









本文是观看以下视频的笔记:
https://www.bilibili.com/video/BV1CU4y1i7jn/?p=4&spm_id_from=pageDriver
其他参考
https://zhuanlan.zhihu.com/p/614147698
https://zhuanlan.zhihu.com/p/563661713
这个写的非常详细:
https://www.zhihu.com/question/574586781/answer/3001481574
符号定义
- xT: 符合高斯分布的噪声
- x0: 一个符合GT的图像,无噪声的,clean image
- T: 时间步
- xt: 第t步的图像,要从他推出t-1的图像。(一直推下去的话可以推出x0)
- β t \beta_t βt:noise rate,关于t的固定序列,含义是每一步t要加的噪声的比例。
- α t \alpha_t αt:signal rate,关于t的固定序列, α t \alpha_t αt= 1- β t \beta_t βt,含义是每一步t保留的上一步图像比例。通常会被设置为 lim t → T α t = 0 \lim _{t \rightarrow T} \alpha_t=0 limt→Tαt=0。具体定义是: x t = α t x t − 1 + 1 − α t ϵ t \mathbf{x}_t=\sqrt{\alpha_t} \mathbf{x}_{t-1}+\sqrt{1-\alpha_t} \boldsymbol{\epsilon}_{t} xt=αtxt−1+1−αtϵt
- q:正向扩散:加噪声
- p:逆向扩散:去噪声
- ϵ t \boldsymbol{\epsilon}_t ϵt 或 z t \mathbf{z}_t zt: xt相比xt-1加的噪声,服从标准正态分布。本文中z和epsilon混用
- ϵ \boldsymbol{\epsilon} ϵ:不是t这一步的噪声,而是前面的噪声叠加后的结果,还是以服从标准正态分布
- z波浪:网络预测的噪声,希望他尽可能接近真实的z
概述
https://www.bilibili.com/video/BV16N4y177Wk/?spm_id_from=333.788&
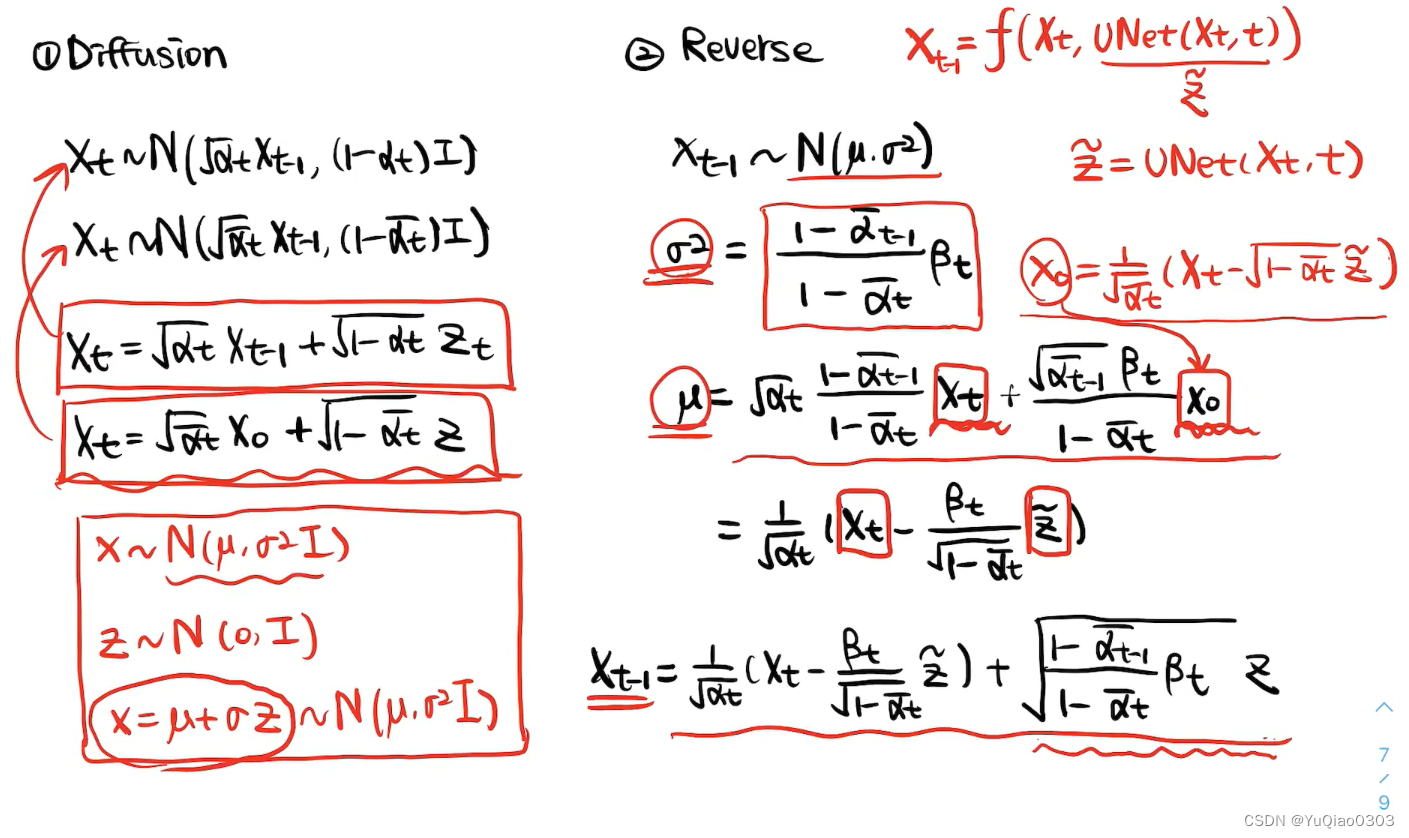

加噪(Forward,training)
初始定义: q ( x t ∣ x t − 1 ) q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right) q(xt∣xt−1)
(“:=” 是定义为的意思)
