







Coding Skill目录下的所有Tutorials、Notes博客都会不定期迭代更新
目录
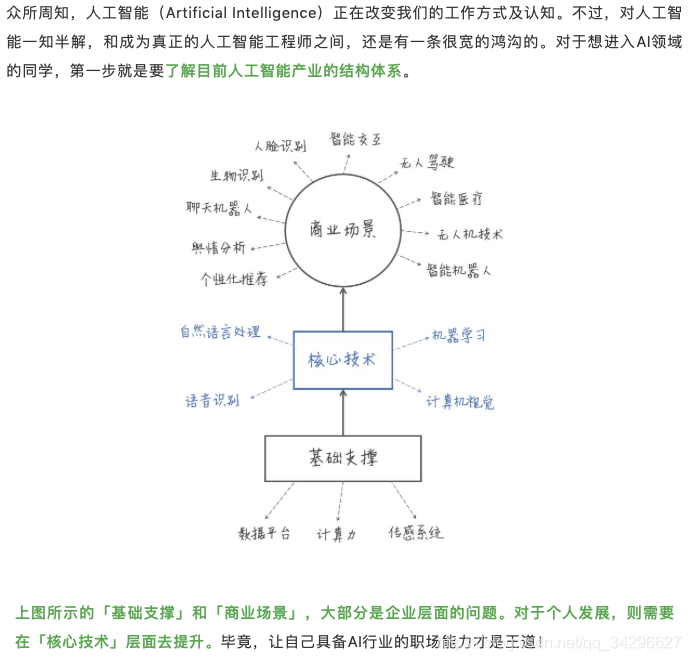
零 数字图像处理 - 传统解决方案
0 图像处理
图像基础、运算
RGB通道概念 - 推荐
windows的bmp有时候是一个四通道图像,R、G、B加上一个A通道,表示透明度
从 RGB 到 HSV 的转换详细介绍
图像增强
图像编码
图像还原
图像分割
图像识别
图像特征表示、提取
不同的特征提取方法,对应于不同的应用实例,例如人脸识别用haar特征,SIFT特征应用在
图像重建
1 机器学习
多应用于数据分析
线性模型
决策树
贝叶斯
k近邻
数据降维
聚类、EM算法
支持向量机
人工神经网络
半监督学习
集成学习
(分类、回归、聚类)
一 深度学习知识结构
deep-learning-with-python-notebooks
神经病研究神经网络博客
0 神经网络
神经网络的函数逼近理论:在数学中,我们可以将函数看作是一个“机器”或“黑匣子”。
神经网络阐述性解释和GAN是一种特殊的损失函数: 趣味易懂地解释了损失函数在神经网络中的重要性和深入理解的必要性,以及表明不同的应用场景诞生不同的损失函数,而GAN是一种特殊的损失函数。
1 深度学习图像领域
图像领域七大任务:图像识别(分类)、目标检测、语义分割、实例分割、生成模型、图像检索、强化学习
深度学习网络架构的改进往往缺乏可解释性,在有了一个灵感之后,付诸实验。效果好,就可以发paper了。
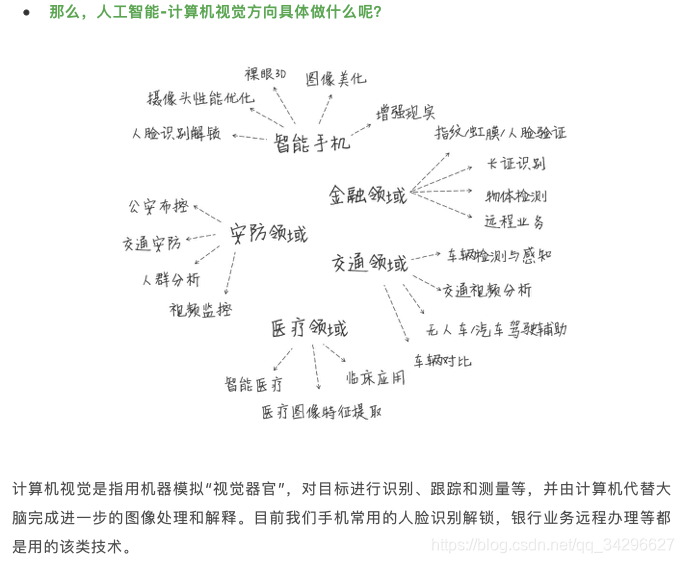
五大维度深入分析计算机视觉
不同图像领域,分别需要用到哪些知识,共性在哪里?
1.1 图像识别
从LeNet到SENet——卷积神经网络回顾
历史:
LeNet(1998)、AlexNet(2012)、VGG(2014)、Inception 流派、ResNet 流派、移动端、其他流派(NASNet、SENet、MSDNet)。
LeNet5、AlexNet、VGG、Inception v1 到 v4、Inception-ResNet、ResNet、DenseNet、ResNeXt、Xception、SENet、SqueezeNet、NASNet、MobileNet v1和v2、ShuffleNet等CNN的变种。
忘了一个事,这里所有优化的分类网络,主要修改网络架构,也有修改参数初始化方法,有修改激活函数、优化函数,那么他们的loss函数都是一样的吗?
