






前言
拿到了两个大厂的offer,我在互联网这边的秋招基本结束了,接下来安心准备国企秋招。
在互联网这边春招、秋招过程中我把面试官问的问题,和其它一些比较重要的知识点总结了一下分享给大家,是个人总结所以可能有的地方说得也不太对,欢迎大家指正!
算法知识点问答汇总
1. 为什么网络输入需要进行归一化
神经网络学习过程本质就是为了学习数据的内部分布(或者说内部数据之间的差异),一旦训练数据与测试数据的分布(总体数据分布)不同,那么网络的泛化能力也大大降低。另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
2. 为什么要BatchNorm
参考1:https://blog.csdn.net/qq_25737169/article/details/79048516
参考2:https://zhuanlan.zhihu.com/p/33173246
- 内部协方差平移:对于深层神经网络来说,即使输入数据已做标准化,随着逐层计算依旧容易造成中间层输出发生剧烈变化,使隐藏层的数据分布被改变(称之为internal covariate shift现象),导致下一层网络训练变困难。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
- BatchNorm:Batchnorm是归一化的一种手段,利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使得整个神经网络在各层的中间输出的数值更稳定。BatchNrom虽然将数据变为均值为0,方差为1,但是为了使模型的表达能力不因为规范化而下降(即也需要尊重上一层网络的学习成果,使部分数据保留在激活函数的饱和区),BatchNorm中还引入了可训练的两个偏移参数 γ \gamma γ和 β \beta β。
- 主要作用(优势):主要有两个核心的点:一是BatchNorm使每层的输出分布类似,降低了层与层之间的耦合,增强了层与层之间的相互独立性(或者说减少了因前一层变动而影响该层参数的重新训练),这一点可以使训练时使用更大的学习率,且对初始权重不那么敏感;二是缓解了激活函数的输入饱和(特别是sigmoid)而导致的梯度消失问题。
3. BatchSize的选取
batch太小,计算出的梯度下降方向震荡,或是出现前后更新方向相抵消。导致难以学习,或者无法收敛。
batch太大,会导致下降方向无太大变化,求解最优解依赖于学习率的设置,相比batch较小时会消耗更长的时间。
4. 神经网络前向反向传播流程