- q ( x t ∣ x t − 1 ) : = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right):=\mathcal{N}\left(\mathbf{x}_t;\sqrt{\alpha_t} \mathbf{x}_{t-1}, (1-\alpha_t\right)\mathbf{I}) q(xt∣xt−1):=N(xt;αtxt−1,(1−αt)I) 或 q ( x t ∣ x t − 1 ) ∼ N ( α t x t − 1 , ( 1 − α t ) I ) q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)\sim \mathcal{N}\left(\sqrt{\alpha_t} \mathbf{x}_{t-1}, (1-\alpha_t\right)\mathbf{I}) q(xt∣xt−1)∼N(αtxt−1,(1−αt)I), 也即
- x t = α t x t − 1 + 1 − α t ϵ t \mathbf{x}_t=\sqrt{\alpha_t} \mathbf{x}_{t-1}+\sqrt{1-\alpha_t} \boldsymbol{\epsilon}_{t} xt=αtxt−1+1−αtϵt, 其中 ϵ t − 1 ∼ N ( 0 , 1 ) \boldsymbol{\epsilon}_{t-1} \sim \mathcal{N}(0,1) ϵt−1∼N(0,1)
使用重参数技巧一步步展开可得: q ( x t ∣ x 0 ) q\left(\mathbf{x}_t \mid \mathbf{x}_0\right) q(xt∣x0)
-
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_t ; \sqrt{\bar{\alpha}_t} \mathbf{x}_0,\left(1-\bar{\alpha}_t\right) \mathbf{I}\right) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I) 或 q ( x t ∣ x 0 ) ∼ N ( α ˉ t x 0 , ( 1 − α ˉ t ) I ) q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)\sim \mathcal{N}\left(\sqrt{\bar\alpha_t} \mathbf{x}_0, (1-\bar\alpha_t\right)\mathbf{I}) q(xt∣x0)∼N(αˉtx0,(1−αˉt)I)也即
-
x t = α ˉ t x 0 + 1 − α ˉ t ϵ \mathbf{x}_t=\sqrt{\bar\alpha_t} \mathbf{x}_0+\sqrt{1-\bar\alpha_t} \boldsymbol{\epsilon} xt=αˉtx0+1−αˉtϵ, 其中 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t=\prod_{i=1}^t \alpha_i αˉt=∏i=1tαi, ϵ ∼ N ( 0 , 1 ) \boldsymbol{\epsilon} \sim \mathcal{N}(0,1) ϵ∼N(0,1)。
-
注意区分“每一步t的噪声 ϵ t \boldsymbol{\epsilon}_t ϵt”和“他们叠加后的噪声 ϵ \boldsymbol{\epsilon} ϵ ”,