| Algorithms | Innovation |
|---|---|
| LeNet(1998) | 第一篇CNN;三层卷积两层全连接;主要应用于全美邮件手写数字识别 |
| AlexNet(2012) | Top5 Error:16.4%;五层卷积和三层全连接;ReLU;LRN;Dropout;Softmax;数据增广、学习率策略、weight decay 等 |
| VGG(2014) | Top5 Error:7.3%;16层 和 19 层;只使用 3x3 的卷积核 |
| Inception v1(GoogLeNet 2015) | Top5 Error:6.7%;22层;Inception模块;1x1卷积核 |
| ResNet(2016) | Top5 Error:3.57%;最高152层;残差结构; |
| = Inception 流派 = | 核心就是 Inception 模块,出现了各种变种,包括 Inception v2 到 v4 以及 Inception-ResNet v1 和 v2 等 |
| Inception v2(BN-Inception 2015) | Top5 Error:4.8%;Batch Normalization |
| Inception v3(2015) | Top5 Error:3.5%;5x5 用两个 3x3 卷积替换,7x7 用三个 3x3 卷积替换,一个 3x3 卷积核可以进一步用 1x3 的卷积核和 3x1 的卷积核组合来替换 |
| Inception v4(2016) | Top5 Error:3.08%;Inception v1 到 v3,可以看到很明显的人工设计的痕迹,不同卷积核的和网络结构的安排,很特殊,并不知道为什么要这样安排,实验确定的。而现在有了 TensorFlow,网络可以按照理想的设计来实现了,于是很规范地设计了一个 Inception v4 网络,类似于 Inception v3,但是没有很多特殊的不一致的设计。 |
| Inception-ResNet v1 | Top5 Error:.%;Inception与ResNet的结合 |
| Inception-ResNet v2 | Top5 Error:.%; |
| = ResNet 流派 = | 另一个主流分支,包括 WRN、DenseNet、ResNeXt 以及 Xception 等 |
| DenseNet(2016) | Top5 Error:.%;DenseNet 将 residual connection 发挥到极致,每一层输出都直连到后面的所有层,可以更好地复用特征,每一层都比较浅,融合了来自前面所有层的所有特征,并且很容易训练。缺点是显存占用更大并且反向传播计算更复杂一点。 |
| ResNeXt(2017) | Top5 Error:3.03%;ResNet和Inception的结合,对于每一个 ResNet 的每一个基本单元,横向扩展,将输入分为几组,使用相同的变换,进行卷积。 |
| Xception(2016) | Top5 Error:.%; |
| = 移动端 = | |
| MobileNet v1(2017) | |
| MobileNet v2 (2018) | |
| ShuffleNet(2017) | |
| = 其他流派 = | |
| SENet(2017) | Top5 Error:2.25%;Squeeze-Excitation 模块 |
| NASNet | Top5 Error:.%; |
| MSDNet | Top5 Error:.%; |
改进的意义是什么:
提高Image Net的识别精度,除去可以做分类之外,这些网络架构常常被用作其他任务中图像特征的提取backbone。
现实场景中的应用
- 我们将这些CNN的主干网络作为其他任务的backbone,即特征提取器
- 常规任务并不会在乎百分之几的误差,也不需要那么多层的卷积网络层数。因此基本的VGG19、ResNet22就足够了,搭配好相应的硬件和数据就可以投入使用。
总结:基础的CNN知识,有用的tricks及一定调参经验,硬件消耗,内存占用,耗时,部署综合考量
在深度学习中,网络由特征层和分类层(或者回归层)组成,特征层负责特征的提取,特征层得到的结果可以看做两方面组成:
- 特征的种类,例如图像卷积得到的Feature Map的每个通道便对应一种特征;
