







[1] Arandjelovic R, Gronat P, Torii A等. NetVLAD: CNN architecture for weakly supervised place recognition[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016, 2016-Decem: 5297–5307.
背景知识 典型场景
-
图像地理定位的目标是快速准确的识别给定查询照片的位置。如下图:

上图中,查询图像不带地理位置标签,数据库中的图片带有地理位置标签。 -
目前典型的应用场景包括:自动驾驶(根据街道图片辅助GPS进行更加精确的定位)、增强现实、军事等领域。是今年越来越火的计算机视觉方向。
-
这个任务目前有三个分支,分别是基于图像检索的图像地理定位、基于局部3D点云的图像地理定位和基于全局3D点云的图像地理定位。
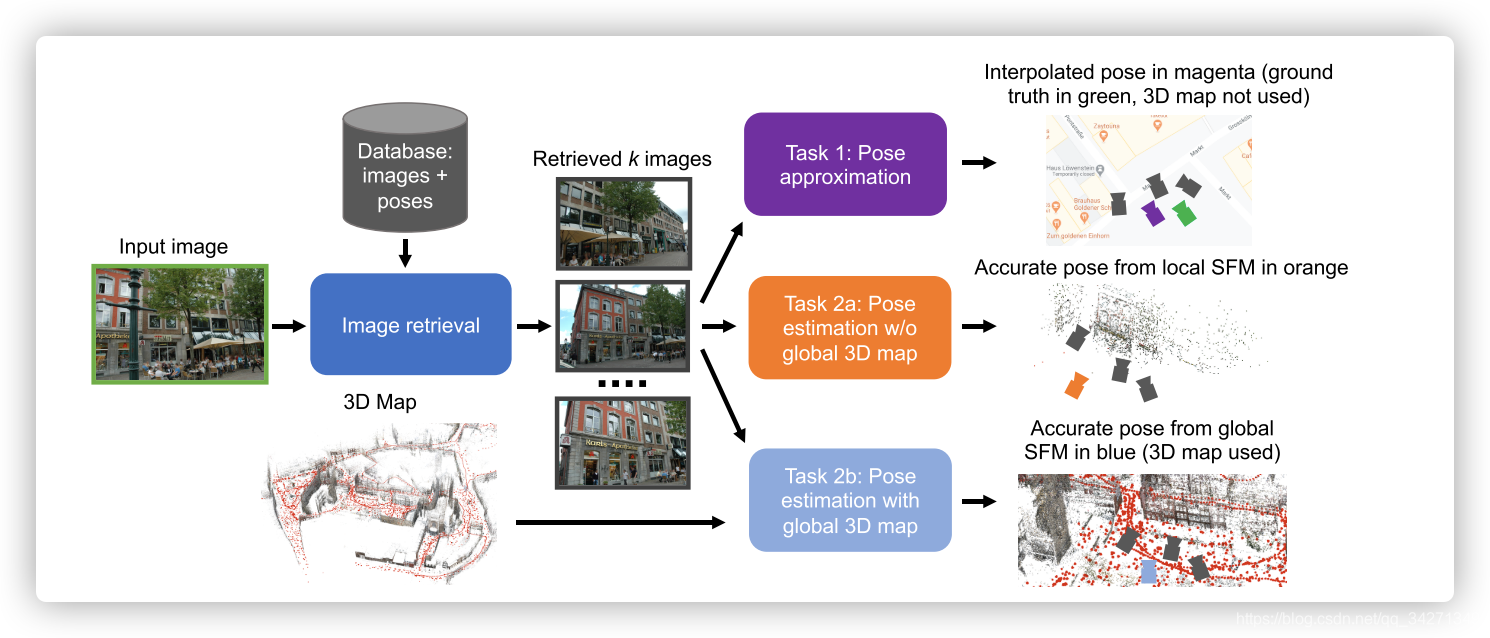
值得一提的是,在涉及到3D的方面,自动驾驶研究者也在积极进行相关研究,所以许多文章会出现自动化领域的术语。
在此方法之间,VLAD和BoW方法是典型的局部特征聚合方法。用于图像检索和图像分类,它捕获的是图像上局部描述符的统计信息。BoW是存储视觉词汇的个数,VLAD存储每个视觉词汇之间的残差。
创新点及解决的对应问题
- 将传统的用于此领域的方法VLAD进行了改进,使其可以通过神经网络进行训练。
在此提一下,VLAD方法的大致步骤为,提取图像的局部特征(如SIFT),将一张图像的多个局部特征进行聚类,得到k个聚类中心,每个聚类中心的多个特征聚合表达,最后将其组成一个矩阵( K × D K\times D K×D)。
- 因为用了神经网络,最后达到端到端的效果
- SOTA(2016年的SOTA)
用了什么样的方法
- 本文采用的是基于检索的图像地理定位方法。
- 核心点在于将VLAD变成一个CNN层,使得其可以集成到任意的CNN上。并且,作者在流行的CNN上作了实验。
核心思路为:用查询图像来检索图像库的图像(带有地理标记)。评分topk图像的地理标记作为查询到的地理位置。
- 图像特征提取器 f ( I i ) f(I_i) f(Ii)
对于任意图像
I
i
I_i
Ii,经过特征提取器后会得到一个固定维度的向量
f
(
I
i
)
f(I_i)
f(Ii)。
同样的,对查询图像也可以提取出
f
(
q
)
f(q)
f(q)(q代表查询图像,query image)。特征之间的相似度衡量用
f
(
q
)
f(q)
f(q)和
f
(
I
i
)
f(I_i)
f(Ii)之间的欧式距离(值得一提的是,也有方法将距离衡量指标改造为可学习的过程)。
在本方法之前,典型的提取过程为:
1.提取图像的SIFT描述符(多个)
2.将这些个点的描述符经过BoW或者VLAD的方法进行聚合。
本方法对照上述过程,将过程设计为可表示学习的方式:
