






目录
背景
由于datahub官方支持摄取的数据源类型有限,对于一些当前不支持的数据源如何摄取元数据,本文将提供对应的写入手段

元数据摄取方式
对于官方支持的数据源直接在ingestion设置yml文件即可例行调度任务自动摄取,对于当前不支持的数据源采取python写入dataset信息的方式
创建新platform
datahub CLI
python -m datahub put platform --name sybase --display_name "Sybase" --logo "https://sybase图片的网址.jpg"--本文公司为内网放置图片建立连接,不做展示
运行上述脚本,即可创建平台,待向该platform写入dataset的数据后,首页会显示
写入单个dataset数据集
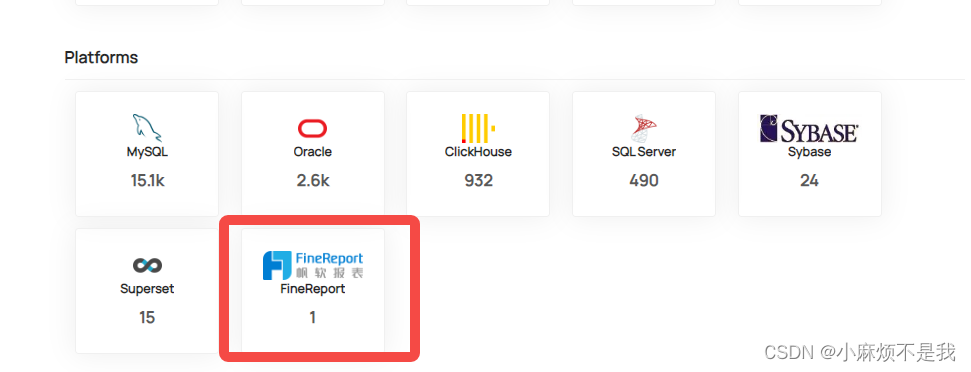
以finereport为例,首先先创建finereport的platform,同上述步骤
# Inlined from /metadata-ingestion/examples/library/dataset_schema.py
# Imports for urn construction utility methods
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
DateTypeClass,
OtherSchemaClass,
SchemaFieldClass,
SchemaFieldDataTypeClass,
SchemaMetadataClass,
StringTypeClass,
NumberTypeClass,
ArrayTypeClass,
BooleanTypeClass,
BytesTypeClass,
EnumTypeClass,
NullTypeClass,
TimeTypeClass,
)
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=make_dataset_urn(platform="finereport", name="query.oil.card", env="PROD"),
aspect=SchemaMetadataClass(
schemaName="card", # not used
platform=make_data_platform_urn("finereport"), # important <- platform must be an urn
version=0, # when the source system has a notion of versioning of schemas, insert this in, otherwise leave as 0
hash="", # when the source system has a notion of unique schemas identified via hash, include a hash, else leave it as empty string
platformSchema=OtherSchemaClass(rawSchema="__insert raw schema here__"),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
fields=[
SchemaFieldClass(
fieldPath="cardno",
type=SchemaFieldDataTypeClass(type=StringTypeClass()),
nativeDataType="CHAR(19)", # use this tquito provide the type of the field in the source system's vernacular
description="",
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
SchemaFieldClass(
fieldPath="opetime",
type=SchemaFieldDataTypeClass(type=DateTypeClass()),
nativeDataType="TIMESTAMP(23)",
description="",
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
SchemaFieldClass(
fieldPath="openo",
type=SchemaFieldDataTypeClass(type=NumberTypeClass()),
nativeDataType="INT(10)",
description="",
created=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
],
),
)
# Create rest emitter
rest_emitter = DatahubRestEmitter(gms_server="http://localhost:8080")
rest_emitter.emit(event)
执行上述脚本后,首页会显示该平台数据集数量,点击可看dataset详情
批量写入dataset
import pymysql
import json
import pandas as pd
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
DateTypeClass,
OtherSchemaClass,
SchemaFieldClass,
SchemaFieldDataTypeClass,
SchemaMetadataClass,
StringTypeClass,
NumberTypeClass,
ArrayTypeClass,
BooleanTypeClass,
BytesTypeClass,
EnumTypeClass,
NullTypeClass,
TimeTypeClass,
)
# 连接 MySQL 数据库
conn = pymysql.connect(
host='xxx', # 主机名
port=3306, # 端口号,MySQL默认为3306
user='xxx', # 用户名
password='xxx', # 密码
database='xxx', # 数据库名称
)
# 创建游标对象
cursor = conn.cursor()
# 执行 SQL 查询语句
cursor.execute("select * from metadata_tb_columns ")#获取数据源的库表及字段信息
# 获取查询结果
result_sql = cursor.fetchall()
# 将查询结果转化为 Pandas dataframe 对象
result_sql = pd.DataFrame(result_sql, columns=[i[0] for i in cursor.description])