- 特征对应输入数据的位置,还是图像,Feature Map的每个像素点会对应输入图像中固定的感受野,以及NLP的机器翻译等任务中每个时间片对应的是句子的一个单词。
分类算法的CNN架构只在最后一层全连接层进行分类任务,前面都是为了有效地提取图片特征。很多情况下,现实中的分类任务往往不是one imege,one label,于是需要对网络稍作修改:
Single-Label,Multi-Class:一个物体有一个label,这个label有大于2种的分类情况,通常用softmax作为最后一层的激活函数
Multi-Label:一个物体可能有多个label,只需要将最后一层Dense的activate function由softmax改为sigmoid即可。
Multi-Task:
1. Aliyun比赛各个服装细节的多任务NasNet网络
2. Yolo系列算法,既做检测,又做分类
3.
Multiple Input Neural Networks
Measurement
准确率、召回率等等效果评估指标
Experiments
- VGG
- ResNet
- Inception v1
Resources
《Computer vision》笔记-ResNet(4)
谷歌系列 :Inception v1到v4
CNN可视化
卷积神经网络可视化
Keras实现卷积神经网络(CNN)可视化
卷积神经网络可视化与可解释性
卷积神经网络特征图可视化(自定义网络和VGG网络)
卷积神经网络可视化和理解
VisualizationCNN
CNN-heatmap
How to visualize convolutional features in 40 lines of code
CNN visualization tool in TensorFlow
【2017CS231n】第十二讲:可视化和理解卷积神经网络
图像聚类
visualizing_convnets
Visualizing-and-Understanding-Convolutional-Networks
用DenseNet完整的去跑一遍,调试一遍分类任务/多任务,并要能说清DenseNet较之前的分类框架,优异在哪
1.2 目标检测
历史:
通用物体检测;衣服检测、关键点检测;人脸检测、关键点检测,行人检测;各式特定物体的检测、关键点检测;目标分割(Mask RCNN);实例分割;小目标检测
人脸检测(MTCNN也包括关键点检测)/分割、行人检测、衣物检测/分割都是目标检测里单独的一个分支。
目标检测分为两类:
- two-stage 检测算法:RCNN系列
- one-stage 检测算法:Yolo系列多任务算法,SSD系列算法
改进的意义是什么:TODO
| Algorithms | Innovation |
|---|---|
| = two-stage 检测算法 = | |
| R-CNN(Selective Search + CNN + SVM) | |
| SPP-net(ROI Pooling) | |
| Fast R-CNN(Selective Search + CNN + ROI) | |
| Faster R-CNN(RPN + CNN + ROI) | |
| R-FCN | |
| = one-stage 检测算法 = | |
| YOLO v1 | |
| YOLO v2 | |
| YOLO v3 | |
| SSD | |
| DenseBox | |
| RetinaNet | |
| = 语义分割算法 = | |
| Mask RCNN |
Measurement
目标检测模型评估指标mAP计算指南(附代码)
Tricks
目标检测训练trick超级大礼包—不改模型提升精度
GLUON目标检测、目标分割MODEL ZOO
mmdetection训练supervisely person 数据集博客
mmdetection Github - mmdetection=Mask RCNN
可以看到Cascade R-CNN、RetinaNet在box检测准确率上会高于faster rcnn,只是没有还改yolo系列。
1.3 语义分割
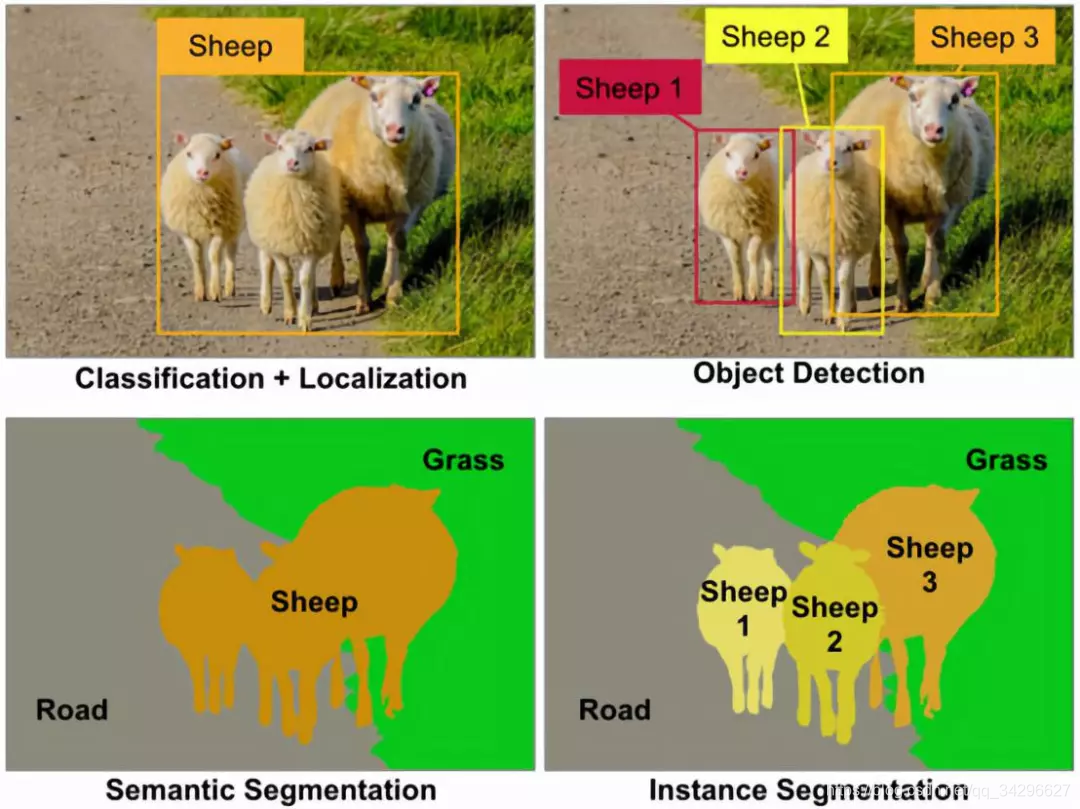
-
Review
检测与分割详解
从目标检测到图像分割简要发展史
基于深度学习的图像语义分割算法综述