- 利用典型CNN结构提取图像特征
- 构建可学习的VLAD层,使其可训练
- CNN结构
在图像检索领域中,构建网络结构最好的方式是遵从以下步骤:
- 提取局部特征
- 以无序的方式进行组合
从启发式的角度来考虑,这种方式可以适应有部分遮挡和旋转的图像。至于对光照和视角变换的适应,就需要具有这种鲁棒性的描述符。从多个尺度提取特征描述符可以提供尺度不变的特性。
明显,以上要考虑的要素比较多,开发一种端到端的方式才是大势所趋。
- 利用在图像检索领域表现比较好的卷积网络,去掉最后一层,看做特征提取器
- 最后一层的输出需要是: H × W × D H\times W \times D H×W×D,可以看做是在 H × W H\times W H×W的空域提取的 D D D维描述符。(这个其实是延续了VLAD的模式)
这里是文章的核心,现在将其拆解:
对于VLAD过程,对每张图像提取局部特征之后,形成 { x i } \{x_i\} {xi},其中每个元素都是 D D D维的局部描述符。将 { x i } \{x_i\} {xi}作为输入,然后K个聚类中心形成的集合 c k {c_k} ck作为VLAD的参数集,最后VLAD输出 K × D K\times D K×D的图像表示V.
设定一个图像表示为 K × D K\times D K×D矩阵,写作 V V V,将这个矩阵转换为向量,之后经过归一化,形成最后的图像表示。其中,V中的元素 ( i , j ) (i,j) (i,j)可以用如下的公式进行计算:
V ( j , k ) = ∑ i = 1 N a k ( x i ) ( x i ( j ) − c k ( j ) ) V(j,k) = \sum \limits_{i=1}^{N} a_k(x_i)(x_i(j)-c_k(j)) V(j,k)=i=1∑Nak(xi)(xi(j)−ck(j))
其中, x i ( j ) x_i(j) xi(j)代表了第i张图像描述符的的第j个维度的数值, c k ( j ) c_k(j) ck(j)则代表了第k个聚类中心的第j个维度的数值。 a k ( x i ) a_k(x_i) ak(xi)代表了描述符 x i x_i xi的第k个视觉词汇,如果它距离聚类中心 c k c_k ck最近,则 a k ( x i ) a_k(x_i) ak(xi)取1,否则则取0.
直观的看,V的每一列就代表一个聚类中心 k k k,这一列的表示形式为残差 ( x i − c k ) (x_i-c_k) (xi−ck)的和。然后将矩阵 V V V按列进行归一化(内部归一化),将其转化为向量,并最终对齐进行L2归一化。
可见,在VLAD方法中,一个图像的表示的任意一个元素其实就是同一个簇中的所有的局部特征描述符到聚类中心所在的特征描述符的残差相加。
对于NetVLAD过程,本质就是在CNN的一层模拟VLAD过程,并设计可训练的通用VLAD层NetVLAD.