参考之前的博客:https://blog.csdn.net/qq_34392457/article/details/108370004?spm=1001.2014.3001.5501
前向传播其实就是加权和以及激活函数,反向传播一般就是算loss的梯度(链式求导法则)。
5. SGD与Adam
参考1:https://blog.csdn.net/angel_hben/article/details/104620694
参考2:http://www.ijiandao.com/2b/baijia/63540.html
- BGD与SGD与MBGD:梯度下降算法就是神经网络权重更新的时候将其往梯度相反的方向更新,SGD虽然相比GD需要走更多部才能到最优,但是可以有效地逃离鞍点(防止局部最优),MBGD位于两者之间,若设k为每次更新所使用到的样本,
k = { 1 , if SGD n , if MBGD (n=batch_size) m , if BGD (m=all example) k= \begin{cases} 1, & \text {if SGD} \\ n, & \text{if MBGD (n=batch\_size)} \\ m, & \text{if BGD (m=all example)}\end{cases} k=⎩⎪⎨⎪⎧1,n,m,if SGDif MBGD (n=batch_size)if BGD (m=all example)不过在Pytorch中这三个好像就整合成了一个API(torch.optim.SGD),然后自己通过设置batch_size来决定用哪种优化方式。 - Adam:Adam也属于一种梯度下降算法,Adam使用动量和自适应学习率来加快收敛速度。其思路与AdaGrad(适应性梯度算法)和RMSProp(均方根传播)类似,都是自适应地调整梯度下降时的学习率,使网络学习更迅速有效。
6. ResNet
参考:https://blog.csdn.net/nini_coded/article/details/79582902
- 模型退化现象:随着网络层数的加深与训练轮数的提高,模型的loss不但没有减少反而增加了,在训练集和测试集上的表现都变差或者没有增加(因此既不是欠拟合也不是过拟合)。模型退化可以简单理解为在模型的每层中只有少量隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同输入都是相同反应。