图像分割技术介绍
图像分割 传统方法 整理
一文概览用于图像分割的CNN
Segmentation
A 2017 Guide to Semantic Segmentation with Deep Learning
图像分割(Image Segmentation) - 分水岭分割算法 -
DeconvNet
DeconvNet for Semantic Segmentation
DeconvNet
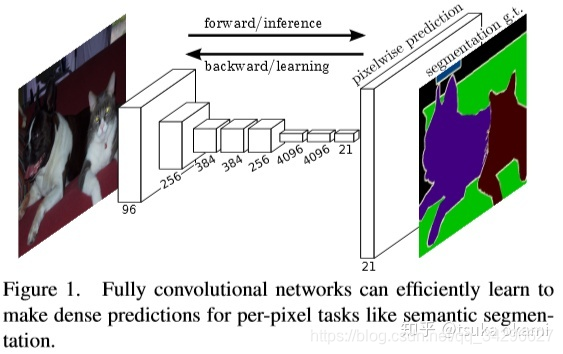
前面在tsuka okami:FCN-语义分割讲到FCN来做语义分割,简单来讲就将图像分类的CNN网络改成全卷积,但是全卷积网络输出时coarse的,所以最后再进行upsampling,以实现dense prediction。然而FCN也存在一些缺点,由于CNN网络的感受野大小固定,所以适合处理image中单个scale semantic,这样对于较大的semantic,可能只有部分pixels 分类正确, 或者对于较小的semantic 就直接忽略成背景,如Figure 1,
虽然FCN 使用了skips 结构来改善这一问题,但显得不够彻底,并且由于最后的upsampling过于简单,上采样率分别为8,16,以及32,导致目标的边缘信息丢失。这篇论文则提出了新的思路用于解决上述问题。
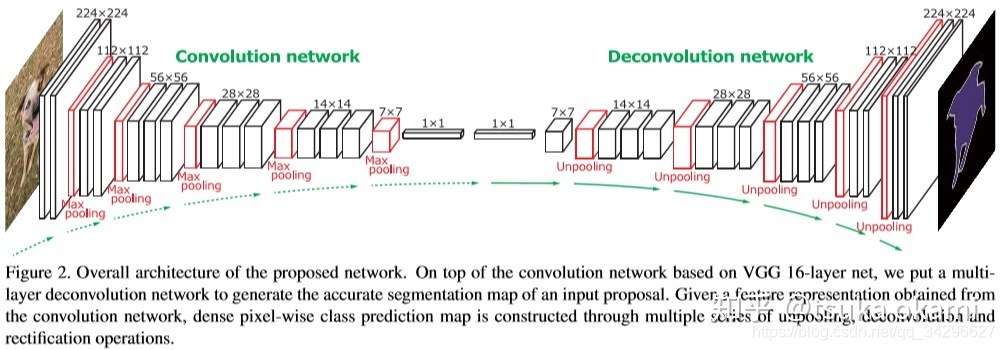
-
SegNet
SegNet图像分割网络直观详解
一文带你读懂 SegNet(语义分割)
《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》论文笔记
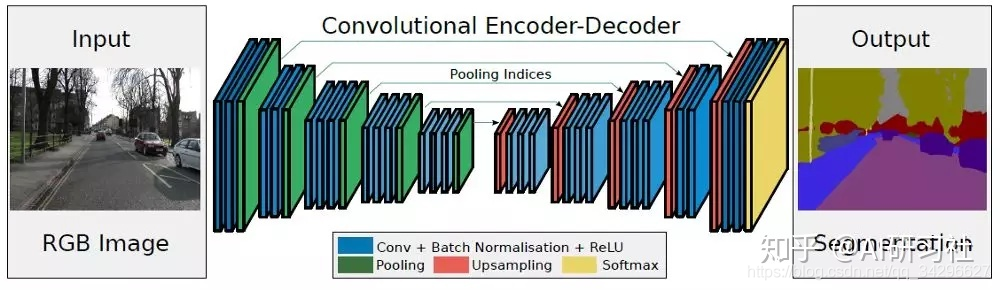
创新之处在于: Segnet相对于Deconvnet去掉了fc层,导致参数大大减少,训练速度增加很多。
还有一处不同是,在upsamplng过程中,Segnet使用的是convolution, 而Deconvnet使用的是Deconvolution.
segnet去掉了全连接层从而提升了速度,加了batch normalization加快了收敛抑制了过拟合,加了bayesion可以输出图像的不确定性分割数值,加了test batch dropout提升测试时的性能,加了带权重softmax应对分割样本不均衡现象。可以说,segnet是更实用的框架,另外还有一种U-Net,二者是Kaggle比赛中屡试不爽的框架。
-
UNet
用U-Net做Auto-Encoder图像重建
练习题︱图像分割与识别——UNet网络练习案例(两则)
Generic U-Net Tensorflow implementation for image segmentation -
DeepLab v1-v3
deeplab 系列文章总结
DeepLab系列的进击 -
RefineNet
-
PSPNet
-
MaskRCNN
令人拍案称奇的Mask RCNN
语义分割的展望
俗话说,“没有免费的午餐”(“No free lunch”)。基于深度学习的图像语义分割技术虽然可以取得相比传统方法突飞猛进的分割效果,但是其对数据标注的要求过高:不仅需要海量图像数据,同时这些图像还需提供精确到像素级别的标记信息(Semantic labels)。因此,越来越多的研究者开始将注意力转移到弱监督(Weakly-supervised)条件下的图像语义分割问题上。在这类问题中,图像仅需提供图像级别标注(如,有“人”,有“车”,无“电视”)而不需要昂贵的像素级别信息即可取得与现有方法可比的语义分割精度。
Resources
目标检测
深入理解one-stage目标检测算法(上篇)
深入理解one-stage目标检测算法(下篇)
一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
YOLO详解
实时物体检测:YOLO,YOLOv2和YOLOv3(一)
一文看尽目标检测:从 YOLO v1 到 v3 的进化之路
实时物体检测:YOLO,YOLOv2和YOLOv3(一)
目标检测—YOLOv1~YOLOv3 论文解析
如何应用MTCNN和FaceNet模型实现人脸检测及识别
从RCNN到SSD,这应该是最全的一份目标检测算法盘点
纹理合成再谈 - 一种非参数的方法
