






这里写目录标题
- 概述
- Abstract
- 1. Introduction 介绍
- 2. Related Work 相关工作
- 3. Methodology 方法
- 4. Experimental Results 实验结果
概述
Patch-NetVLAD:局部-全局描述符的多尺度融合
代码地址
论文地址
摘要本文讨论了一篇关于Patch NetVLAD的研究论文,这是一个结合了局部和全局描述符的视觉位置识别系统,用于图像检索。本文介绍了该方法、评估结果以及与其他最先进方法的比较。它还包括补充材料和其他细节、实验结果和分析。Patch NetVLAD在各种数据集和场景中展示了卓越的性能、稳健性和适应性。
后半部分
研究内容
本文来自CVPR 2021,是一个全局特征匹配算法(粗定位),传统方法的代表是BoW,本文使用深度学习的方法。
Abstract
第一段(介绍本文算法大致结构与优点)
Visual Place Recognition is a challenging task for robotics and autonomous systems, which must deal with the twin problems of appearance and viewpoint change in an always changing world.
视觉位置识别是机器人和自主系统的一项具有挑战性的任务,它必须在不断变化的世界中处理外观和视点变化的双重问题。
This paper introduces PatchNetVLAD, which provides a novel formulation for combining the advantages of both local and global descriptor methods by deriving patch-level features from NetVLAD residuals.
本文介绍了PatchNetVLAD,它通过从NetVLAD残差中提取补丁级特征,提供了一种结合局部描述符方法和全局描述符方法优点的新公式。
Unlike the fixed spatial neighborhood regime of existing local keypoint features, our method enables aggregation and matching of deep-learned local features defined over the feature-space grid.
与现有局部关键点特征的固定空间邻域制度不同,我们的方法可以在特征空间网格上定义深度学习的局部特征进行聚合和匹配。
We further introduce a multi-scale fusion of patch features that have complementary scales
(i.e. patch sizes) via an integral feature space and show that the fused features are highly invariant to both condition (season, structure, and illumination) and viewpoint (translation and rotation) changes.
我们进一步通过积分特征空间引入具有互补尺度(即斑块大小)的斑块特征的多尺度融合,并表明融合的特征对条件(季节、结构和光照)和视点(平移和旋转)变化都具有高度不变性。
Patch-NetVLAD outperforms both global and local feature descriptor-based methods with
comparable compute, achieving state-of-the-art visual place recognition results on a range of challenging real-world datasets, including winning the Facebook Mapillary Visual Place Recognition Challenge at ECCV2020.
Patch-NetVLAD的计算能力优于基于全局和局部特征描述符的方法,在一系列具有挑战性的现实世界数据集上获得了最先进的视觉位置识别结果,包括在ECCV2020上赢得Facebook Mapillary视觉位置识别挑战赛。
It is also adaptable to user requirements, with a speed-optimised version operating over an order of magnitude faster than the stateof-the-art.
它还可以适应用户需求,其速度优化版本的运行速度比最先进的版本快一个数量级。
By combining superior performance with improved computational efficiency in a configurable framework, Patch-NetVLAD is well suited to enhance both stand-alone place recognition capabilities and the overall performance of SLAM systems.
通过在可配置框架中结合优越的性能和改进的计算效率,Patch-NetVLAD非常适合增强独立位置识别能力和SLAM系统的整体性能。
1. Introduction 介绍
第一段(介绍视觉位置识别的重要性)
Visual Place Recognition (VPR) is a key prerequisite for many robotics and autonomous system applications, both as a stand-alone positioning capability when using a prior map and as a key component of full Simultaneous Localization And Mapping (SLAM) systems.
视觉位置识别(VPR)是许多机器人和自主系统应用的关键先决条件,既是使用先验地图时的独立定位能力,也是完整的同步定位和绘图(SLAM)系统的关键组成部分。
The task can prove challenging because of major changes in appearance, illumination and even viewpoint, and is therefore an area of active research in both the computer vision [3, 19, 32, 40, 76, 78, 79] and robotics [10, 11, 12, 25, 36, 42] communities.
由于外观、光照甚至视角都会发生重大变化,因此这项任务极具挑战性,也是计算机视觉[3, 19, 32, 40, 76, 78, 79]和机器人[10, 11, 12, 25, 36, 42]界积极研究的一个领域。
第二段(VPR的两种常见方法,本文方法结合了两种方法)
VPR is typically framed as an image retrieval task [42, 56,73], where, given a query image, the most similar databaseimage (alongside associated metadata such as the camerapose) is retrieved.
VPR通常被定义为图像检索任务[42,56,73],其中,给定查询图像,检索最相似的数据库图像(以及相机姿势等相关元数据)。
There are two common ways to represent the query and reference images: using global descriptors which describe the whole image [3, 76, 25, 56, 10, 55, 79], or using local descriptors that describe areas of interest [20, 49, 18, 23, 14].
有两种常见的方法来表示查询和参考图像:使用全局描述符来描述整个图像[3,76,25,56,10,55,79],或者使用局部描述符来描述感兴趣的区域[20,49,18,23,14]。
Global descriptor matching is typically performed using nearest neighbor search between query
and reference images.
全局描述符匹配通常使用查询图像和参考图像之间的最近邻搜索来执行。
These global descriptors typically excel in terms of their robustness to appearance and illumination changes, as they are directly optimized for place recognition [3, 56].
这些全局描述符通常在对外观和光照变化的鲁棒性方面表现出色,因为它们直接针对位置识别进行了优化[3,56]。
Conversely, local descriptors are usually cross-matched, followed by geometric verification.
相反,局部描述符通常是交叉匹配的,然后是几何验证。
Local descriptor techniques prioritize spatial precision, predominantly on a pixel-scale level, using a fixed-size spatial neighborhood to facilitate highly-accurate 6-DoF pose estimation.
局部描述符技术优先考虑空间精度,主要是在像素尺度上,使用固定大小的空间邻域来促进高精度的 6-DoF 姿势估计。
Given the complementary strengths of local and global approaches, there has been little research [9, 62, 73] attempting to combine them.