- 残差的设计:直觉来说,深层网络即使达不到更好的效果至少也不会比浅层模型差,残差的初衷是为了让模型的内部结构至少有恒等映射的能力,以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化。而且这里一个Block中必须至少含有两个层,否则无效:
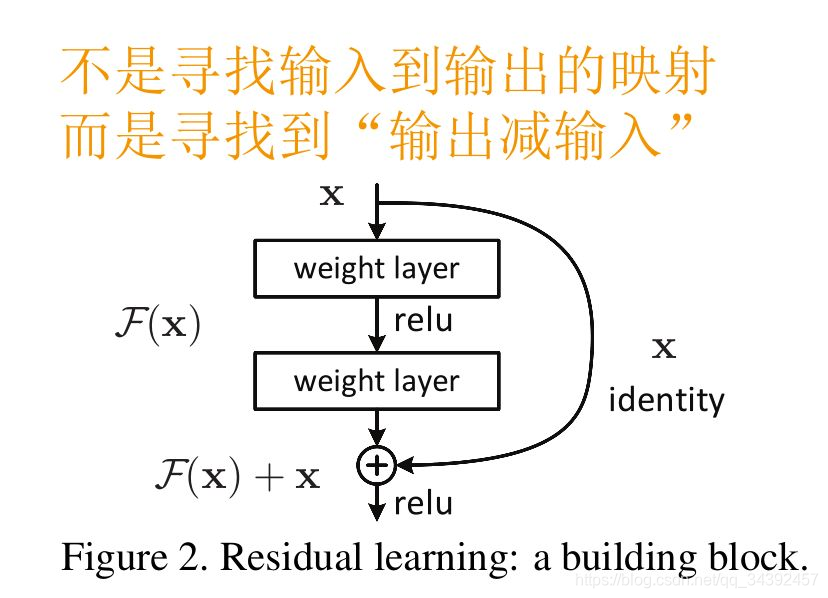
- Resnet的优势:resnet实际上是一个实验性质的网络,试了觉得好才去解释其原理,有以下几种观点:一是加入的shortcut缓解了反向传播时的梯度消失问题(但实际上经过BN梯度消失就已经得到很大缓解了)。二是随着网络层数加深,由于卷积与池化抽样的原因,越后面的层处理的输入中包含的原始图像信息越少,shortcut的加入缓解了信息的衰减。三是ResNet可以看作多个子网络的并行,相当于一个ensemble模型。四是shortcut的加入可以将输入在不同层次的特征(简单特征/复杂特征)上进行区分,而普通网络中每次都是按照最复杂的特征来判断。五是从函数曲面来看,深层网络的损失函数曲线是严重非凸的,shortcut的加入可以使损失函数图像更接近凸函数。
7. 模型融合与模型提升算法
参考:https://blog.csdn.net/weixin_43595430/article/details/105837619
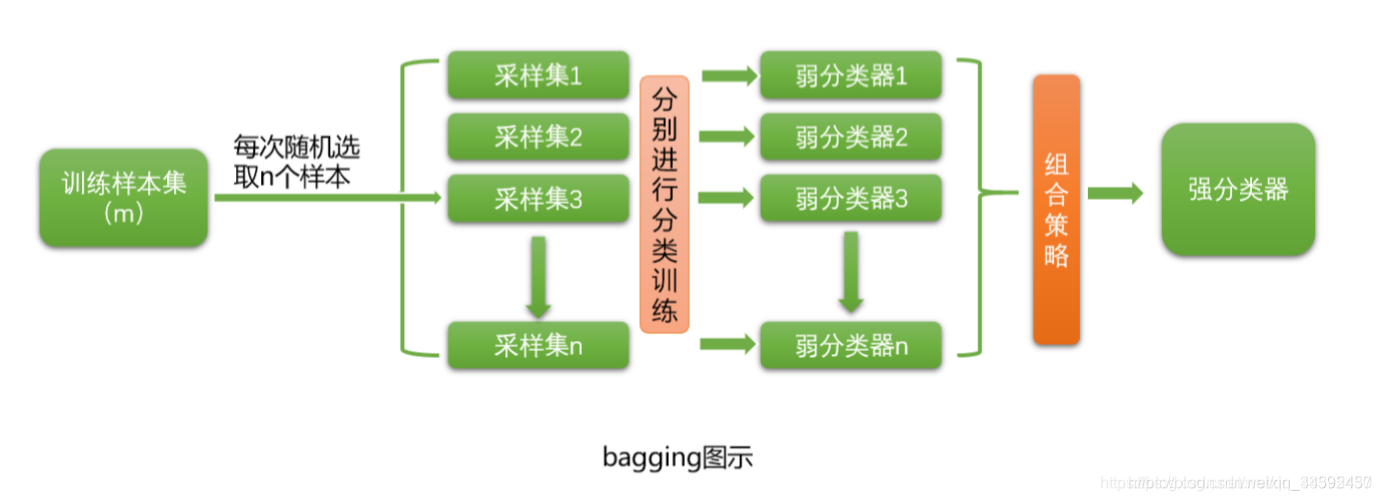
- 随机森林(RandomForest):从原始训练集中采样出n组样本,针对每组样本训练一个决策树模型,最终结果由决策树投票(分类)或取平均产生(回归)。
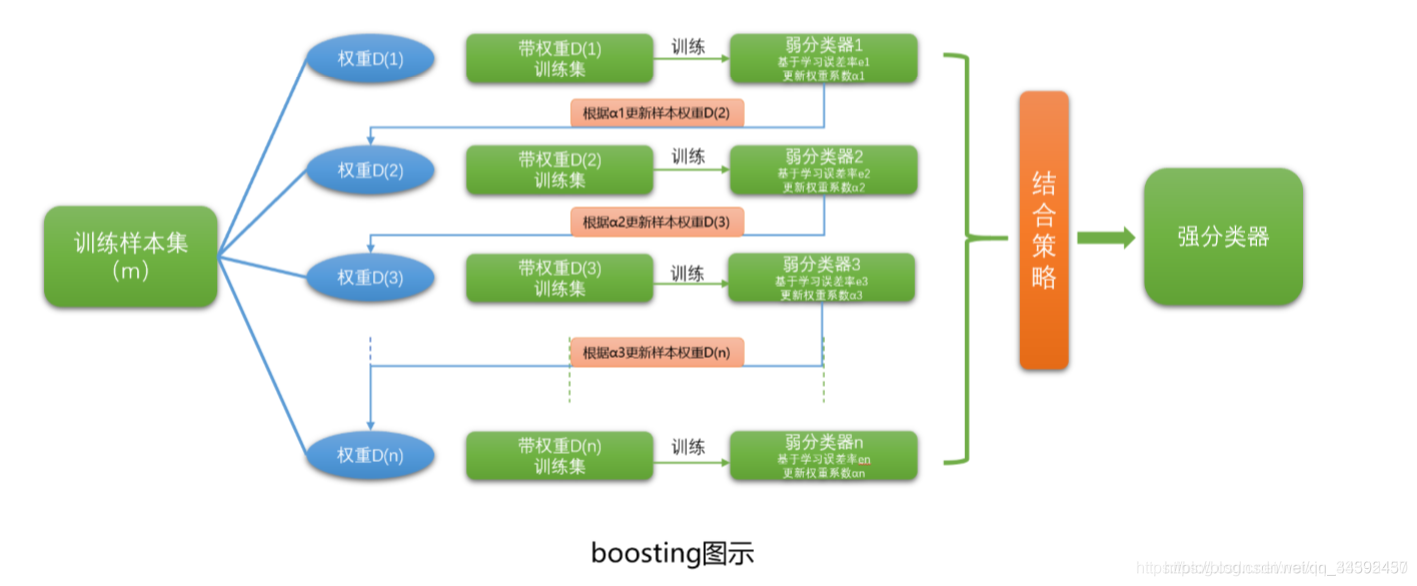
- Adaboost(AdaptiveBoosting):对原始训练集中每一个样本赋予权重 d i d_i di,针对整个数据集训练决策树模型 m k m_k mk,依据分类结果调整训练集中每个样本的权重(使被分错的样本具有更高的权重),使用新的权重(增加样本量来表示权重?)继续迭代训练下一个模型直到准确率为100%或者达到预设定的子模型数量。最终的模型为多个子模型的加权和。
总体来说,bagging类算法是直接在原始数据集中采样得到子数据集并在此上训练子模型,而boosting类算法是迭代地调整原始数据集中数据分布(即样本权值)。
8. 常用的激活函数
-
softmax: S o f t m a x ( x i ) = e x i ∑ i b e x i Softmax(x_i)=\frac{e^{x_i}}{\sum_i^be^{x_i}} Softmax(xi)=∑ibexiexi将输入归一化到(0,1)区间,并且所有数据和为1。