输入变量与输出变量均为连续变量的预测问题是回归问题;
输出变量为有限个离散变量的预测问题成为分类问题;
分类问题是指,给定一个新的模式,根据训练集推断它所对应的类别(如:+1,-1),是一种定性输出,也叫离散变量预测;
回归问题是指,给定一个新的模式,根据训练集推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测
分类与回归的区别
https://www.cnblogs.com/laiqun/p/6287906.html
Experiments
Yolo:先刷原理,再用yolo v3完整的去调整一次服装定位
1.4 实例分割
示例级别(Instance level)的图像语义分割问题也同样热门。该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)。
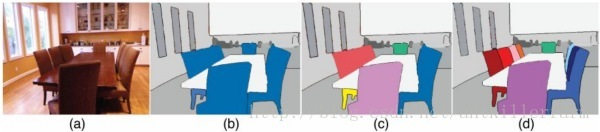
DeepLab
Mask RCNN
1.4 Image Matting
天干物燥 小心抠图-A journey of matting:传统抠图算法过渡到深度学习
图像精细分割技术开源代码整理
TensorFlow 实现抠图算法 Deep Image Matting(占坑)
1.5 生成模型
历史
VAE、Auto-Encoder、GAN、CGAN、DCGAN、WGAN、PGGAN、StyleGAN等等GAN变种
改进的意义是什么:TODO
应用场景多多:
生成图片、人脸合成、生成海报、图像修复
风格迁移
pix2pix(图像翻译):图像上色、图像修复、超分辨率
文本生成图片/图片生成文字
CycleGAN:非对称图像翻译
Text2Image:根据文本生成场景图像
Measurement
Resources
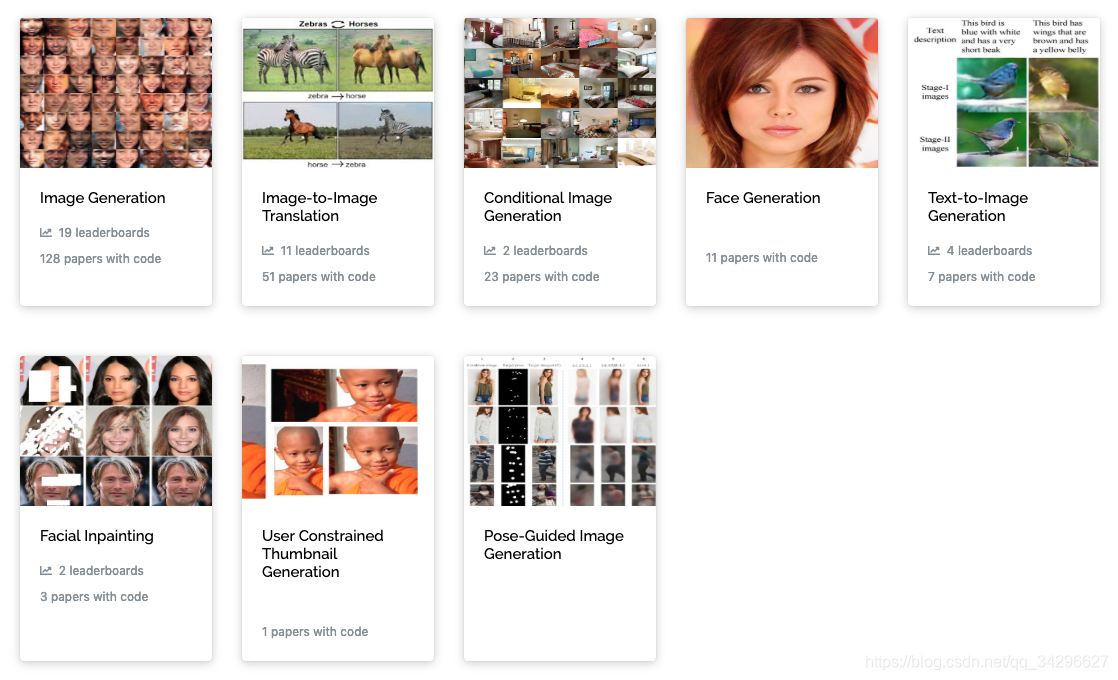
变分自编码器VAE:原来是这么一回事 | 附开源代码
VAE(Variational Autoencoder)的原理
李宏毅老师机器学习简单笔记 AE&VAE:李宏毅的课程讲解挺深入的,知识关联思维、发散思维很强,可以看看拓展拓展自己的学习思维。技术不能忘本,技术的历史迭代很重要,每一个时期的技术都是当代人算法智慧的结晶,算法是解决事情的一系列步骤集合,没有过时的算法,只有不适合的算法。
李宏毅老师GAN课程笔记(1) GAN简介
深度学习:什么是自编码器(Autoencoder)
漫谈autoencoder:降噪自编码器/稀疏自编码器/栈式自编码器(含tensorflow实现)
VAE(2)——基本思想
从网络设计到实际应用,深度学习图像超分辨率综述
李宏毅老师机器学习简单笔记 AE&VAE
图着色算法详解(Graph Coloring)
1.6 图像检索
人脸,人体,车辆可视为细分领域的细粒度检索,可通过检测得到region of interest,并且均为刚体,有着良好的关键点信息,具有明确语义的关键点信息对细粒度特征挖掘帮助极大。但是对于通用的图像检索,往往没有具有明确语义的关键点信息,比如拍立淘的商品检索,google landmark检索,cnn很难一把梭了.
论文关键点挑选是在表达提取之后,这和当前的先进行关键点检测再进行表达的方法有所不同(SIFT 和 LIFT )。传统的特征点检测主要是根据低级特征,在成像条件下进行重复性的关键点检测。然而对于高级识别任务如图像检索来说,挑选出可以判断不同目标的关键点也很重要。本文提出的方法实现了两个目的,第一是训练了一个在特征图中编码更高级语义信息的模型,第二是学习挑选适用于分类任务的判别特征。这和最近提出的根据SIFT 匹配收集训练数据的关键点检测方法LIFT[40]有所不同。尽管我们没有刻意让模型去学习位置和视角的变化,但它却自己主动完成了,这点和基于CNN的图像分类方法很相似。
图像相似度距离函数
改进的意义是什么:TODO
浅谈图像检索
【TPAMI重磅综述2018】 图像检索(上篇)
基于深度局部特征的图像检索
用余弦定理比较两张图片的相似度可行吗?为什么现在还没有搜图引擎?
早期的CBIR中都是使用全局特征,因为全局特征不能很好的表达图像语义,后来又出现了基于区域的图像检索(RBIR),那现在RBIR的研究现状怎么样?和那些基于sift特征点的方法相比,使用分割进行图像检索是否可行?
Google 图片搜索的原理是什么?