鉴于局部方法和全局方法的互补优势,尝试将它们结合起来的研究[9, 62, 73]并不多。
The novel Patch-NetVLAD system proposed here combines the mutual strengths of local and global approaches while minimizing their weaknesses
本文提出的新型 Patch-NetVLAD 系统结合了局部和全局方法的共同优势,同时最大限度地减少了它们的缺点。
第三段(本文贡献)
To achieve this goal, we make a number of contributions(see Fig. 1):
为了实现这一目标,我们做出了许多贡献(见图1):
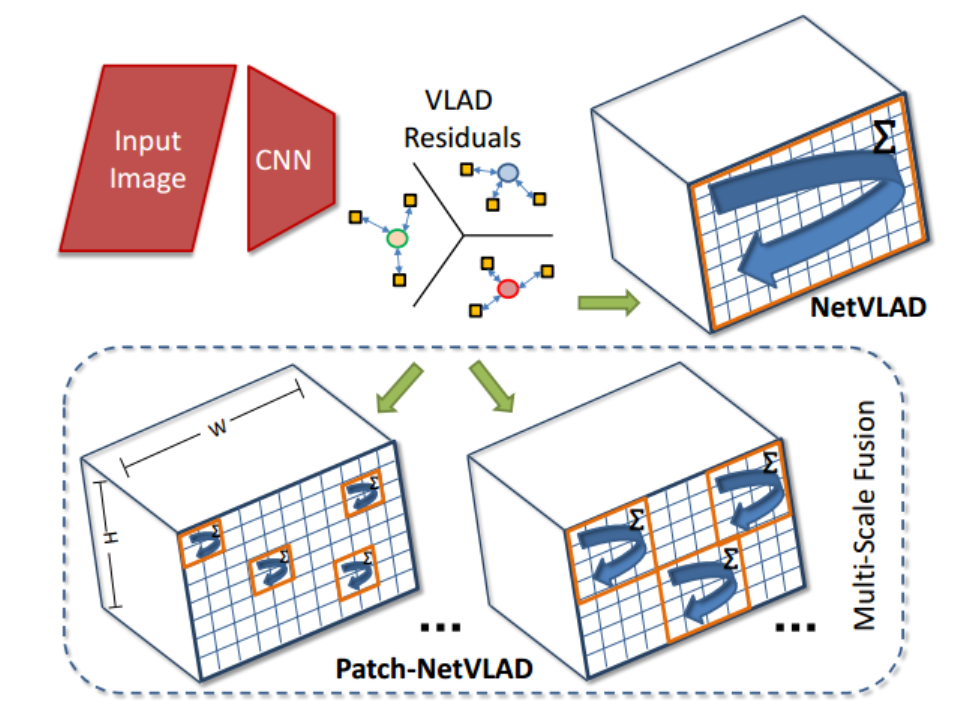
Figure 1. Patch-NetVLAD is a novel condition and viewpoint invariant visual place recognition system that produces a similarity score between two images through local matching of locally-global descriptors extracted from a set of patches in the feature space of each image.
图1所示。Patch-NetVLAD是一种新的条件和视点不变的视觉位置识别系统,它通过从每幅图像的特征空间中提取一组局部全局描述符的局部匹配来产生两幅图像之间的相似度评分。
Furthermore, by introducing an integral feature space, we are able to derive a multi-scale approach that fuses multiple patch sizes.
此外,通过引入积分特征空间,我们能够推导出融合多个补丁大小的多尺度方法。
This is in contrast with the original NetVLAD paper, which performs an appearance only aggregation of the whole feature space into a single global descriptor.
这与最初的NetVLAD论文形成对比,后者将整个特征空间仅进行外观聚合到单个全局描述符中。
First, we introduce a novel place recognition system that generates a similarity score between an image pair through a spatial score obtained through exhaustive matching of locally-global descriptors.
首先,我们引入了一种新的位置识别系统,该系统通过对局部全局描述符进行穷举匹配获得的空间分数来生成图像对之间的相似性分数。
These descriptors are extracted for densely-sampled local patches within the feature space using a VPR-optimized aggregation technique (in this case NetVLAD [3]).
这些描述符是使用vpr优化的聚合技术(在本例中为NetVLAD[3])在特征空间中为密集采样的局部补丁提取的。
Second, we propose a multi-scale fusion technique that generates and combines these hybrid descriptors of different sizes to achieve improved performance over a single scale approach.
其次,我们提出了一种多尺度融合技术,该技术生成并组合这些不同大小的混合描述符,以实现比单尺度方法更高的性能。
To minimize the computational growth implications of moving to a multi-scale approach, we develop an integral feature space (analogous to integral images) to derive the local features for varying patch sizes.
为了最大限度地减少迁移到多尺度方法对计算增长的影响,我们开发了一个积分特征空间(类似于积分图像)来推导不同斑块大小的局部特征。
Together these contributions provide users with flexibility based on their task requirements: our final contribution is the demonstration of a range of easily implemented system configurations that achieve different performance and computational balances, including a performance-focused
configuration that outperforms the state-of-the-art recall performance while being slightly faster, a balanced configuration that performs as well as the state-of-the-art while being 3× faster and a speed-focused configuration that is an order of magnitude faster than the state-of-the-art.
这些贡献共同为用户提供了基于其任务需求的灵活性:我们最后的贡献是演示了一系列容易实现的系统配置,这些配置实现了不同的性能和计算平衡,包括以性能为中心的配置,它比最先进的召回性能要好一些,但速度略快;一个平衡的配置,它的性能和最先进的配置一样好,但速度快3倍;一个以速度为中心的配置,比最先进的配置快一个数量级。
第四段(为证明本文方法优越性,进行的测试以及比较)
We extensively evaluate the versatility of our proposed system on a large number of well-known datasets [68, 43, 77, 76, 79] that capture all challenges present in VPR.
我们在大量已知的数据集上广泛评估了我们提出的系统的通用性[68,43,77,76,79],这些数据集捕获了VPR中存在的所有挑战。
We compare Patch-NetVLAD with several state-of-the-art global feature descriptor methods [3, 56, 76], and additionally introduce new SuperPoint [18] and SuperGlue [59]-enabled VPR pipelines as competitive local descriptor baselines.
我们将Patch-NetVLAD与几种最先进的全局特征描述符方法[3,56,76]进行了比较,并引入了新的SuperPoint[18]和SuperGlue[59]支持的VPR管道作为具有竞争力的局部描述符基线。
PatchNetVLAD outperforms the global feature descriptor methods by large margins (from 6% to 330% relative increase) across
all datasets, and achieves superior performance (up to a relative increase of 54%) when compared to SuperGlue.