- 叠加公式是 a X 1 + b X 2 ∼ N ( a μ 1 + b μ 2 , a 2 σ 1 2 + b 2 σ 2 2 ) \mathrm{aX_1}+\mathrm{bX_2}\sim N\left(\mathrm{a}\mu_1+b\mu_2,\mathrm{a}^2\sigma_1^2+b^2\sigma_2^2\right) aX1+bX2∼N(aμ1+bμ2,a2σ12+b2σ22))
-
具体推导过程如下:
-
x t = α t x t − 1 + 1 − α t ϵ t = α t ( α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 1 ) + 1 − α t ϵ t = α t α t − 1 x t − 2 + α t − α t α t − 1 2 + 1 − α t 2 ϵ ˉ t − 1 ; 两个相互独立的正态分布的叠加仍是正态分布 = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 1 = … = α ˉ t x 0 + 1 − α ˉ t ϵ \begin{aligned} \mathbf{x}_{t}& =\sqrt{\alpha_{t}}\mathbf{x}_{t-1}+\sqrt{1-\alpha_{t}}\epsilon_{t} \\ &=\sqrt{\alpha_t}\big(\sqrt{\alpha_{t-1}}\mathbf{x}_{t-2}+\sqrt{1-\alpha_{t-1}}\epsilon_{t-1}\big)+\sqrt{1-\alpha_t}\epsilon_{t} \\ &=\sqrt{\alpha_t\alpha_{t-1}}\mathbf{x}_{t-2}+\sqrt{\sqrt{\alpha_t-\alpha_t\alpha_{t-1}}^2+\sqrt{1-\alpha_t}^2}\bar{\epsilon}_{t-1} ; 两个相互独立的正态分布的叠加仍是正态分布\\ &=\sqrt{\alpha_t\alpha_{t-1}}\mathbf{x}_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}\bar{\epsilon}_{t-1} \\ &=\ldots \\ &=\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon \end{aligned} xt=αtxt−1+1−αtϵt=αt(αt−1xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1xt−2+αt−αtαt−12+1−αt2ϵˉt−1;两个相互独立的正态分布的叠加仍是正态分布=αtαt−1xt−2+1−αtαt−1ϵˉt−1=…=αˉtx0+1−αˉtϵ
或者看下图:

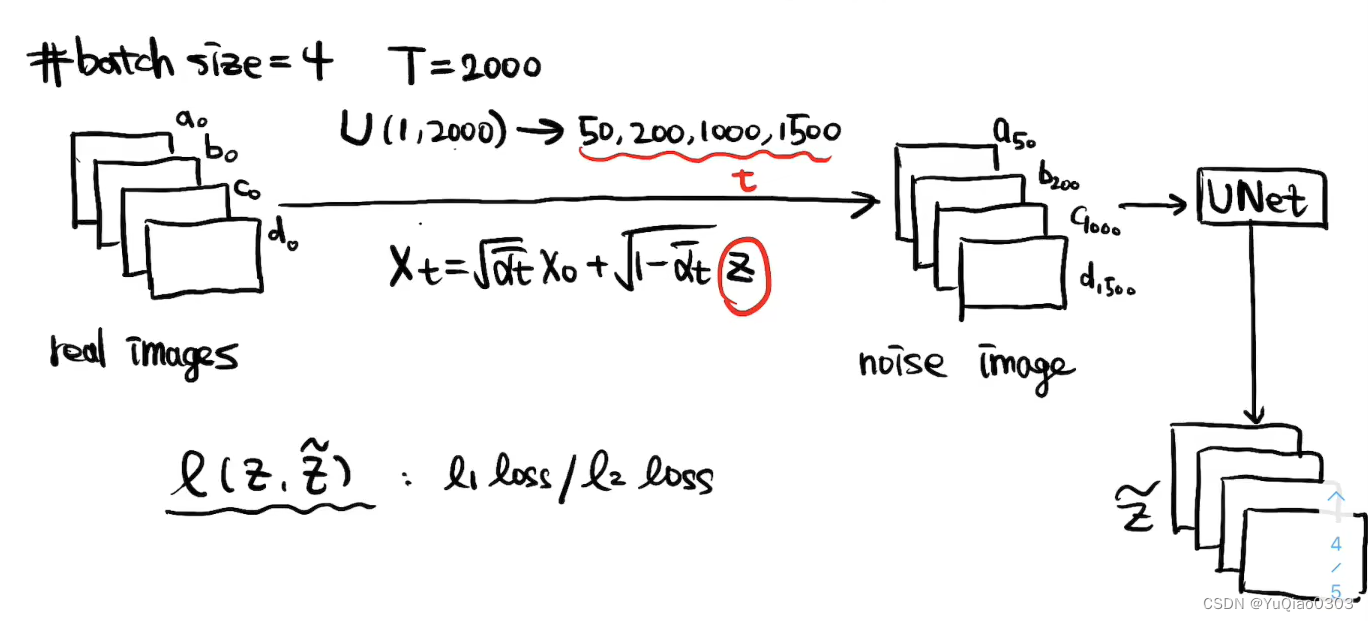
training
- 每一个不同的t,对应的噪声都是不同的(重新随机采的)!