有没有什么快速的方法可以度量图像的相似度?
python图像识别---------图片相似度计算
Measurement
1.7 强化学习
基础
衍生之:
激活函数:
改进的意义是什么:TODO
损失函数:
改进的意义是什么:TODO
正则化:L1、L2
Batch Norm、Instance Norm
各种卷积类型
网络结构改进原则:
改进的意义是什么:TODO
常见的Tricks:
- 数据增强
- Fine-Tune
- Dropout
- 实际调参能力
能给你机会尝试的工作就不是个坏工作,从爬虫开始我尝试了多少爬取数据的方式,包括分类模型,GAN模型。尽量多的去尝试,只有不断尝试、不断做项目你才能弥补缺漏,收获到更全面的实战经历和有效知识。
深度学习的常见Task就这四个,但是每一个task下面会跟很多领域打交道,所以会有各种各式各样的数据集。可能面对特定的一个领域,有些通用的方法不适用,因此会研究出一些特定领域的算法(比如人脸、服装),研究出来的意义在于这一个领域有价值、有市场,所以能专门投入研究能力进去。
是否深度学习这样子学完之后,其他领域,比如机器学习,各个语言,编译原理,操作系统等等都可以以应用为切入点,提纲挈领地进行学习,原理+实践的学习。
2 調參
一定的初始化参数,一定的激活函数,一定的loss计算函数,一定的最优化函数,再配上一定的数据预处理技巧、卷积核技巧等构成了调参的基本。调参的方向标:Loss值。
深度学习终究是寻找一个使泛化性能足够好的(损失函数)极小值过程,它并不一定要求能搜索到非凸函数的最小值点,而需要模型的损失能得到显著性地降低,以收敛到一个可接受的极小值点。
Traget
調參的目的是讓Model收斂,而且是更快的收斂。避免/解决梯度爆炸、梯度消失等问题。
数据读取
Batch:分Batch的数据输入,是咋么进行计算的?
独家 | 如何改善你的训练数据集?(附案例)
卷积操作
卷积神经网络工作原理直观的解释
深入理解卷积层的操作步骤、操作过程、现象: CNN_book一书
Normalization 参数初始化
深度学习中的Normalization模型 - 讲的很好,有根源,另外CNN_book一书中批规范化一节也可以看看
- https://blog.csdn.net/u010158659/article/details/78635219
- https://blog.csdn.net/u014296502/article/details/78839881
- 详解深度学习中的Normalization,BN/LN/WN 推荐
- https://www.zhihu.com/search?type=content&q=%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0normalization
- https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=batch%20normalization%20instance%20normalization&oq=batch%2520normalization&rsv_pq=bf59d720000107a4&rsv_t=8c0cnPWNaHWil%2Fp0L%2Fn0t01qPUE3xm70J4Jr7%2BzmOK3AJxsMrygn4rRocmA&rqlang=cn&rsv_enter=1&inputT=12229&rsv_sug3=39&rsv_sug1=9&rsv_sug7=100&rsv_sug2=0&rsv_sug4=12537
- https://blog.csdn.net/Coco825211943/article/details/82226429
- https://blog.csdn.net/liuxiao214/article/details/81037416
- https://zhuanlan.zhihu.com/p/43200897
- https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=local%20response%20normalization&rsv_pq=b40846460001519a&rsv_t=59ccjm1rss%2B14LHL%2Fq27kBBWf8jbDHGah1c2%2FiGlcGv2LmtAlFpJ3OvwzVw&rqlang=cn&rsv_enter=1&rsv_sug3=2&rsv_sug1=1&rsv_sug7=001
- https://zhuanlan.zhihu.com/p/57609506
- https://www.baidu.com/s?wd=L1%20L2%20norm%E5%9C%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%AD%E7%9A%84%E4%BD%9C%E7%94%A8&rsv_spt=1&rsv_iqid=0x91b0074e00011df6&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&inputT=15714&rsv_t=a07bRfEJrD8O02WysyeEh53JuyCeKeB%2FRItUwENGvq%2BFyXy%2BlBthvU2c6FpNX77nh60C&oq=L2%2520norm&rsv_pq=b244c18000059017&rsv_sug3=60&rsv_sug1=12&rsv_sug7=100&rsv_sug2=0&rsv_sug4=18138&rsv_sug=1
- https://blog.csdn.net/yishidemeihao0105/article/details/80741775
- https://blog.csdn.net/u014381600/article/details/54341317
Activation
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的activation function,传入到下一层神经元;再经过该层神经元的activate,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的pattern,在各个领域取得state-of-the-art的结果。显而易见,activation function在深度学习中举足轻重,也是很活跃的研究领域之一。目前来讲,选择怎样的activation function不在于它能否模拟真正的神经元,而在于能否便于优化整个深度神经网络
聊一聊深度学习的activation function (很棒)
在不同数据应用场景下,如何选择不同的激活函数:
Loss Function
