







1.使用LogisticRegression建立模型
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
clf = LogisticRegression()
clf.fit(iris.data, iris.target)
2.计算准确率
👉方法一:
predicted = clf.predict(iris.data)
acc = sum(iris.target == predicted) / len(iris.target)
print("acc = ", acc) #acc = 0.96
👉方法二:
from sklearn.metrics import accuracy_score
acc = accuracy_score(iris.target, predicted)
print("acc = ", acc) #acc = 0.96
但在数据很不平衡时,准确率变得毫无意义。需要使用混淆矩阵来判断模型的性能。
3.建立混淆矩阵
from sklearn.metrics import confusion_matrix
m = confusion_matrix(iris.target, predicted)
print(m)
[[50 0 0]
[ 0 45 5]
[ 0 1 49]]
4.可视化呈现混淆矩阵
import seaborn
seaborn.heatmap(m)
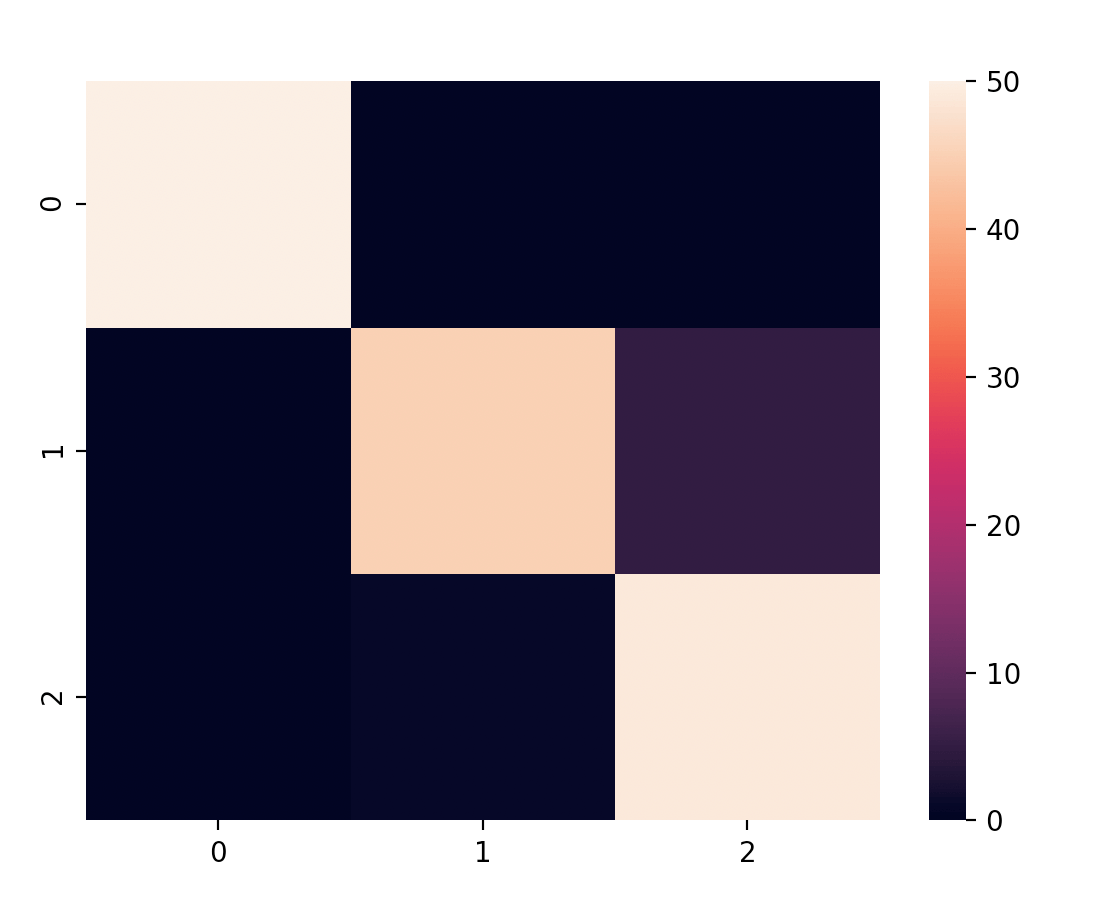
5.评估结果
计算查全率、查准率和F1:
from sklearn.metrics import classification_report
print(classification_report(iris.target, predicted))
precision recall f1-score support
0 1.00 1.00 1.00 50
1 0.98 0.90 0.94 50
2 0.91 0.98 0.94 50
avg / total 0.96 0.96 0.96 150
第0行的结果基于混淆矩阵:
50 0
0 100
第1行的结果基于混淆矩阵:
45 5
1 99
第2行的结果基于混淆矩阵:
49 1
5 95
6.代码地址
想要获取最新文章推送或者私聊谈人生,请关注我的个人微信公众号:⬇️x-jeff的AI工坊⬇️

个人博客网站:https://shichaoxin.com
GitHub:https://github.com/x-jeff


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