VLAD的核心公式因为 a k ( x i ) a_k(x_i) ak(xi)的存在,不具有连续性,即不可导。因此需要对其进行改造:
a
‾
k
(
x
i
)
=
e
−
α
∥
x
i
−
c
k
∥
2
∑
k
’
e
−
α
∥
x
i
−
c
k
′
∥
2
\overline{a}_k(x_i) = \frac{e^{-\alpha \left\| x_i-c_k \right\|^2}}{\sum_{k’}e^{-\alpha\left\| x_i - c_{k'} \right\|^2}}
ak(xi)=∑k’e−α∥xi−ck′∥2e−α∥xi−ck∥2
具体过程如下:
- 将描述符 x i x_i xi的权重分配给簇 c k c_k ck, x i x_i xi越接近 c k c_k ck,则权重越高. 但是不管如何接近,也不管如何远离,这个 x i x_i xi对应的权重始终在 ( 0 , 1 ) (0,1) (0,1)之间,其中权重最高所对应的簇就是该 x i x_i xi所属的簇.
- 每个簇都给定一个参数 α \alpha α ,它的存在达到一种控制效果: 距离越远,响应越小
α → + ∞ \alpha \rightarrow +\infty α→+∞ 的时候,相当于完全将原始的VLAD进行了还原,此时最近接的簇为1,否则为0.
将公式(2)中的平方展开可以得到:(分子分母抵消
e
−
α
∥
x
i
∥
e^{-\alpha\left\| \boldsymbol{x}_i \right\|}
e−α∥xi∥)
a
‾
k
(
x
i
)
=
e
w
k
T
x
i
+
b
k
∑
k
′
e
w
k
′
T
+
b
k
′
\overline{a}_k(\boldsymbol{x_i}) = \frac{e^{\boldsymbol{w_k^T}\boldsymbol{x}_i+b_k}}{\sum_{k'}e^{\boldsymbol{w}_k'^T+b_{k'}}}
ak(xi)=∑k′ewk′T+bk′ewkTxi+bk
其中,向量
w
k
=
2
α
c
⃗
k
\boldsymbol{w}_k = 2\alpha\vec{c}_k
wk=2αck ,标量
b
k
=
−
α
∥
c
k
⃗
∥
2
b_k=-\alpha \left\| \vec{c_k} \right\|^2
bk=−α∥ck∥2 .
- NetVLAD的最终形式是将软分配插入的VLAD公式中:
V ( j , k ) = ∑ i = 1 N e w ⃗ k T x ⃗ i + b k ∑ k ′ e w ⃗ k ′ T + b k ′ ( x i ( j ) − c k ( j ) ) V(j,k) = \sum\limits_{i=1}^{N}\frac{e^{\vec{w}_k^T\vec{x}_i+b_k}}{\sum_{k'}e^{\vec{w}_{k'}^T+b_{k'}}}(x_i(j)-c_k(j)) V(j,k)=i=1∑N∑k′ewk′T+bk′ewkTxi+bk(xi(j)−ck(j))
其中, { w ⃗ k } , { b k } , { c ⃗ k } \{\vec{w}_k\},\{b_k\},\{\vec{c}_k\} {wk},{bk},{ck}是每个簇k需要训练的参数集.这是相比于原始VLAD方法的优势,更多的可训练参数意味着更高的灵活性. 通过特定算法将参数集合 { w ⃗ k , b k } \{\vec{w}_k,b_k\} {wk,bk}从 { c ⃗ k } \{\vec{c}_k\} {ck}中解耦. NetVLAD中的所有参数都可以针对特定的任务进行训练.