深度网络中的目标函数可谓整个网络模型的“指挥棒”, 通过样本的预测结果与真实标记产生的误差反向传播指导网络参数学习与表示学习。损失函数越小,一般就代表模型的鲁棒性越好,正是损失函数指导了模型的学习。我们在模型训练的同时,也要根据loss值的变化来做相应的调整。当然,loss函数的设定不属于调参的范畴。
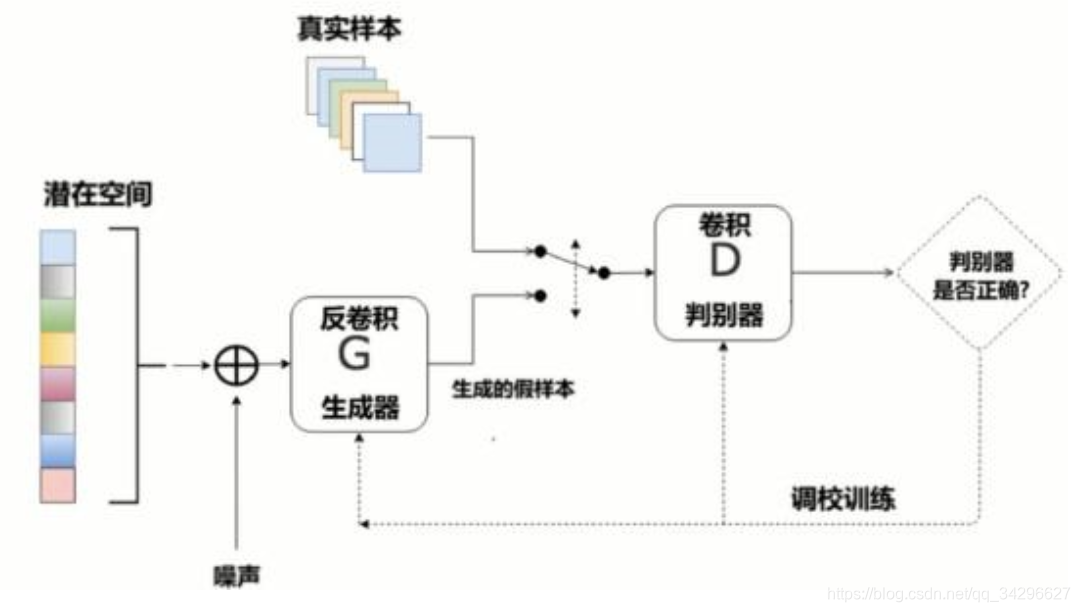
GAN使用了交叉熵,GAN只有一个损失
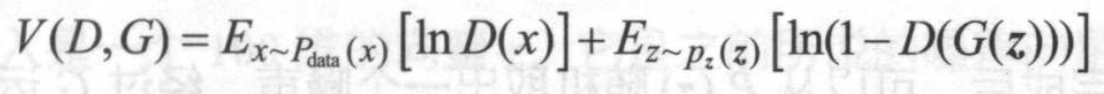
Style transfer的content loss使用了差的平方,style先是计算了两者的Gram矩阵,以此来代替style,loss函数则使用了两者差的平方。
softmax:
cross entropy(交叉熵)
binary cross entropy:
知乎搜索 - 损失函数
损失函数有哪些 推荐
常见损失函数小结
如何选择损失函数
交叉熵损失函数
常见损失函数小结
当我们优化损失函数时,我们在优化什么
损失函数综述
论文笔记 损失函数整理
AI初识境 深度学习中常用的损失函数有哪些(覆盖分类,回归,风格化,GAN等任务)
损失函数:L1 loss, L2 loss, smooth L1 loss
triplet network
Triplet Loss 损失函数:
Triplet Loss是深度学习中的一种损失函数,用于训练差异性较小的样本,如人脸等, Feed数据包括锚(Anchor)示例、正(Positive)示例、负(Negative)示例,通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本的相似性计算。MTCNN中就使用这个。
Triplet loss通常是在个体级别的细粒度识别上使用。
triplet loss 在深度学习中主要应用在什么地方?有什么明显的优势?
正则化:
为防止模型过拟合或达到其他训练目标(如希望得到稀疏解),正则项通常作为对参数的约束也会加入目标函数中一起指导模型训练。
在不同数据应用场景下,如何选择不同的损失函数:
-
权重衰减(weight decay)
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
权重衰减(weight decay)与学习率衰减(learning rate decay)
深度学习剖根问底:weight decay等参数的合理解释 -
L0,L1,L2范式及作用
Optimizer
要成功训练一个深度学习模型,选择一个适当的优化方法是非常重要的。虽然随机梯度下降法(SGD)通常可以一上手就发挥出不错的效果,不过 Adam 和 Adagrad 这样更先进的方法可以运行得更快,尤其是在训练非常深的网络时。然而,为深度学习设计优化方法是一件非常困难的事情,因为优化问题的本质是非凸问题
Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。(只是说慢,但还是能找到!)
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。
三.如何选择优化算法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,随着梯度变的稀疏,Adam 比 RMSprop 效果会好。整体来讲,Adam 是最好的选择。很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
6种机器学习中的优化算法:SGD,牛顿法,SGD-M,AdaGrad,AdaDelta,Adam
深度学习需要了解的四种神经网络优化算法
深度 | 从修正Adam到理解泛化:概览2017年深度学习优化算法的最新研究进展
常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
牛顿法和拟牛顿法 – BFGS, L-BFGS, OWL-QN
L-BFGS剖析
牛顿法与拟牛顿法学习笔记(一)牛顿法
牛顿法与拟牛顿法学习笔记(五)L-BFGS 算法
在不同数据应用场景下,如何选择不同的优化函数:
学习率衰减:
Neural Optimizer Search with Reinforcement Learning」(强化学习的神经网络优化器搜索):用强化学习的方法为神经网络(尤其是深度学习)找到最佳的优化算法/权重更新规则。https://arxiv.org/abs/1709.07417
权重衰减(weight decay)与学习率衰减(learning rate decay)
深度学习技巧之Early Stopping(早停法)
keras中的early stopping
防止过拟合
- 正则化:
- Dropout
PDF
troubleshooting-deep-neural-networks-01-19.pdf
Web
深度学习调参有哪些技巧? – 知乎
深度学习调参技巧总结
Resnet-18-训练实验-warm up操作
如何成为一名成功的“炼丹师”——DL训练技巧
CNN超参数优化和可视化技巧详解
Using convolutional neural nets to detect facial keypoints tutorial
三 代码能力要求
常用的深度学习框架和工具类:
- TensorFlow
- Pytorch
- Keras
- Numpy、Scipy:用Numpy构造最简单的神经网络
- TensorFlow Slim、TensorLayer等基于Tensorflow高阶API
- 深度学习的部署:TensorFlow server、spark等各种大数据工具、大数据平台
- 《GPU高性能编程CUDA实战 CUDA By Example》
这三个框架都不是一种编程模式,尤其是Tensorflow它是凌驾于Python之上的编程系统,所以一定要知其原理的使用这些框架,要知道每一个操作底层都是怎么计算的,最后能轻易的调用API或者自己手写搭建任意网络层,要能轻易复现paper里的新思想。可能到最后只是修改个Net类,修改修改loss函数,修改修改网络连接等等。
Training加速:多线程、GPU、多GPU、分布式
图像处理的学习也是一样,先将各个应用点都学一下,然后结合原理+OpenCV代码实现,看效果,涨经验,做到下次一见就能知道该怎么处理的程度。
做研究的方法和能力
四 阅读英文文献的能力
五 Resources
Awesome
深度学习——分类之Inception v4和Inception-ResNet
深度学习——分类之ResNet
瞎谈CNN:通过优化求解输入图像
滑動平均模型
滑動平均模型
变革尚未成功:深度强化学习研究的短期悲观与长期乐观
没人告诉你的大规模部署AI高效流程!