- 网络预测不是某一步相比上一步增加的噪声
ϵ
t
\boldsymbol{\epsilon}_t
ϵt,而是
ϵ
t
\boldsymbol{\epsilon}_t
ϵt,
ϵ
t
−
1
\boldsymbol{\epsilon}_{t-1}
ϵt−1…最后叠加得到的
ϵ
\boldsymbol{\epsilon}
ϵ

去噪(Reverse, inference, sampling)
目标是 p ( x t − 1 ∣ x t , x 0 ) p(\mathbf{x}_{t-1}|\mathbf{x}_{t},\mathbf{x}_0) p(xt−1∣xt,x0)
现在我们有:
q
(
x
t
∣
x
t
−
1
)
q(\mathbf{x}_t \mid \mathbf{x}_{t-1})
q(xt∣xt−1) ,
q
(
x
t
∣
x
0
)
q(\mathbf{x}_t \mid \mathbf{x}_0)
q(xt∣x0) ,
p
(
x
T
)
=
N
(
x
T
;
0
,
I
)
p(\mathbf{x}_T)=\mathcal{N}(\mathbf{x}_T ; \mathbf{0}, \mathbf{I})
p(xT)=N(xT;0,I)
要求的是:
p
(
x
t
−
1
∣
x
t
)
p(\mathbf{x}_{t-1} \mid \mathbf{x}_t)
p(xt−1∣xt) 。
这个东西不好弄,我们改为求
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(\mathbf{x}_{t-1}|\mathbf{x}_{t},\mathbf{x}_0)
p(xt−1∣xt,x0)
开始,
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
0
)
(
贝叶斯公式
)
=
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
0
)
(马尔科夫假设)
\begin{aligned} &p(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)\\ &=p(\mathbf{x}_t|\mathbf{x}_{t-1},\mathbf{x}_0)\frac{p(\mathbf{x}_{t-1}|\mathbf{x}_0)}{p(\mathbf{x}_t|\mathbf{x}_0)} (贝叶斯公式)\\ &=p(\mathbf{x}_t|\mathbf{x}_{t-1})\frac{p(\mathbf{x}_{t-1}|\mathbf{x}_0)}{p(\mathbf{x}_t|\mathbf{x}_0)}(马尔科夫假设) \end{aligned}
p(xt−1∣xt,x0)=p(xt∣xt−1,x0)p(xt∣x0)p(xt−1∣x0)(贝叶斯公式)=p(xt∣xt−1)p(xt∣x0)p(xt−1∣x0)(马尔科夫假设)
第一个等号:贝叶斯公式(将右边分母挪到左边后,两边就都是x0条件下xt-1和xt同时发生的概率)