PatchNetVLAD在所有数据集上的表现都比全局特征描述符方法好得多(从6%到330%的相对提高),与SuperGlue相比,它的性能更好(相对提高54%)。
PatchNetVLAD won the Facebook Mapillary Long-term Localization Challenge as part of the ECCV 2020 Workshop on Long-Term Visual Localization.
作为ECCV 2020长期视觉定位研讨会的一部分,PatchNetVLAD赢得了Facebook Mapillary长期定位挑战。
To characterise the system’s properties in detail, we conduct numerous ablation studies showcasing the role of the individual components comprising Patch-NetVLAD, particularly the robustness of the system to changes in various key parameters. To foster future research, we make our code available for research purposes: https://github.com/QVPR/Patch-NetVLAD.
为了详细描述系统的特性,我们进行了大量的烧蚀研究,展示了组成Patch-NetVLAD的各个组件的作用,特别是系统对各种关键参数变化的鲁棒性。为了促进未来的研究,我们将我们的代码提供给研究目的:https://github.com/QVPR/Patch-NetVLAD。
2. Related Work 相关工作
第一段(介绍早期与深度学习的全局图像描述符)
Global Image Descriptors: Notable early global image descriptor approaches include aggregation of local keypoint descriptors either through a Bag of Words (BoW) scheme [64, 16], Fisher Vectors (FV) [34, 53] or Vector of Locally Aggregated Descriptors (VLAD) [35, 2].
全局图像描述符:早期值得注意的全局图像描述符方法包括通过词袋(BoW)方案[64,16]、费雪向量(FV)[34,53]或局部聚合描述符向量(VLAD)[35,2]聚合局部关键点描述符。
Aggregation can be based on either sparse keypoint locations [64, 35] or dense sampling of an image grid [76].
聚合既可以基于稀疏的关键点位置[64,35],也可以基于图像网格的密集采样[76]。
Re-formulating these methods through deep learning-based architectures led to NetVLAD [3], NetBoW [45, 51] and NetFV [45].
通过基于深度学习的架构重新制定这些方法,产生了NetVLAD[3]、NetBoW[45,51]和NetFV[45]。
More recent approaches include ranking-loss based learning [56], novel pooling [55], contextual feature reweighting [37], large scale re-training [79], semantics-guided feature aggregation [25, 61, 72], use of 3D [50, 78, 40], additional sensors [29, 52, 22] and image appearance translation [1, 54].
最近的方法包括基于排名损失的学习[56]、新型池化[55]、上下文特征重加权[37]、大规模再训练[79]、语义引导的特征聚合[25,61,72]、3D技术的使用[50,78,40]、附加传感器[29,52,22]和图像外观翻译[1,54]。
Place matches obtained through global descriptor matching are often re-ranked using sequential information [24, 82, 46], query expansion [28, 13], geometric verifi-cation [38, 25, 49] and feature fusion [80, 83].
通过全局描述符匹配获得的位置匹配通常使用顺序信息[24,82,46]、查询扩展[28,13]、几何验证[38,25,49]和特征融合[80,83]进行重新排序。
Distinct from existing approaches, this paper introduces Patch-NetVLAD, which reverses the local-to-global process of image description by deriving multi-scale patch features from a global descriptor, NetVLAD.
与现有方法不同的是,本文引入了patch -NetVLAD,它通过从全局描述符NetVLAD中提取多尺度patch特征来逆转图像描述的局部到全局过程。
第二段(介绍局部关键点描述符)
Local Keypoint Descriptors: Local keypoint methods are often used to re-rank initial place match candidate lists produced by a global approach [23, 71, 58].
局部关键点描述符:局部关键点方法通常用于对全局方法生成的初始位置匹配候选列表进行重新排序[23,71,58]。
Traditional handcrafted local feature methods such as SIFT [41], SURF [6] and ORB [57], and more recent deep-learned local features like LIFT [81], DeLF [49], SuperPoint [18] and D2Net [20], have been extensively employed for VPR [49, 9, 17], visual
SLAM [47] and 6-DoF localization [60, 74, 20, 58].
传统的手工制作局部特征方法,如SIFT[41]、SURF[6]和ORB[57],以及最近的深度学习局部特征,如LIFT[81]、DeLF[49]、SuperPoint[18]和D2Net[20],已被广泛用于VPR[49,9,17]、视觉SLAM[47]和6- dof定位[60,74,20,58]。
The two most common approaches of using local features for place recognition are: 1) local aggregation to obtain global image
descriptors [49] and 2) cross-matching of local descriptors between image pairs [71].
使用局部特征进行位置识别的两种最常见的方法是:1)局部聚合获得全局图像描述符[49]和2)图像对之间的局部描述符交叉匹配[71]。
第三段(局部描述符可以进一步改进)
Several learning-based techniques have been proposed for spatially-precise keypoint matching.
已经提出了几种基于学习的空间精确关键点匹配技术。
These include a unified framework for detection, description and orientation estimation [81]; a ‘describe-then-detect’ strategy [20]; multi-layer explicit supervision [21]; scale-aware negative mining [65]; and contextual similarity-based unsupervised training [66].
其中包括用于检测、描述和方向估计的统一框架[81];“描述-然后检测”策略[20];多层显性监管[21];规模感知负挖掘[65];以及基于上下文相似性的无监督训练[66]。
However, the majority of these learning-based methods are optimized for 3D pose estimation, through robust description at a keypoint level to improve nearest neighbor matching performance against other keypoint-level descriptors.
然而,大多数基于学习的方法都针对3D姿态估计进行了优化,通过关键点级别的鲁棒描述来提高与其他关键点级别描述符的最近邻匹配性能。
Local descriptors can be further improved by utilizing the larger spatial context, especially beyond the CNN’s inherent hierarchical feature pyramid, a key motivation for our approach.
局部描述符可以通过利用更大的空间上下文进一步改进,特别是超越CNN固有的分层特征金字塔,这是我们方法的关键动机。
第四段(列举不在VPR背景下的局部区域描述符)
Local Region/Patch Descriptors: [69] proposed ConvNet Landmarks for representing and cross-matching large image regions, explicitly derived from Edge Boxes [88].
局部区域/斑块描述符:[69]提出了用于表示和交叉匹配大型图像区域的 ConvNet 地标,这些地标明确来自 Edge Boxes [88]。
[12] discovered landmarks implicitly from CNN activations using mean activation energy of regions defined as ‘8-connected’feature locations.
