







概述
本文是观看以下视频的笔记:
https://www.bilibili.com/video/BV1VP411u71p/?spm_id_from=333.788&
论文:Generative Modeling by Estimating Gradients of the Data Distribution (NeurIPS2019)
-
注意,这篇比DDPM更早

-
likelihood-based methods对网络结构的设计有很大限制,但score-based只要输入输出维度一样就行了;
-
gan就是太难train 了。在生成和判别之间要权衡。但咱们score-based就不用,就一个loss完事儿。
方法
- 定义score:对数概率的梯度
- 核心思路:之前的方法都是学习概率分布本身;现在我们学习score。这样我们就可以根据score指示的方向一步步走到正确的地方
- 首先用某种方法估计出score
- 然后,随机初始化噪声,然后按照score走一步;再走一步;迭代,组中走到正确的位置(走一步怎么走是根据郎之万动力学的公式)
怎么估计score(估计噪声就是估计score)
- 首先套用DDPM的噪声假设, q ( x t ∣ x 0 ) ∼ N ( α ˉ t x 0 , ( 1 − α ˉ t ) I ) q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)\sim \mathcal{N}\left(\sqrt{\bar\alpha_t} \mathbf{x}_0, (1-\bar\alpha_t\right)\mathbf{I}) q(xt∣x0)∼N(αˉtx0,(1−αˉt)I)或 x t = α ˉ t x 0 + 1 − α ˉ t ϵ \mathbf{x}_t=\sqrt{\bar\alpha_t} \mathbf{x}_0+\sqrt{1-\bar\alpha_t} \boldsymbol{\epsilon} xt=αˉtx0+1−αˉtϵ (1),
- 根据高斯分布的定义,写出p(xt)的表达式:
- p ( x t ) ∝ exp { − ( x t − α ˉ t x 0 ) ⊤ ( x t − α ˉ t x 0 ) 2 ( 1 − α ˉ t ) } p(\mathbf{x}_{t})\propto\exp\{-\frac{(\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0})^{\top}(\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0})}{2(1-\bar{\alpha}_{t})}\} p(xt)∝exp{−2(1−αˉt)(xt−αˉtx0)⊤(xt−αˉtx0)}
- 根据这个式子,求出对数梯度:
- ∇ x t log p ( x t ) = − x t − α ˉ t x 0 1 − α ˉ t \nabla_{\mathbf{x}_{t}}\log p(\mathbf{x}_{t})=-\frac{\mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0}}{1-\bar{\alpha}_{t}} ∇xtlogp(xt)=−1−αˉtxt−αˉtx0
- 观察式(1), 发现对数梯度的分子就是 1 − α ˉ t ϵ \sqrt{1-\bar\alpha_t} \boldsymbol{\epsilon} 1−αˉtϵ
- 也就是说,加在原图上的噪声,和我们要求的pxt的对数梯度,只相差一个系数。所以估计噪声就可以估计出梯度的方向
- (个人理解):这里实际上说明,我们DDPM定义的,通过权重来增加的噪声(x0和噪声的加权和),某种程度上相当于在对数空间直接增加噪声?

怎么采样(给原始数据加噪声,早期大后来变小)
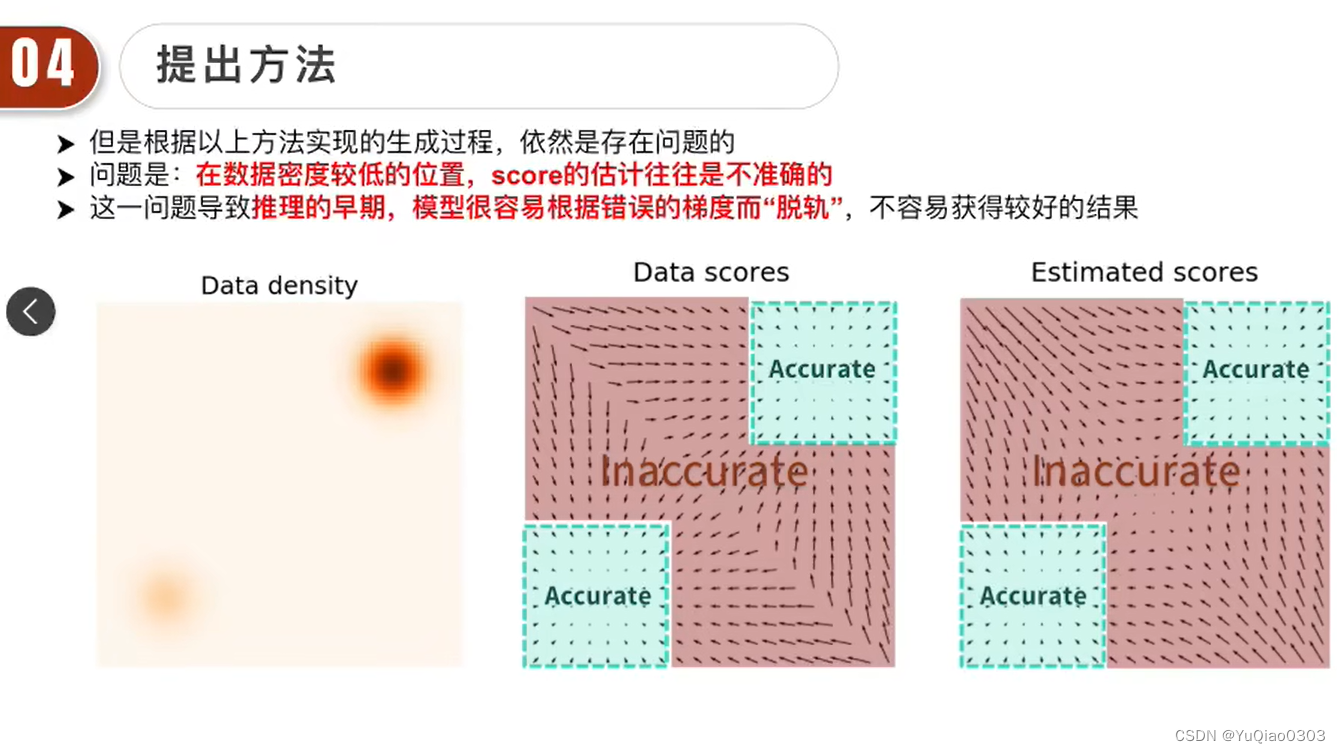
- 问题:在数据密度较低的位置,score的估计往往不准,这样很难走进准确的区域
- 解决方法:给原始数据加噪声,这样原始数据的分布范围就变大了,低密度区域就变小了,能准确估计score的区域就变大了
- 新的问题:噪声加了,原始数据就破坏了呀;噪声越强,破坏越强;噪声越小,score又无法准确估计
- 解决方法:在推理的不同阶段加不同强度的噪声,从大到小
- 这不就是DDPM了吗?噪声按这个权重,早期大,晚期小
- 注意,似乎是在training和inference的时候都加了噪声了

加噪声前,计算的score在大片区域不太准:
加噪声后,计算的score更准:

最终的采样算法:
- L是Level,每一个Level i 都有自己的步长αi和和噪声
- 没看懂在那里加的噪声

inpainting (来自补充材料)
- 每次采样得到一个noisy image,
- 下一步之前,我就直接把没mask的部分用gt+噪声代替
- 那感觉和RePaint一模一样啊?

还没有细究的地方:
- training的时候是怎么加的噪声?
- inference那个算法里面具体哪里体现了加噪声的?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