第二个等号:由于从t-1到t这个加噪的过程是马尔科夫过程,即xt只与xt-1有关,而与更小的时间步无关,所以 p ( x t ∣ x t − 1 , x 0 ) = p ( x t ∣ x t − 1 , x 0 ) p(\mathbf{x}_t|\mathbf{x}_{t-1},\mathbf{x}_0)=p(\mathbf{x}_t|\mathbf{x}_{t-1},\mathbf{x}_0) p(xt∣xt−1,x0)=p(xt∣xt−1,x0)
最后的这三项都是已知的:
p
(
x
t
∣
x
t
−
1
)
:
=
N
(
x
t
;
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
q
(
x
t
−
1
∣
x
0
)
=
N
(
x
t
−
1
;
α
ˉ
t
−
1
x
0
,
(
1
−
α
ˉ
t
−
1
)
I
)
p\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right):=\mathcal{N}\left(\mathbf{x}_t;\sqrt{\alpha_t} \mathbf{x}_{t-1}, (1-\alpha_t\right)\mathbf{I})\\ q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_t ; \sqrt{\bar{\alpha}_t} \mathbf{x}_0,\left(1-\bar{\alpha}_t\right) \mathbf{I}\right)\\ q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1} ; \sqrt{\bar{\alpha}_{t-1} } \mathbf{x}_0,\left(1-\bar{\alpha}_{t-1} \right) \mathbf{I}\right)
p(xt∣xt−1):=N(xt;αtxt−1,(1−αt)I)q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)
考虑到:
正态分布
f
(
x
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
f
(
x
)
∝
e
−
(
x
−
μ
)
2
2
σ
2
正态分布 f(x) = \frac{1}{\sigma\sqrt{2\pi}} e{-\frac{(x-\mu)2}{2\sigma^2}} \\ f(x) \propto e{-\frac{(x-\mu)2}{2\sigma^2}}
正态分布f(x)=σ2π1e−2σ2(x−μ)2f(x)∝e−2σ2(x−μ)2
把所有的正态分布换成这个正比于的表达方式,我们凑一下
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(\mathbf{x}_{t-1} \mid \mathbf{x}_t,\mathbf{x}_0)
p(xt−1∣xt,x0) 也写成这个形式:
下方的推导有以下注意点:
- exp指数部分的常数如果拿到exp外面, 不影响“正比于”这件事,因此我们都忽略掉;