[12]利用定义为 "8-connected "特征位置的区域的平均激活能量,从 CNN 激活中隐含发现地标。
[8] composed region features from CNN activation tensors by concatenating individual spatial elements along the channel dimension.
[8]从 CNN激活张量的区域特征。
However, these offthe-shelf CNNs or handcrafted region description [84] approaches are not optimized for place recognition, unlike the use of the VPR-trained network in this work.
然而,这些现成的 CNN 或手工制作的区域描述 [84] 方法并没有针对地点识别进行优化,这与使用 VPR 训练的网络不同。
本研究中使用的 VPR 训练网络不同。
第五段(列举在VPR背景下的局部区域描述符)
Learning region descriptors has been studied for specific tasks [62, 44] as well as independently on image patches [67].学习区域描述符已经被研究用于特定任务[62,44]以及独立于图像补丁[67]。
In the context of VPR, [26] designed a regions-based selfsupervised learning mechanism to improve global descriptors using image-to-region matching during training.
在VPR的背景下,[26]设计了一种基于区域的自监督学习机制,在训练过程中使用图像到区域的匹配来改进全局描述符。
[86]modeled relations between regions by concatenating local descriptors to learn an improved global image descriptor based on K-Max pooling rather than sum [4] or max pooling (R-MAC) [75].
[86]通过连接局部描述符来建模区域之间的关系,以学习基于K-Max池而不是sum[4]或max池(R-MAC)的改进的全局图像描述符[75]。
[11] proposed a ‘context-flexible’ attention mechanism for variable-size regions.
[11]提出了可变大小区域的“上下文灵活”注意机制。
However, the learned attention masks were only employed for viewpoint-assumed place recognition and could potentially be used for region selection in our proposed VPR pipeline.
然而,学习到的注意掩模仅用于视点假设的位置识别,并且可能用于我们提出的VPR管道中的区域选择。
[73] proposed RVLAD for describing regions extracted through a trained landmark detector, and combined it with selective match kernels to improve global descriptor matching, thus doing away with cross-region comparisons.
[73]提出了RVLAD来描述通过训练好的地标检测器提取的区域,并将其与选择性匹配核相结合来改进全局描述符匹配,从而消除了跨区域比较。
[36] proposed RegionVLADwhere region features were defined using average activations of connected components within different layers of CNN feature maps.
[36]提出了RegionVLAD,其中使用CNN特征图不同层内连接分量的平均激活来定义区域特征。
These region features were then separately aggregated as a VLAD representation.
然后将这些区域特征单独聚合为VLAD表示。
Unlike [36, 73], we remove this separate step by generating region-level VLAD descriptors through NetVLAD, thus reusing the VPR-relevant learned cluster membership of spatial elements.
与[36,73]不同,我们通过NetVLAD生成区域级VLAD描述符,从而重用与vpr相关的空间元素学习到的聚类隶属度,从而消除了这一单独的步骤。
第六段(现有的多尺度方法存在缺陷,本文方法更好)
Existing techniques for multi-scale approaches typically fuse information at the descriptor level, which can lead to loss of complementary or discriminative cues [80, 83, 10, 48, 27, 87] due to pooling, or increased descriptor sizes due to concatenation [39, 86, 7, 8].
现有的多尺度方法通常在描述符级别融合信息,这可能导致由于池化而丢失互补或判别线索[80,83,10,48,27,87],或者由于串联而增加描述符大小[39,86,7,8]。
Distinct from these methods, we consider multi-scale fusion at the final scoring stage, which enables parallel processing with associated speed benefits.
与这些方法不同,我们在最后评分阶段考虑多尺度融合,这使得并行处理具有相关的速度优势。
3. Methodology 方法
第一段(介绍本文方法)
Patch-NetVLAD ultimately produces a similarity score between a pair of images, measuring the spatial and appearance consistency between these images.
Patch-NetVLAD最终产生一对图像之间的相似性评分,测量这些图像之间的空间和外观一致性。
Our hierarchical approach first uses the original NetVLAD descriptors to retrieve the top-k (we use k = 100 in our experiments) most likely matches given a query image.
我们的分层方法首先使用原始NetVLAD描述符来检索给定查询图像的最可能匹配的top-k(我们在实验中使用k = 100)。
We then compute a new type of patch descriptor using an alternative to the VLAD layer used in NetVLAD [3], and perform local matching of patch-level descriptors to reorder the initial match list and refine the final image retrievals.
然后,我们使用NetVLAD[3]中使用的VLAD层的替代方案来计算一种新型的补丁描述符,并对补丁级描述符进行局部匹配,以重新排序初始匹配列表并改进最终的图像检索。
This combined approach minimizes the additional overall computation cost incurred by cross matching patch features without sacrificing recall performance at the final image retrieval stage. An overview of the complete pipeline can be found in Fig. 2.