NetVLAD方法流程改为网络结构
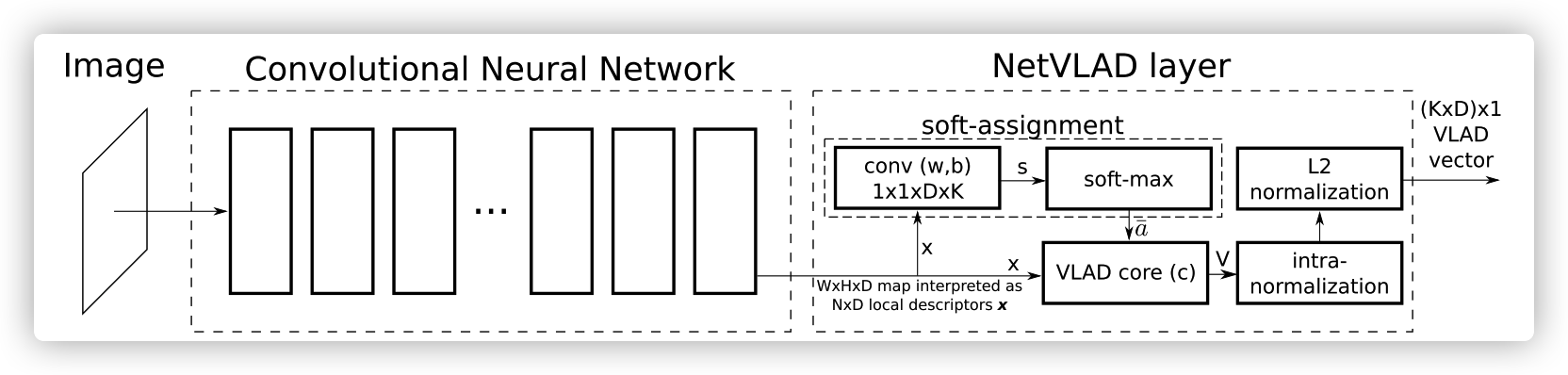
- 软分配函数(对应原始VLAD的符号函数)
此部分目的,确定每个 x i x_i xi对每个簇中心分配的权重
函数的形式为:
σ
(
z
⃗
)
=
e
z
k
∑
k
′
e
z
k
′
\sigma(\vec{z}) = \frac{e^{z_k}}{\sum_{k'}e^{z_{k'}}}
σ(z)=∑k′ezk′ezk
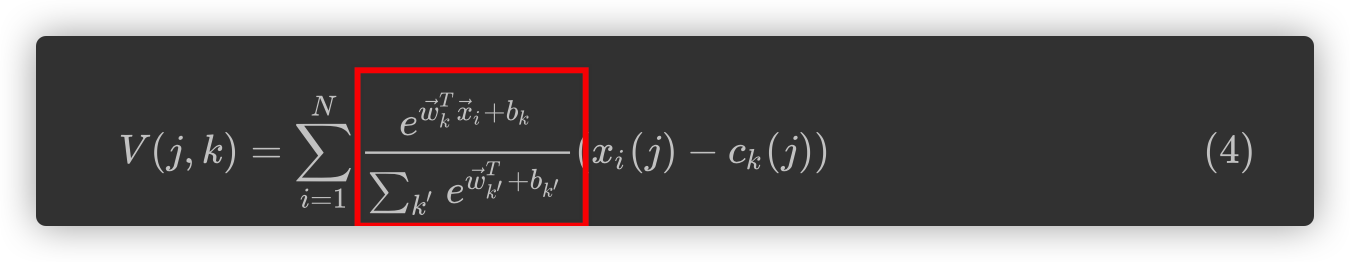
- 输入 { x i } \{x_i\} {xi} , { c k } \{c_k\} {ck}
- 设计满足形式 w ⃗ k T + b k \vec{w}_k^T+b_k wkT+bk格式的网络结构
- { x i } \{x_i\} {xi}由卷积神经网络提取的特征代替
- w ⃗ k {\vec{w}_k} wk 由 K K K个卷积核(带有偏置 b k b_k bk), 卷积 { x i } \{x_i\} {xi} 形成 w ⃗ k T x ⃗ i + b k \vec{w}_k^T\vec{x}_i+b_k wkTxi+bk
- 设计满足形式 e w ⃗ k T + b k ∑ k ’ e w ⃗ k ’ T + b k ′ \frac{e^{\vec{w}_k^T+b_k}}{\sum_{k’}e^{\vec{w}^T_{k’}+b_{k'}}} ∑k’ewk’T+bk′ewkT+bk 的网络结构
- 将之前卷积的结果加入一层softmax函数,就形成了需要的格式
- 之后归一化,形成 ( K × D ) × 1 (K\times D)\times 1 (K×D)×1 格式的描述符(描述整个图像)
此外,作者还进行了最大池化的操作.