- 注意,由于目标是 p ( x t − 1 ∣ x t ) p(\mathbf{x}_{t-1} \mid \mathbf{x}_t) p(xt−1∣xt),我们最后的结果中只保留xt这个变量,用xt和预测的z波浪来表达x0
重参数技巧:写成一个新的正态分布,并表示出其均值和方差
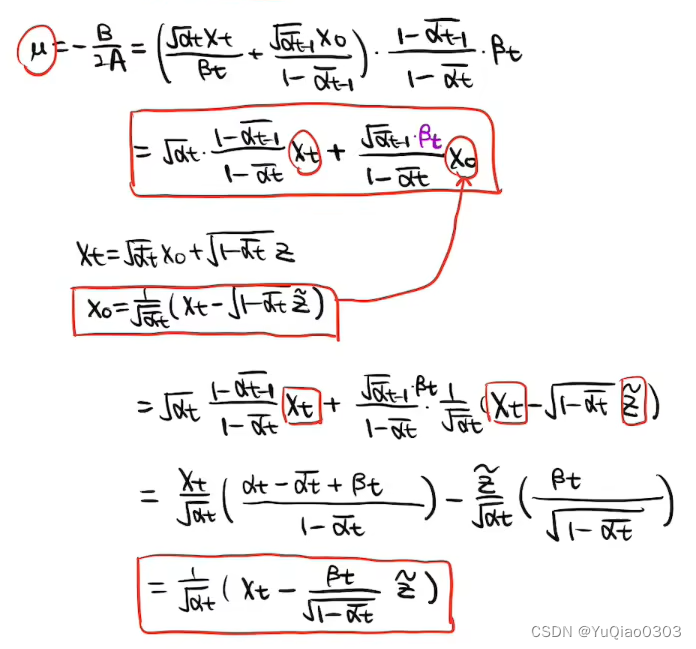
p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x t − 1 ) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) ∝ exp { − 1 2 ( ( x t − α t x t − 1 ) 2 1 − α t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) } \begin{aligned} &p(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)\\ &=p(\mathbf{x}_t|\mathbf{x}_{t-1})\frac{p(\mathbf{x}_{t-1}|\mathbf{x}_0)}{p(\mathbf{x}_t|\mathbf{x}_0)}\\ &{\propto\exp \left\{-\frac{1}{2}\left(\frac{\left(x_{t}-\sqrt{\alpha_{t}}x_{t-1}\right)^{2}}{1-\alpha_{t}}+\frac{\left(x_{t-1}-\sqrt{\bar\alpha_{t-1}} x_{0}\right)^{2}}{1-{\bar\alpha_{t-1}}}-\frac{\left(x_{t}-\sqrt{\bar\alpha_{t}} x_{0}\right)^{2}}{1-\bar\alpha_{t}}\right)\right\}}\\ \end{aligned} p(xt−1∣xt,x0)=p(xt∣xt−1)p(xt∣x0)p(xt−1∣x0)∝exp{−21(1−αt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2)}
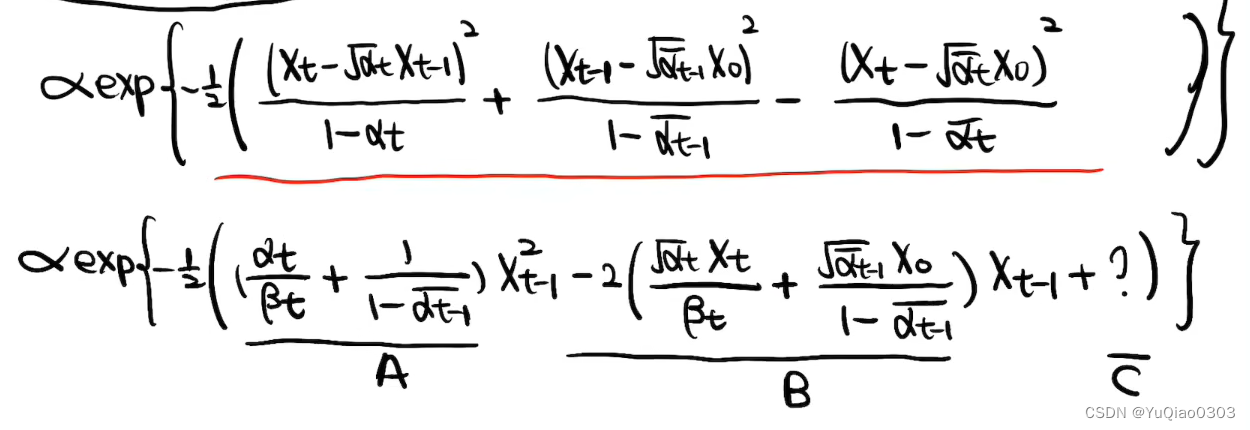
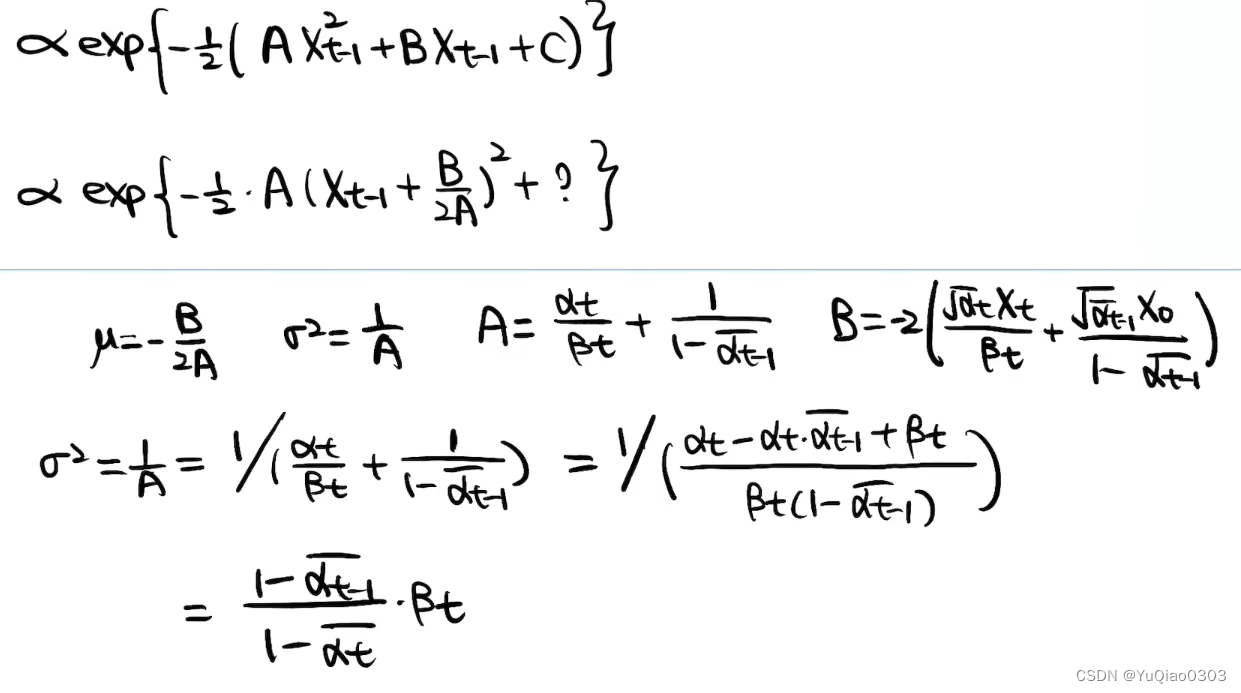
至此得到了方差,发现是固定的常数。下面继续求均值μ。
注意
- 我们在这里把x0 用xt和网络预测的噪声z波浪来表示,从而消掉x0并引入z波浪
- 下面没有等号的两行是单独的,要带进μ的等式的内容
去噪总结
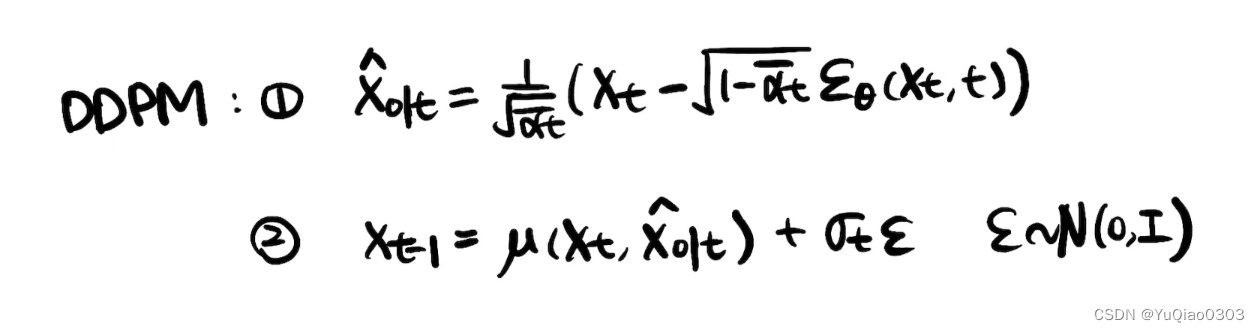
至此,我们求出了
p
(
x
t
−
1
∣
x
t
,
x
0
)
∝
N
(
μ
,
σ
2
)
,其中
σ
2
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
⋅
β
t
,
μ
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
=
1
α
t
(
x
t
−
β
t
1