-
sigmoid: S i g m o i d ( x ) = 1 1 + e − x Sigmoid(x)=\frac{1}{1+e^{-x}} Sigmoid(x)=1+e−x1可以把数值转换至(0,1)区间,但是不在网络中加入其他处理的话特别容易产生梯度消失问题。

-
tanh: T a n h ( x ) = e x − e − x e x + e − x Tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} Tanh(x)=ex+e−xex−e−x相比于sigmoid,将中心点设置为0,可以一定程度上加快训练(缓解了 zig-zagging dynamics),但是依旧没有解决梯度消失问题。

-
relu: R e l u ( x ) = m a x ( 0 , x ) Relu(x)=max(0,x) Relu(x)=max(0,x)
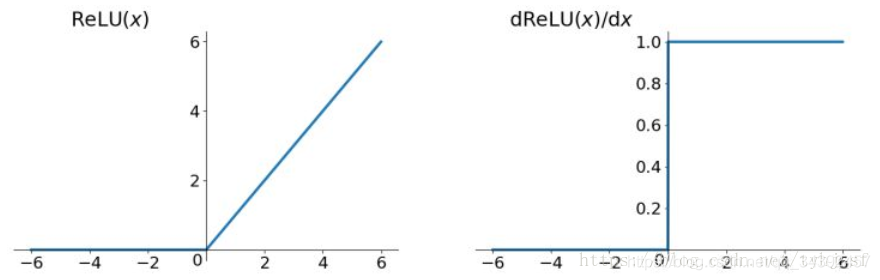
relu函数最大的优点就是解决了梯度消失问题,除此之外计算速度相比前面两种要快很多。不过在x<0时,梯度为0,会有一种Dead ReLU Problem的现象,即此时部分神经元不会再更新,变为死神经元。导致这一问题的主要原因有两个:参数初始化不好(使用Xavier初始化方法可缓解),learning rate太高导致在训练过程中参数更新太大。改进方法一般是使x<0时的输出不再恒等于0,比如LeakyRelu:

9. 常用的loss函数
- 0/1 Loss:是最简单的损失函数(一般不怎么用),当预测与输出相等时输出1,否则为0,一般来说也会放宽条件(预测与输出绝对值差距在T以内)。
- CrossEntropyLoss:是用的最多的损失函数,由KL散度推导而来,下面是一个batch(m)下的loss计算公式,p是标签,q是预测的数据分布: l o s s = − 1 m ∑ i = 1 m ∑ j = 1 n p ( x i j ) l o g ( q ( x i j ) ) loss=-\frac1 m \sum_{i=1}^{m}\sum_{j=1}^{n}p(x_{ij})log(q(x_{ij})) loss=−m1i=1∑mj=1∑np(xij)log(q(xij))
- DiceLoss:是医学图像分割领域有名的损失函数,表示的是两个轮廓区域的相似程度,公式如下:
D
i
c
e
(
A
,
B
)
=
2
∗
A
∩
B
∣
A
∣
+
∣
B
∣