- 在 H × W H\times W H×W 空间上的D维特征进行最大池化
- 生成D维的输出向量
- L2-normalized
- 表示学习,特定任务特定训练,VLAD性能优于最大基准
用了什么数据 如何训练网络
提到如何训练网络,除了各种超参数调节以外,额外的两个挑战一般包括:
- 如何获取合适的数据集
- 用什么损失函数比较靠谱
从GSVTM获取数据
GSVTM(Street View Time Machine)
这种数据提供了在地图上附件空间位置在不同时间拍摄的多个街道级全景图像.这种新颖的数据源对于IBL具有很高的价值. 同一个位置的照片是在不同的时间和季节拍摄的,从而为学习算法提供了重要的信息,可以发现哪些功能有用或分散注意力,以及图像的描述符对哪些变化具有鲁棒性.

数据如上图所示,每一列其实是一个地点,只不过从不同时间的全景图中生成. 这种数据利于训练描述符对于光照|视角|遮挡的鲁棒性.
Time Machine 图像集的缺点在于,它仅仅提供incomplete and noisy的supervision.
因为数据时从全景图中生成,每一个全景图都提供GPS坐标,但是从全景图中生成的部分图像之间却并不提供相应的对应关系.因为,每一个全景图都是由不同的地点|不同的角度拍摄的图像拼接而成. 而这些图像都具有GPS标签,并且最开始的时候可能并不是用来特别描述我们需要的图像的.
基于以上原因,GPS信息这个约束啊,只能去除掉哪些地理位置明显远( d e f i n i t e n e g a t i v e s { n j q } definite \quad negatives \{n_j^q\} definitenegatives{njq})的图像,也可以保留住那些地理位置近(或许长得并不像)( p o t e n t i a l p o s i t i v e s { p i q } potential \quad positives \quad \{p_i^q\} potentialpositives{piq})
三元组损失函数
我们希望训练出一个函数 f θ f_\theta fθ , 它可以优化位置识别性能. 也就是说,对于给定的测试查询图像 q q q,训练目标是距离越近,排名越高,反之,则越远.
形式化描述:
图像数据集
{
I
}
\{I\}
{I} , 查询图像
q
q
q , 最近邻图像(在特定范围内的图像)
I
i
∗
I_i*
Ii∗, 其余图像
I
i
I_i
Ii, 训练目标为,在欧式空间中:
d
θ
(
q
,
I
i
∗
)
<
d
θ
(
q
,
I
i
)
d_\theta(q,I_{i*}) < d_\theta (q,I_i)
dθ(q,Ii∗)<dθ(q,Ii)
下面,我们根据这个标准来形成三元组损失:
- 从数据源GSVTM中收集数据 q , { p i q } , { n j q } {q,\{p_i^q\},\{n_j^q\}} q,{piq},{njq}
- { p i q } \{p_i^q\} {piq} 中至少包含一张positive图像可以匹配查询图像. 但是我们不确切的知道是哪一张.
- 形式化表示这张图像:
p i ∗ q = arg min p i q d θ ( q , p i q ) p_{i*}^q = \mathop{\arg \min}\limits_{p_i^q}d_{\theta}(q,p_i^q) pi∗q=piqargmindθ(q,piq)
- 训练目标为: 对于每个训练元组 ( q , { p i q } , { n j q } ) (q,\{p_i^q\},\{n_j^q\}) (q,{piq},{njq}),学习一个图像表示函数 f θ f_{\theta} fθ,使得
d θ ( q , p i ∗ q ) < d θ ( q , n j q ) , ∀ j d_\theta (q,p_{i*}^q) < d_\theta(q,n_j^q), \quad \forall j dθ(q,pi∗q)<dθ(q,njq),∀j
- 定义损失函数:
对于训练元组
(
q
,
{
p
i
q
}
,
{
n
j
q
}
)
(q,\{p_i^q\},\{n_j^q\})
(q,{piq},{njq}) ,损失函数为:
L
θ
=
∑
j
m
a
x
(
(
min
i
d
θ
2
(
q
,
p
i
q
)
+
m
−
d
θ
2
(
q
,
n
j
q
)
)
,
0
)
L_{\theta} = \sum_j max\left( \left(\mathop{\min}\limits_i d_{\theta}^2(q,p_i^q)+m-d_{\theta}^2(q,n_j^q)\right) ,0\right)
Lθ=j∑max((imindθ2(q,piq)+m−dθ2(q,njq)),0)
我们直观的看一下这个函数,一旦某个训练元组固定了,在一次训练中,参数也是定的,此时公式中唯一的变量只有
d
θ
2
(
q
,
n
j
q
)
d_\theta^2(q,n_j^q)
dθ2(q,njq) , 这个部分随着迭代变量j的改变,在累加符号的作用下而迭代增加其负值.