−
α
t
ˉ
z
^
)
p(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)\propto \mathcal{N(\mu, σ^2 )},其中\\ \sigma^2 = \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t,\\ \mu=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}\mathbf{x}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}\mathbf{x}_0\\=\frac{1}{\sqrt{\alpha_{t}}}(\mathbf{x}_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha_{t}}}}\hat{z})
p(xt−1∣xt,x0)∝N(μ,σ2),其中σ2=1−αˉt1−αˉt−1⋅βt,μ=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0=αt1(xt−1−αtˉβtz^)
也就是说,如果已知x0和xt,那么xt-1满足一个标准正态分布,其方差是常数,均值与网络预测的z波浪有关
因此,根据正态分布的重参数化技巧,
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
μ
+
σ
z
=
1
α
t
(
x
t
−
β
t
1
−
α
t
ˉ
z
^
)
+
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
⋅
β
t
z
\begin{aligned} & p(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) \\ &= \mu + \sigma \mathbf{z} \\ &=\frac{1}{\sqrt{\alpha_{t}}}(\mathbf{x}_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha_{t}}}}\hat{z}) +\sqrt{\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t} \mathbf{z} \end{aligned}
p(xt−1∣xt,x0)=μ+σz=αt1(xt−1−αtˉβtz^)+1−αˉt1−αˉt−1⋅βtz
其中z属于标准正态分布。
那么,为什么这里最后的z要用一个噪声采样而不直接设为0呢?如果全0的话,其实概率很低,符合正态分布的概率更高一些。
Sampling
上面那个式子直接就可以写成这样了,问题仅在于,我们省略的常数去哪 里了。不知道,可能刚好算出来还是没了吧。

- 这个sigma t不一定要等于刚才求的那个标准差,比它小也行。
- 注意,最后一步不再加噪声了















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