# result_sql
result_sql.head()
datatype_dict={ 'int': 'NumberTypeClass',
'bigint': 'NumberTypeClass',
'numeric': 'NumberTypeClass',
'numeric identity': 'NumberTypeClass',
'Boolean': 'BooleanTypeClass',
'Binary': 'BytesTypeClass',
'varbinary': 'BytesTypeClass',
'binary': 'BytesTypeClass',
'array': 'ArrayTypeClass',
'ARRAY': 'ArrayTypeClass',
'char': 'StringTypeClass',
'varchar': 'StringTypeClass',
'Date': 'DateTypeClass',
'DATE': 'DateTypeClass',
'Time': 'TimeTypeClass',
'datetime': 'TimeTypeClass',
'DateTime': 'TimeTypeClass',
'DATETIME': 'TimeTypeClass',
'TIMESTAMP': 'TimeTypeClass',
'JSON': 'RecordTypeClass'}
platforms=result_sql.database_type.unique()
#遍历平台如sybase,finereport等
for i in platforms:
tb_df=result_sql[result_sql.database_type==i].reset_index(drop=True)
tables=tb_df.table_name.unique()
#遍历表
for j in tables:
tb=tb_df[tb_df.table_name==j].reset_index(drop=True)
database_name=tb.loc[0,'database_name']
table_schema=tb.loc[0,'table_schema']
table_description=tb.loc[0,'table_description']
if len(table_schema)>0:
tb_name=database_name+'.'+table_schema+'.'+j
else:
tb_name=database_name+'.'+j
b_code="""event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=make_dataset_urn(platform='{0}', name="{1}", env="PROD"),
aspect=SchemaMetadataClass(
schemaName="{2}",
# description="{3}",
platform=make_data_platform_urn("{0}"),
version=0,
hash="",
platformSchema=OtherSchemaClass(rawSchema="__insert raw schema here__"),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
fields=[""".format(i,tb_name,table_schema,table_description)
e_code="""],
),
)
# Create rest emitter
rest_emitter = DatahubRestEmitter(gms_server="http://localhost:8080")
rest_emitter.emit(event)
"""
mid_code_all=""
print('####table:',j)
#遍历列
for m in range(len(tb)):
column=tb.loc[m,'column_name']
data_type=tb.loc[m,'data_type'].replace('"','')
character_maximum_length=tb.loc[m,'character_maximum_length']
numeric_precision=tb.loc[m,'numeric_precision']
datetime_precision=tb.loc[m,'datetime_precision']
numeric_precision_radix=tb.loc[m,'numeric_precision_radix']
column_description=tb.loc[m,'column_description']
# datatype_class=eval(str(datatype_dict.get(data_type))+'()')
datatype_class=str(datatype_dict.get(data_type))+'()'
if data_type.lower() in ('varchar','char'):
dtype=data_type+'('+character_maximum_length+')'
elif data_type.lower() in ('int','bigint') or data_type[:7]=='numeric':
dtype=data_type+'('+numeric_precision+')'
elif data_type.lower() =='binary':
dtype=data_type+'('+numeric_precision+')'
elif data_type.lower() in ('date','datetime','time'):
dtype=data_type+'('+datetime_precision+')'
else :
dtype=data_type
mid_code="""
SchemaFieldClass(
fieldPath="{0}",
type=SchemaFieldDataTypeClass(type={1}),
nativeDataType='{2}',
description="",
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
""".format(column,datatype_class,dtype)
mid_code_all+=mid_code
print(column,datatype_class,dtype)
code=b_code+mid_code_all+e_code
exec(code)#转为代码执行
写入后平台显示如下
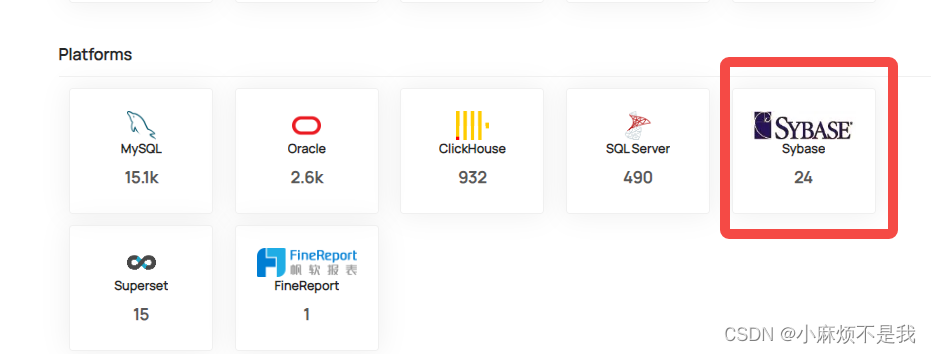

其他数据源类似
















 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