因为 m a x max max 的作用所在,如果 d θ 2 ( q , n j q ) < d θ 2 ( q , n j q ) d_{\theta}^2(q,n_j^q) < d_{\theta}^2(q,n_j^q) dθ2(q,njq)<dθ2(q,njq) 说明情况正常,此时loss为0. 相反,离的越远(negative 违反正常情况的样本越多),loss越多.
我们使用SGD的方式来训练参数集 θ \theta θ
采样怎样的评估指标
评估所用的数据集
- Pittsburgh(Pitts250k) 包含从谷歌街景下载的250k数据集图像和从街景生成的24k查询图像,这些图像的拍摄时间跨度很大,长达数年. 本文将这些数据集划分成了3个大致相等的部分,用于训练\验证和测试,每个子集大概包含83k数据库图像和8k查询图像, 在地里上进行划分,确保集合包含独立的图像. 为了方便更快的训练,对于一些实验,使用了一个较小的自己(Pitts30K),在每个train/test/valid集合中包含10k的数据库图像. 并且这些图像在地里上也是不相交的.
- Tokyo 24/7 包含76k个数据库图像和315个查询图像,查询图像是在白天|日落|晚上的时候拍摄的,但是数据库图像只在白天拍摄,因为它们来自谷歌街景. 为了形成合适的train|valid 集合 , 作者使用GSVTM的数据进行了补充. 形成了新的数据集:TokyoTM.
评估用的指标
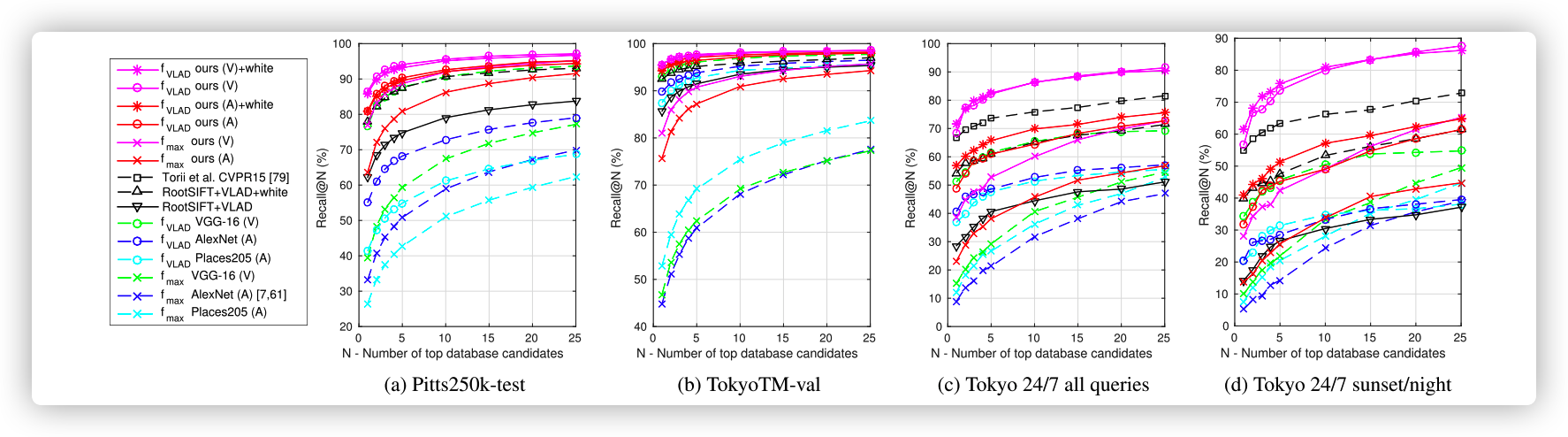
如果检索到的前k个图像中,至少有一个与查询图像的真实距离小于25米,则查询图像被视为正确定位. 称为Recall@k , 最后画出Recall@k的正确率曲线.
实现细节
大致思路
- 两种CNN架构AlexNet , VGG16 分别提取图像的特征,
- 前两种架构都去掉最后一层(ReLu之前)
- 按照前面所述的NetVLAD, 对两种结构分别生成16k和32k-D的图像表示.