这种组合方法在不牺牲最终图像检索阶段的召回性能的情况下,最大限度地减少了交叉匹配patch特征所带来的额外总体计算成本。完整管道的概览如图2所示。
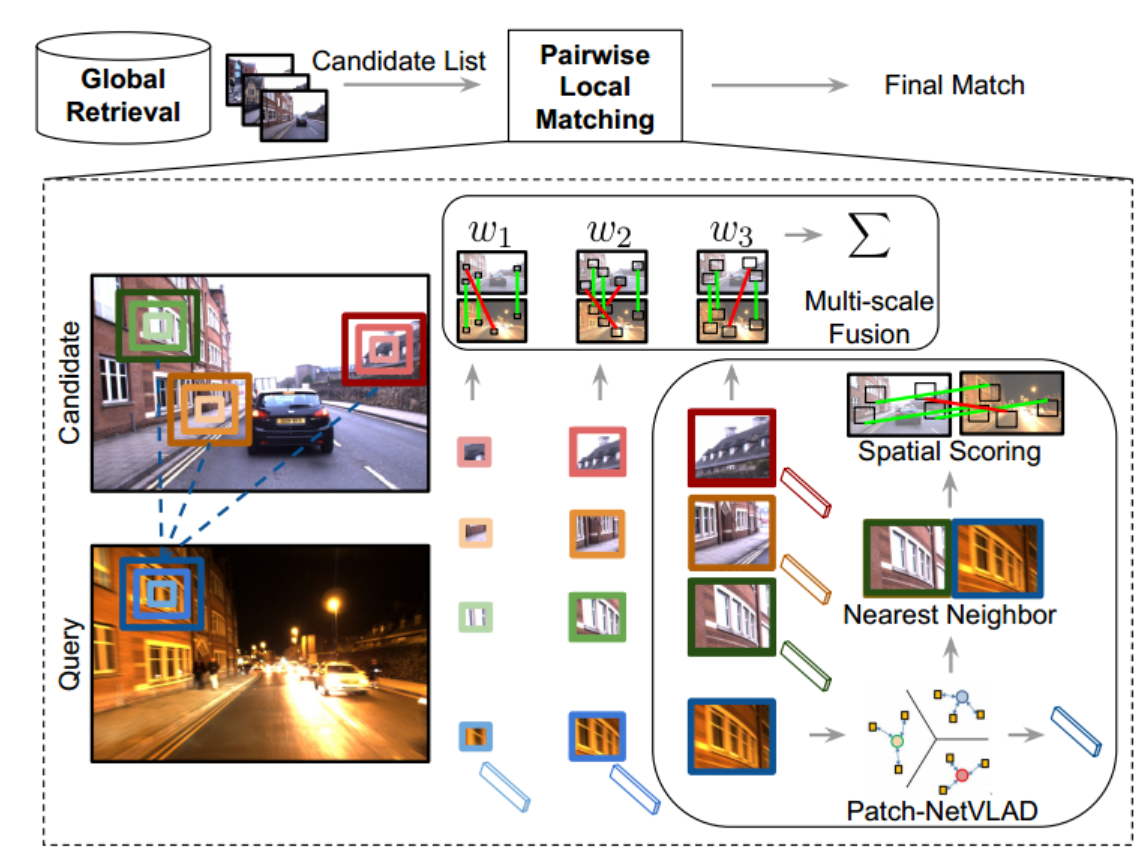
Figure 2. Proposed Algorithm Schematic.
图2。提出算法原理图。
Patch-NetVLAD takes as input an initial list of most likely reference matches to a query image, ranked using NetVLAD descriptor comparisons.
Patch-NetVLAD将查询图像的最可能引用匹配的初始列表作为输入,使用NetVLAD描述符比较进行排序。
For topranked candidate images, we compute new locally-global patchlevel descriptors at multiple scales, perform local cross-matching of these descriptors across query and candidate images with geometric verification, and use these match scores to re-order the initial list, producing the final image retrievals.
对于排名靠前的候选图像,我们在多个尺度上计算新的局部全局补丁级描述符,在具有几何验证的查询和候选图像之间对这些描述符进行局部交叉匹配,并使用这些匹配分数对初始列表重新排序,产生最终的图像检索。
3.1. Original NetVLAD Architecture 原始NetVLAD架构
第一段(介绍原始NetVLAD架构)
The original NetVLAD [3] network architecture uses the Vector-of-Locally-Aggregated-Descriptors (VLAD) approach to generate a condition and viewpoint invariant embedding of an image by aggregating the intermediate feature maps extracted from a pre-trained Convolutional Neural Network (CNN) used for image classification [63].
原始的NetVLAD[3]网络架构使用vector -of- local - aggregated - descriptors (VLAD)方法,通过聚合从用于图像分类的预训练卷积神经网络(CNN)中提取的中间特征映射,生成图像的条件和视点不变嵌入[63]。
Specifically, let fθ : I → R H×W×D be the base architecture which given an image I, outputs a H × W × D dimensional feature map F (e.g. the conv5 layer for VGG).
具体来说,设fθ: I→R H×W×D为给定图像I的基础架构,输出H×W×D维特征映射F(例如VGG的conv5层)。
The original NetVLAD architecture aggregates these D-dimensional features into a K × D-dimensional matrix by summing the residuals between each feature xi ∈ R D and K learned cluster centers weighted by soft-assignment.
原始的NetVLAD架构通过将每个特征xi∈R D与K个学习到的聚类中心(通过软分配加权)之间的残差相加,将这些D维特征聚合成一个K × D维矩阵。
Formally, for N × D-dimensional features, let the VLAD aggregation layer fVLAD : R N×D → R K×D be given by fVLAD(F)(j, k) =
N X i=1 ¯ak(xi)(xi(j) − ck(j)) (1) where xi(j) is the j th element of the i th descriptor, a¯k is the soft-assignment function and ck denotes the k th cluster center.
形式上,对于N× d维特征,设VLAD聚集层fVLAD: R N×D→R K×D为:fVLAD(F)(j, k) = N X i=1¯ak(xi)(xi(j)−ck(j))(1),其中xi(j)为第i个描述符的第j个元素,a¯k为软分配函数,ck为第k个聚类中心。
After VLAD aggregation, the resultant matrix is then projected down into a dimensionality reduced vector using a projection layer fproj : R K×D → R Dproj by first applying intra(column)-wise normalization, unrolling into a single vector, L2-normalizing in its entirety and finally applying PCA (learned on a training set) with whitening and L2-normalization. Refer to [3] for more details.
在VLAD聚合之后,生成的矩阵使用投影层fproj: R K×D→R Dproj,通过首先应用intra(column)-wise归一化,展开为单个向量,整个进行l2归一化,最后应用PCA(在训练集上学习)与白化和l2归一化,然后向下投影为降维向量。详见[3]。
第二段(本文与原始架构的不同点)
We use this feature-map aggregation method to extract descriptors for local patches within the whole feature map
(N H ×W) and perform cross-matching of these patches at multiple scales between a query/reference image pair to
generate the final similarity score used for image retrieval.
我们使用这种特征图聚合方法提取整个特征图(N H ×W)中局部补丁的描述符,并在查询/参考图像对之间的多个尺度上对这些补丁进行交叉匹配,以生成用于图像检索的最终相似度得分。
This is in contrast to the original NetVLAD paper, which sets N = H × W and aggregates all of the descriptors within the feature map to generate a global image descriptor.
这与原始的NetVLAD论文形成对比,该论文设置N = H × W,并将特征映射中的所有描述符聚集在一起以生成全局图像描述符。
3.2. Patch-level Global Features 补丁级全局特性
第一段(本系统核心是补丁形式的全局描述符)
A core component of our system revolves around extracting global descriptors for densely sampled sub-regions (in the form of patches) within the full feature map.
