







导入
import pandas as pd
若使用的是Anaconda集成包则可直接使用,否则可能需要下载:pip install pandas
读取表格并得到表格行列信息
df=pd.read_excel('test.xlsx')
height,width = df.shape
print(height,width,type(df))
表格如下:
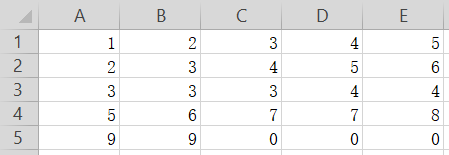
得到如下输出,为一个4行5列的数据块,为DataFrame格式:

直接print(df)得到的结果:
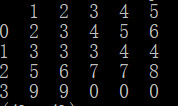
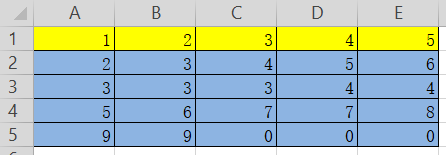
对比结果和表格,很显然表格中的第一行(黄色高亮部分)被定义为数据块的列下标,而实际视作数据的是后四行(蓝色高亮部分);并且自动在表格第一列之前加了一个行索引{0,1,2,3}。
提取数据放入数组中
x = np.zeros((height,width))
for i in range(0,height):
for j in range(1,width+1): #遍历的实际下标,即excel第一行
x[i][j-1] = df.ix[i,j]
print(x.shape)
print(x)
用np.zeros()方法定义一个初试值全为0的二维数组(需要导入numpy库),用df.ix[i,j]读取数据并复制入二维数组中,其中for i in range(0,height)循环表示从下标0到下标height-1(不包含height),得到的输出如下:

对代码做一些补充说明:
从DataFrame结构的数据中取值有三种常用的方法:
#第一种方法:ix
df.ix[i,j] # 这里面的i,j为内置数字索引,行列均从0开始计数
df.ix[row,col] # 这里面的row和col为表格行列索引,也就是表格中的行与列名称
#第二种方法:loc
df.loc[row,col] # loc只支持使用表格行列索引,不能用内置数字索引
#第三种方法:iloc
df.iloc[i,j] # iloc只支持使用内置数字索引,不能用表格行列索引
由于ix方法对两种索引都支持,所以这里就有一个问题:如果表格行列索引也是数字怎么办? 比如我上述例子中列索引为表格的第一行{1,2,3,4},而行索引为读取时自动添加的。
经过实验这种情况将会优先使用表格行列索引,也就对应了上面代码中得到的结果。不过为了不在使用时产生混乱,我个人建议还是使用loc或者iloc而不是ix为好。
在表格中自定义行列索引的情况
如果表格是下面这样的形式:
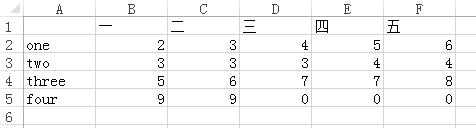
想要让读取得到的DataFrame行索引为{‘one’,‘two’,‘three’,‘four’},列索引为{‘一’,‘二’,‘三’,‘四’,‘五’}。如果直接使用read_excel(filename),虽然列索引会默认为第一行,但是行索引并不会默认为第一列,而是会自动添加一个{0,1,2,3}作为行索引。因此需要达到我们的目的需要设定一下读取时的参数,如下:
df = pd.read_excel(filename,index_col=0) # 即指定第一列为行索引
print(df)
print('第0行第1列的数据为:',df.iloc[0,1])
print('第three行第二列的数据为:',df.loc['three','二'])
得到的输出如下所示:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