人脸识别/验证
Info
分类:1:1的人脸验证、1:N的人脸验证、N:N的人脸验证
人脸验证步骤:人脸检测/定位,人脸对齐,人脸特征点检测,人脸相似度
人脸验证任务中需要关心两个问题:一个是人脸特征提取,另一个就是如何判断是不是同一个人。特征提取的方法有LBP等传统方法,也有DeepID这样的深度学习方法。判断是不是同一个人的方法简单的有余弦相似度,复杂的有Joint Bayesian。本文主要的内容集中于人脸特征提取,就是使用Lighten CNN提取特征。
概述
为了得到更好的准确度,深度学习的方法都趋向更深的网络和多个模型ensemble,这样导致模型很大,计算时间长。本文提出一种轻型的CNN,在取得比较好的效果同时,网络结构简化,时间和空间都得到了优化,可以跑在嵌入式设备和移动设备上。
相关研究
用CNN进行人脸验证分为三种。一种是使用人脸分类的任务训练CNN提取特征,然后用分类器判断是不是同一个人。第二种是直接优化验证损失。第三种是将人脸识别和验证任务同时进行。本文框架是属于第一种。
原文:https://blog.csdn.net/tinyzhao/article/details/53127870
baseline
一种基于特征学习的跨年龄人脸验证方法
Abstract
本发明公开了一种基于特征学习的跨年龄人脸验证方法,包括如下步骤:(1)获取待对比的两幅人脸图像;(2)利用人脸特征点定位的方法对两幅人脸图像进行对齐操作;(3)分别对每幅图像进行特征提取,方法为:①通过深度卷积神经网络自动提取高层语义特征;②计算图像的LBP直方图特征;③将①和②中获得的特征进行融合,表达为特征向量;(4)采用余弦相似度方法计算步骤(3)获得的两幅图像的特征向量之间的距离,据此判断两幅图像是否来自同一人。本发明首次将深度网络应用到跨年龄人脸验证,同时创造性地将手工设计的LBP直方图特征与深度网络自主学习的特征进行融合,实现高层语义特征与低层特征的互补,具有更好的准确率。
Tech
A Review of Methods for Face Verification under Illumination Variation
Face Recognition and Verification: A Literature Review
Latent Factor Guided Convolutional Neural Networks for Age-Invariant Face Recognition
人脸识别/对齐/验证(MTCNN+FaceNet)复现 - bilibili
opencv+mtcnn+facenet+python+tensorflow 实现实时人脸识别
FaceNet - 机器之心
FaceNet解读整理
人脸识别之人脸对齐(一)–定义及作用
人脸关键点对齐
人脸检测、人脸对齐(MTCNN方法)
跨年龄人脸识别 Cross-Age Reference Coding
ECCV 2018 | 腾讯AI Lab提出正交深度特征分解算法,跨年龄人脸识别任务
人脸验证:Lightened CNN
人脸识别之DeepID模型
DeepID人脸识别算法之三代
face-verification paperwithcode
人脸检测(MTCNN)和人脸特征点检测(TCDCN)
基于深度卷积神经网络的跨年龄人脸识别
人脸识别之人脸验证(一)–Deepface
人脸检测、人脸对齐(MTCNN方法)
人脸特征点检测对人脸识别的作用
简单说几点,人脸矫正需要人脸特征点定位,另外人脸特征点定位还可以做表情识别,还有后期人脸比对、有兴趣还可以做人脸交换
人脸识别之人脸对齐(一)–定义及作用
人脸关键点是越多越好么?1000点和106点有什么区别?
如何应用 MTCNN 和 FaceNet 模型实现人脸检测及识别
人脸检测算法综述
人脸特征点检测basic:MTCNN原理
Facenet
FaceNet解读整理
DeepID人脸识别算法之三代
人脸识别之DeepID模型
年龄识别数据集IMDB-WIKI
跨年龄人脸识别 Cross-Age Reference Coding
Attention
Keras实现卷积神经网络(CNN)可视化
卷积神经网络可视化与可解释性
卷积神经网络特征图可视化(自定义网络和VGG网络)
卷积神经网络可视化和理解
浅谈attention机制
几篇较新的计算机视觉Self-Attention
图像领域 attention作用,应用场景
Attention机制详解(三)——Attention模型的应用
Attention模型理解
从2017年顶会论文看 Attention Model
深度学习中Attention Mechanism详细介绍:原理、分类及应用(V2)
Attention算法调研(视觉应用概况)
计算机视觉中attention机制的理解
当我们在聊Attention的时候,我们实际在聊什么?
attention模型方法综述
深度学习之卷积网络attention机制SENET、CBAM模块原理总结
ResidualAttentionNetwork-pytorch
caffe的prototxt文件
Residual-Attention-Network-tensorflow
Image Super-Resolution Using Very Deep Residual Channel Attention Networks Implementation in Tensorflow
HeatMap
self-attention-gan
开源:深入理解SAGAN,自注意力GAN处理图像GAN之父Ian Goodfellow大作
Ian Goodfellow等提出自注意力GAN,ImageNet图像合成获最优结果!
重磅突破:从36.8到52.52,引入自我注意力模块的SAGAN















 4469
4469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