我们系统的一个核心组件围绕着在完整的特征图中提取密集采样子区域(以补丁的形式)的全局描述符。
We extract a set of dx × dy patches {Pi , xi , yi} np i=1 with stride sp from the feature map F ∈ R H×W×D, where the total number of patches is given by np = H − dy sp + 1 ∗ W − dx sp + 1 , dy, dx ≤ H, W (2) and Pi ∈ R (dx×dy)×D and xi , yi are the set of patch features and the coordinate of the center of the patch within the feature map, respectively.
我们提取一组dx×dy补丁{π,xi,易}np与步幅sp i = 1的特征映射F∈R W H××D,补丁是np的总数=−dy sp H + 1 ∗ W sp + 1 −dx, dy, dx≤H, W(2)和πR∈(dx×dy)×D和xi,易建联是补丁的设置功能和协调中心的地图补丁的特性,分别。
While our experiments suggest that square patches yielded the best generalized performance across a wide range of environments, future work could consider different patch shapes, especially in specific circumstances (e.g. environments with different texture frequencies in the vertical and horizontal directions)
虽然我们的实验表明方形斑块在广泛的环境中产生了最好的通用性能,但未来的工作可以考虑不同的斑块形状,特别是在特定的情况下(例如,在垂直和水平方向上具有不同纹理频率的环境)。
第二段(本方法如何做的)
For each patch, we subsequently extract a descriptor yielding the patch descriptor set {fi} np i=1 where fi = fproj (fVLAD (Pi)) ∈ R Dproj uses the NetVLAD aggregation and projection layer on the relevant set of patch features.
对于每个patch,我们随后提取一个描述符,得到patch描述符集{fi} np i=1,其中fi = fproj (fVLAD (Pi))∈R。
In all experiments we show how varying the degree of dimensionality reduction on the patch features using PCA can be used to achieve a user-preferred balance of computation time and image retrieval performance (see Section 4.5).
Dproj在相关patch特征集上使用NetVLAD聚合和投影层。在所有实验中,我们展示了如何使用PCA对patch特征进行不同程度的降维,以实现计算时间和图像检索性能的用户首选平衡(参见第4.5节)。
We can further improve place recognition performance by extracting patches at multiple scales and observe that using a combination of patch sizes which represent larger sub-regions within the original image improves retrieval (see Section 3.5).
我们可以通过在多个尺度上提取斑块来进一步提高位置识别性能,并观察到在原始图像中使用代表更大子区域的斑块大小的组合可以提高检索效果(参见第3.5节)。
This multi-scale fusion is made computationally efficient using
our IntegralVLAD formulation introduced in Section 3.6.
使用我们在第3.6节中介绍的IntegralVLAD公式,这种多尺度融合在计算上是高效的。
第三段(本文补丁特征的优点)
Compared to local feature-based matching where features are extracted for comparatively small regions within the image, our patch features implicitly contain semantic information about the scene (e.g., building, window, tree) by covering a larger area.
与局部特征匹配相比,局部特征是在图像中相对较小的区域提取特征,我们的补丁特征通过覆盖更大的区域隐含地包含关于场景的语义信息(例如,建筑物,窗户,树木)。
We now introduce the remaining parts of our pipeline, which is comprised of mutual nearest neighbor matching of patch descriptors followed by spatial scoring.
现在我们介绍管道的其余部分,它由补丁描述符的相互最近邻匹配和空间评分组成。
3.3. Mutual Nearest Neighbours 相互近邻
Given a set of reference and query features {fri} npi=1 and {fqi} np i=1, (we assume both images have the same resolution for simplicity), we obtain descriptor pairs from mutual nearest neighbor matches through exhaustive comparison between the two descriptor sets.
给定一组参考特征和查询特征 {fri} npi=1 和 {fqi} np i=1(为简单起见,我们假设两幅图像具有相同的分辨率),我们通过对两组描述符进行穷举比较,从相互最近邻匹配中获得描述符对。
Formally, let the set of mutual nearest neighbor matches be given by P, where P = (i, j): i = NNr(f q j ), j = NNq(f r
i )(3)and NNq(f) = argminj kf − fq j k2 and NNr(f) = argminj kf − f r j k2 retrieve the nearest neighbor descriptor match with respect to Euclidean distance within the query and reference image set, respectively.
形式上,互为近邻匹配的集合由 P 给出,其中 P = (i, j):i = NNr(f q j ), j = NNq(f ri )(3)NNq(f) = argminj kf - fq j k2 和 NNr(f) = argminj kf - f r j k2 分别检索查询图像集和参考图像集内欧氏距离最近的相邻描述符匹配。
Given a set of matching patches, we can now compute the spatial matching score used for image retrieval.
有了一组匹配斑块,我们就可以计算出用于图像检索的空间匹配得分。
3.4. Spatial Scoring 空间得分
第一段(本文的空间评分方法有两种)
We now introduce our spatial scoring methods which yield an image similarity score between a query/reference image pair used for image retrieval.
我们现在介绍我们的空间评分方法,它产生用于图像检索的查询/参考图像对之间的图像相似性评分。
We present two alternatives, a RANSAC-based scoring method which requires more computation time for higher retrieval performance and a spatial scoring method which is substantially faster to compute at the slight expense of image retrieval performance.
我们提出了两种替代方案,一种是基于ransac的评分方法,它需要更多的计算时间来获得更高的检索性能;另一种是空间评分方法,它的计算速度快得多,但对图像检索性能的影响很小。
第二段(RANSAC评分)
RANSAC Scoring: Our spatial consistency score is given by the number of inliers returned when fitting a homography between the two images, using corresponding patches computed using our mutual nearest neighbor matching step for patch features.
RANSAC评分:我们的空间一致性评分是由拟合两幅图像之间的单应性时返回的内层数给出的,使用使用我们的补丁特征的相互最近邻匹配步骤计算的相应补丁。
We assume each patch corresponds to a 2D image point with coordinates in the center of the patch when fitting the homography.
在拟合单应性时,我们假设每个patch对应一个坐标在patch中心的2D图像点。
We set the error tolerance for the definition of an inlier to be the stride sp.
我们将内层定义的误差容忍度设置为步长sp。
We also normalize our consistency score by the number of patches, which is relevant when combining the spatial score at multiple scales as discussed in Section 3.5.