代码复现(待续)
结果分析
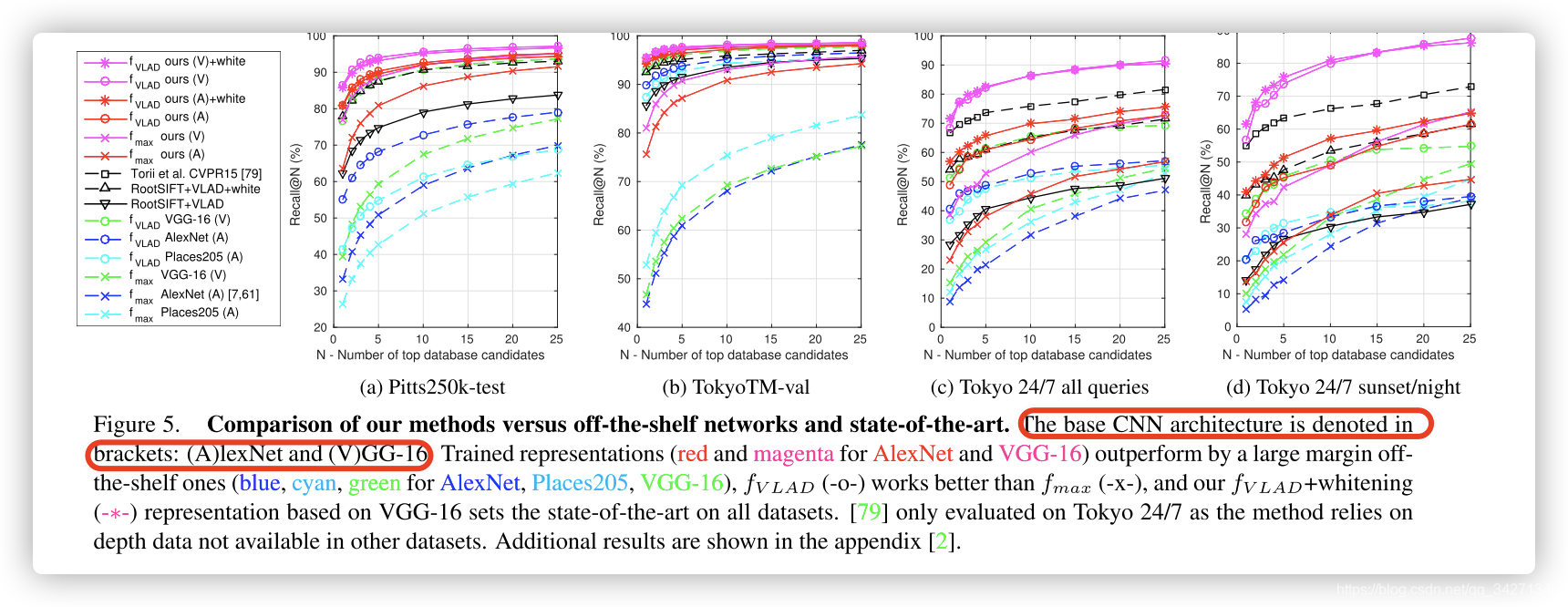
- baselines and SOTA:
- 将本文网络与在其他图像表示上预训练过的网络进行针对此任务的对比
- 也就是说,将其他的预训练网络裁剪掉最后一层,然后经过最大池化或者VLAD聚合向量,但是不执行进一步的训练.
- 三个基本网络是AlexNet ,VGG16 和 Places205,最后加上NetVLAD
- 其他局部描述符(RootSIFT)经过VLAD池化后作对比
- 本文方法与上述方法的各个方面的对比
- 降维: PCA
- End-End 训练
在两个基准测试集上, 经过训练的位置识别最终表现都大大优于基准测试. 证明:
i)我们的方法可以学习丰富而紧凑的图像表示的位置识别
ii) 使用现成的预训练网络并不是最优的方法,可能归因于欧式距离的应用
- 我们基于VGG-16的训练的 f V L A D f_{VLAD} fVLAD 的结果优于SIFT+VLAD+ whitening,
总结
- 将VLAD变成可训练的CNN层
- 端到端训练


















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











