合作为一个批处理。以证明该方法的有效性。

图4是实验中用一个簇和多个簇作为batch的比较。前者使用300个分区。后者使用1500个,随机选择5个形成一批。epoch (x轴)和F1得分(y轴)。可以看到使用多个簇作为一个批处理可以提高收敛性。
优势
- 在规模方面,可以在大规模图数据上训练非常深的GCN。
- 在内存方面,只需存储当前批处理中的节点嵌入,即批处理的大小。
- 在计算复杂度方面,算法以梯度下降的方式达到了与邻域搜索方法相同的时间开销,并且比邻域搜索方法快得多。

- 在收敛速度方面,与其他基于sgd的方法相比是有竞争力的。
- GCN的第一篇论文[9](GCN开山之作:2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR)提出了全批次梯度下降(Full-batch gradient descent)。要计算整个梯度,它需要存储所有中间embeddings,,导致O(NFL)内存需求,这是不可扩展的。此外,虽然每个epoch的时间是有效的,但梯度下降的收敛速度较慢,因为每个epoch只更新一次参数。[memory: bad; time per epoch: good; convergence: bad]
- 在[5](SAGE:Inductive Representation Learning on Large Graphs)中提出了Mini-batch SGD。由于每次更新只基于一个mini-batch的梯度,它可以减少内存需求,并在每个epoch执行多次更新,从而加快了收敛速度。然而,由于邻居扩展问题,mini-batch SGD在计算L层单个节点的损失时引入了大量的计算开销,它要求节点的邻居节点在L-1层的embeddings,这又要求邻居节点在L-2层的embeddings,和在下游层的递归embeddings。这导致时间复杂度指数达到GCN深度。图SAGE[5](Inductive Representation Learning on Large Graphs)提出通过在层的反向传播过程中使用固定大小的邻居样本和FastGCN[1]提出的重要抽样,但这些方法的开销仍然很大,并且在GCN深入时会变得更糟。[memory: good; time per epoch: bad; convergence: good]
- VR-GCN[2]提出采用减少variance(方差)技术来减小邻域采样节点的大小。尽管成功地减小了采样大小(在文中的实验中,VR-GCN每个节点只有2个样本工作得很好),但它需要将所有节点的所有中间的embeddings存储在内存中,从而导致O(NFL) O(N F L)O(NFL)内存需求。如果图形中的节点数量增加到数百万个,那么对于VR-GCN的内存需求可能太高,无法适应GPU。[memory: bad; time per epoch: good; convergence: good]
- 最后,算法实现简单,因为我们只计算矩阵乘法,不需要邻域采样。
学习到的新知识
networkx 1.11
tqdm 4.28.1
numpy 1.15.4
pandas 0.23.4
texttable 1.5.0
scipy 1.1.0
argparse 1.1.0
torch 0.4.1
torch-geometric 0.3.1
metis 0.2a.4
scikit-learn 0.20
torch_spline_conv 1.0.4
torch_sparse 0.2.2
torch_scatter 1.0.4
torch_cluster 1.1.5Data
输入数据有三个csv文件,分别是:边 edges.csv,特征矩阵 features.csv 和 标签 target.csv。
- edges.csv:id1, id2
- features.csv :node_id, feature_id, value
- target.csv:node_id, target
GCN过程简述
对于一个图,GCN采用图卷积运算逐层地获取节点的embedding:在每一层,要获取一个节点的embedding,需要通过采集相邻节点的embedding,然后进行一层或几层线性变换和非线性激活。最后一层embedding将用于一些最终任务。例如,在节点分类问题中,最后一层embedding被传递给分类器来预测节点标签,从而可以对GCN的参数进行端到端的训练。















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