我们还通过补丁的数量对一致性评分进行了归一化,这与3.5节中讨论的在多个尺度上组合空间评分相关。
第三段(快速空间评分)
Rapid Spatial Scoring: We also propose an alternative to the RANSAC scoring approach which we call rapid spatial scoring.
快速空间评分:我们还提出了RANSAC评分方法的另一种选择,我们称之为快速空间评分。
This rapid spatial scoring significantly reduces computation time as we can compute this score directly on the matched feature pairs without requiring sampling.
这种快速的空间评分显著减少了计算时间,因为我们可以直接在匹配的特征对上计算这个分数,而不需要采样。
第四段(快速空间评分如何计算)
To compute the rapid spatial score, let xd = {x r i − x q j }(i,j)∈P be the set of displacements in the horizontal direction between patch locations for the matched patches, and yd be the displacements in the vertical direction.
为计算快速空间得分,设 xd = {x r i - x q j }(i,j)∈P 为匹配斑块位置间水平方向的位移集,yd 为垂直方向的位移集。
In addition, let x¯d = 1 |xd| P xd,i∈xd xd,i and similarly y¯d be the mean displacements between matched patch locations.
此外,设 x¯d = 1 |xd| P xd,i∈xd xd,i,类似地,y¯d 是匹配斑块位置之间的平均位移。
We can then define our spatial score (higher is better) to be sspatial = 1 np X i∈P | max j∈P xd,j | − |xd,i − x¯d|) 2 + | max j∈P yd,j | − |yd,i − y¯d| 2 , (4) where the score comprises the sum of residual displacements from the mean, with respect to the maximum possible spatial offset.
我们可以将空间得分(越高越好)定义为 sspatial = 1 np X i∈P | max j∈P xd,j | - |xd,i - x¯d|) 2 + | max j∈P yd,j | - |yd,i - y¯d| 2 ,(4) 其中,分值包括相对于最大可能空间偏移的平均值的残余位移之和。
The spatial score penalizes large spatial offsets in matched patch locations from the mean offset, in effect measuring the coherency in the overall movement of elements in a scene under viewpoint change.
空间分值惩罚的是匹配补丁位置与平均偏移量之间的较大空间偏移,实际上是测量视点变化下场景中元素整体移动的一致性。
3.5. Multiple Patch Sizes 多个补丁大小
第一段(评分公式扩展到补丁)
We can easily extend our scoring formulation to ensemble patches at multiple scales and further improve performance.
我们可以很容易地将我们的评分公式扩展到多个尺度的集成补丁,并进一步提高性能。
For ns different patch sizes, we can take a convex combination of the spatial matching scores for each patch size as our final matching score.
对于ns个不同的patch大小,我们可以取每个patch大小的空间匹配分数的一个凸组合作为我们的最终匹配分数。
Specifically, sspatial = ns X i=1 wisi,spatial, (5) where si,spatial is the spatial score for the i th patch size and P i wi = 1, wi ≥ 0 for all i.
其中,sspatial = ns X i=1 wisi,spatial,(5)其中,si,spatial为第i个斑块大小的空间得分,pi wi =1, wi≥0对于所有i。
3.6. IntegralVLAD
第一段(介绍本文新提出的IntegralVLAD公式)
To assist the computation of extracting patch descriptors at multiple scales, we propose a novel IntegralVLAD formulation analogous to integral images [15].
为了帮助在多尺度上提取补丁描述符的计算,我们提出了一种类似于积分图像的新型IntegralVLAD公式[15]。
To see this, note that the aggregated VLAD descriptor (before the projection layer) for a patch can be computed as the sum of all 1×1 patch descriptors each corresponding to a single feature within the patch.
要看到这一点,请注意,一个补丁的聚合VLAD描述符(在投影层之前)可以计算为所有1×1补丁描述符的总和,每个补丁描述符对应于补丁中的单个特征。
This allows us to pre-compute an integral patch feature map which can then be used to compute patch descriptors for multi-scale fusion. Let the integral feature map I be given by
这允许我们预先计算一个积分的补丁特征映射,然后可以用来计算多尺度融合的补丁描述符。设积分特征映射I由
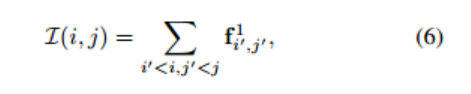
where f 1 i 0 ,j0 represents the VLAD aggregated patch descriptor (before projection) for a patch size of 1 at spatial index i 0 , j0 in the feature space.
其中f 1 i 0,j0表示特征空间索引i 0,j0处patch大小为1的VLAD聚合patch描述符(投影前)。
We can now recover the patch features for arbitrary scales using the usual approach involving arithmetic over four references within the integral feature map.
我们现在可以使用通常的方法恢复任意尺度的补丁特征,包括在积分特征映射中的四个引用上进行算术。
This is implemented in practice through 2D depth-wise dilated convolutions with kernel K, where
这在实践中是通过核K的二维深度扩展卷积实现的,其中
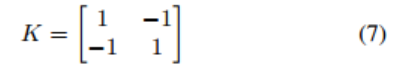
and the dilation is equal to the required patch size.
膨胀等于所需的贴片大小。
4. Experimental Results 实验结果
4.1. Implementation 实现
第一段(介绍实现本方法所作的调整)
We implemented Patch-NetVLAD in PyTorch and resize all images to 640 by 480 pixels before extracting our patch features.
我们在 PyTorch 中实现了 Patch-NetVLAD,并在提取补丁特征前将所有图像调整为 640 x 480 像素。
We train the underlying vanilla NetVLAD feature extractor [3] on two datasets: Pittsburgh 30k [77] for urban imagery (Pittsburgh and Tokyo datasets), and Mapillary Street Level Sequences [79] for all other conditions.
我们在两个数据集上训练底层的 vanilla NetVLAD 特征提取器 [3]:匹兹堡 30k [77] 用于城市图像(匹兹堡和东京数据集),Mapillary 街道水平序列 [79] 用于所有其他条件。
All hyperparameters for training are the same as in [3], except for the Mapillary trained model for which we reduced the number of clusters from 64 to 16 for faster training due to the large dataset size
训练时的所有超参数都与 [3] 中的相同,除了 Mapillary 训练的模型,由于数据集规模较大,为了加快训练速度,我们将集群数从 64 个减少到 16 个。
第二段(补丁大小与相关权重设置)
To find the patch sizes and associated weights, we perform a grid search to find the model configuration that performs best on the RobotCar Seasons v2 training set.
为了找到补丁大小和相关权重,我们执行网格搜索以找到在RobotCar Seasons v2训练集上表现最好的模型配置。
This resulted in patch size dx = dy = 5 (which equates to an 228 by 228 pixel area in the original image) with stride sp = 1 when a single patch size is used, and square patch sizes 2, 5 and 8 with associated weights wi = 0.45, 0.15, 0.4 for the multi-scale fusion.
这导致当使用单个补丁大小时,补丁大小dx = dy = 5(相当于原始图像中228 × 228像素的区域)步幅sp = 1,而对于多尺度融合,方形补丁大小为2,5和8,相关权重wi = 0.45, 0.15, 0.4。
We emphasize that this single configuration is used for all experiments across all datasets.
我们强调,这种单一配置用于所有数据集的所有实验。
While the results will indicate that the proposed system configuration would on average outperform all other methods in a wide range of deployment domains, it is likely that if a highly specialized system was required, further performance increases could be achieved by fine-tuning patch sizes and associated weights for the specific environment.
虽然结果将表明,在广泛的部署域中,建议的系统配置平均优于所有其他方法,但如果需要高度专业化的系统,则很可能通过微调补丁大小和特定环境的相关权重来实现进一步的性能提高。
4.2. Datasets 数据集
第一段(本文使用六个基准数据集)
To evaluate Patch-NetVLAD, we used six of the key benchmark datasets: Nordland [68], Pittsburgh [77], Tokyo24/7 [76], Mapillary Streets [79], RobotCar Seasons v2 [43, 74] and Extended CMU Seasons [5, 74].
为了评估Patch-NetVLAD,我们使用了六个关键基准数据集:Nordland[68]、Pittsburgh[77]、Tokyo24/7[76]、Mapillary Streets[79]、RobotCar Seasons v2[43,74]和Extended CMU Seasons[5,74]。
Full technical details of their usage are provided in the Supplementary Material; here we provide an overview to facilitate an informed appraisal of the results.
其使用的全部技术细节已在补充材料中提供;在这里,我们提供一个概述,以促进对结果的知情评估。
Datasets were used in their recommended configuration for benchmarking, including standardized curation (e.g. removal of pitch black tunnels and times when the train is stopped for the Nordland dataset [8, 70, 31, 30]) and use of public validation and withheld test sets where provided (e.g. Mapillary).
数据集在他们推荐的基准配置中使用,包括标准化管理(例如,对于Nordland数据集[8,70,31,30],删除沥青黑色隧道和火车停车时间),以及使用公共验证和保留测试集(例如Mapillary)。
第二段(简略介绍每个数据集)
Collectively the datasets encompass a challenging range of viewpoint and appearance change conditions, partly as a result of significant variations in the acquisition method, including train, car, smartphone and general crowdsourcing.
总的来说,这些数据集包含了一系列具有挑战性的视角和外观变化条件,部分原因是获取方法的重大变化,包括火车、汽车、智能手机和一般的众包。
Specific appearance changes are caused by different times of day: dawn, dusk, night; by varying weather: sun, overcast, rain, and snow; and by seasonal change: from summer to winter. Nordland, RobotCar, Extended CMU Seasons and Tokyo 24/7 contain varying degrees of appearance change up to very severe day-night and seasonal changes.
具体的外观变化是由一天中的不同时间引起的:黎明、黄昏、夜晚;通过变化的天气:晴天,阴天,下雨和下雪;还有季节变化:从夏天到冬天。Nordland, RobotCar, Extended CMU Seasons和Tokyo 24/7包含不同程度的外观变化,包括非常严重的昼夜和季节变化。
The Pittsburgh dataset contains both appearance and viewpoint change, while the MSLS dataset [79] in particular includes simultaneous variations in all of the following: geographical diversity (30 major cities across the globe), season, time of day, date (over 7 years), viewpoint, and weather.
匹兹堡数据集包含外观和视点变化,而MSLS数据集[79]尤其包括以下所有方面的同时变化:地理多样性(全球30个主要城市)、季节、时间、日期(超过7年)、视点和天气。
In total, we evaluate our systems on ≈300,000 images.
总的来说,我们在约300,000张图像上评估我们的系统。
4.3. Evaluation 评价
第一段(数据集采用的指标)
All datasets except for RobotCar Seasons v2 and Extended CMU Seasons are evaluated using the Recall@N metric, whereby a query image is correctly localized if at least one of the top N images is within the ground truth tolerance [3, 76].
除 RobotCar Seasons v2 和 Extended CMU Seasons 外,所有数据集均采用 Recall@N 指标进行评估,即如果前 N 张图像中至少有一张在地面实况容差范围内,则查询图像被正确定位[3, 76]。
The recall is then the percentage of correctly localized query images, and plots are created by varying N.
因此,召回率就是正确定位查询图像的百分比,并通过改变 N 来绘制曲线图。
第二段(在各个数据集上的误差)
We deem a query to be correctly localized within the standard ground-truth tolerances for all datasets, i.e. 10 frames for Nordland [30, 31], 25m translational error for Pittsburgh and Tokyo 24/7 [3], and 25m translational and 40◦ orientation error for Mapillary [79].
我们认为查询在所有数据集的标准地面真值公差范围内是正确定位的,即Nordland的10帧[30,31],匹兹堡和东京的24/7平移误差为25米[3],Mapillary的平移和40◦方向误差为25米[79]。
第三段(在各个数据集上的误差)
For RobotCar Seasons v2 and Extended CMU Seasons, we use the default error tolerances [74], namely translational errors of .25, .5 and 5.0 meters and corresponding rotational errors of 2, 5 and 10 degrees.
对于RobotCar Seasons v2和Extended CMU Seasons,我们使用默认的误差容限[74],即平移误差为0.25、0.5和5.0米,相应的旋转误差为2度、5度和10度。
Note that our method is a place recognition system and does not perform explicit 6-DOF pose estimation; the pose estimate for a query image is given by inheriting the pose of the best matched reference image.
请注意,我们的方法是一个位置识别系统,不执行明确的6-DOF姿态估计;通过继承最匹配的参考图像的姿态给出查询图像的姿态估计。


















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