Dice(A,B)=\frac{2*A\cap B}{|A|+|B|}
Dice(A,B)=∣A∣+∣B∣2∗A∩B
此损失函数的优势是一般的损失函数过度关注背景信息,而在医学图像分割领域目标区域可能只占图片的一小部分(前景信息),因此使用一般的损失函数容易使学习过程陷入损失函数的局部最小值,DiceLoss可以加大前景区域的权重。PSDiceLoss是加入了平滑的Diceloss。
10. LSTM结构
三个门,最左边的遗忘门删除(
×
\times
×)不需要的记忆,中间的输入门加入(
+
+
+)需要传递的记忆,最右边的输出门与记忆一起(
×
\times
×)构成当前层的输出:
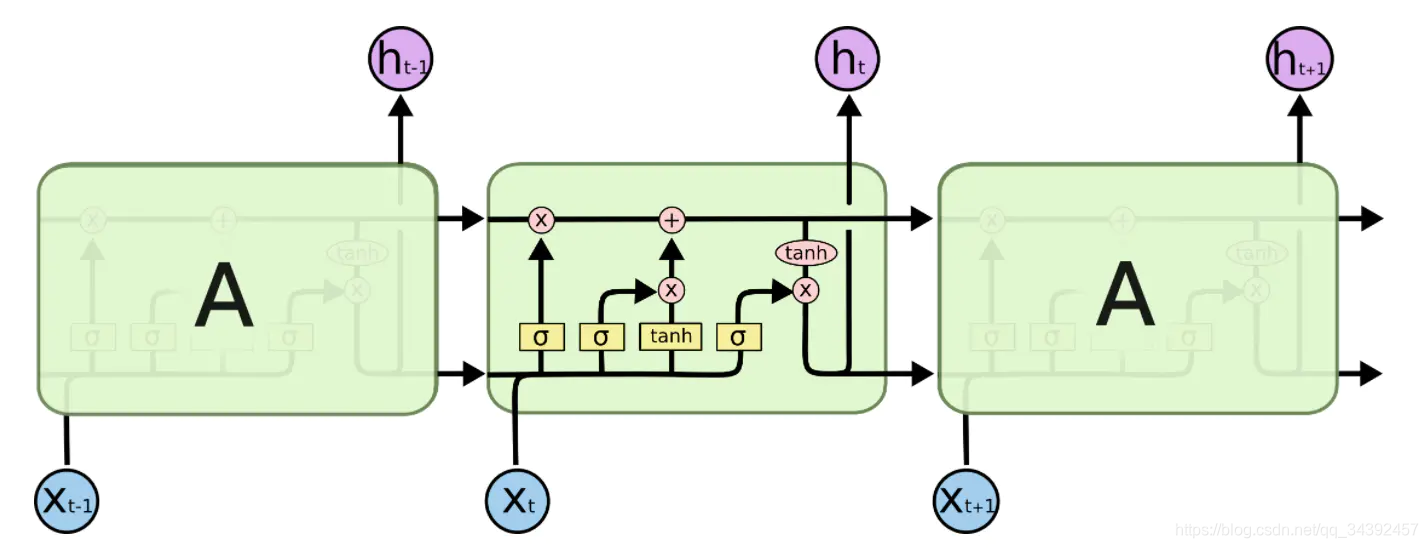
f
t
=
σ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
;
i
t
=
σ
(
W
i
⋅
[
h
t
−
1
,
x
t
]
+
b
i
)
;
o
t
=
σ
(
W
i
⋅
[
h
t
−
1
,
x
t
]
+
b
o
)
f_t=\sigma(W_f\cdot [h_{t-1},x_t]+b_f);i_t=\sigma(W_i\cdot[h_{t-1},x_t]+b_i);o_t=\sigma(W_i\cdot[h_{t-1},x_t]+b_o)
ft=σ(Wf⋅[ht−1,xt]+bf);it=σ(Wi⋅[ht−1,xt]+bi);ot=σ(Wi⋅[ht−1,xt]+bo)
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
t
a
n
h
(
W
c
⋅
[
h
t
−
1
,
x
t
]
+
b
c
)
C_t = f_t*C_{t-1}+i_t*tanh(W_c\cdot[h_{t-1},x_t]+b_c)
Ct=ft∗Ct−1+it∗tanh(Wc⋅[ht−1,xt]+bc)
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
h_t=o_t*tanh(C_t)
ht=ot∗tanh(Ct)
11. Attention机制
下图是在编码解码架构里的attention,注意力机制的核心其实就是注意力的计算,也就是Similarity函数,而此函数的意义是衡量输入之间的关系,因此神经网络中的注意力层虽然形式上也是使用注意力作为权值对输入特征做线性组合,但与全连接层不同的是这个权值是依据输入之间的关系计算出来的,也就是说在此过程中加入了输入之间的关系信息,从而实现了“对齐”的效果(在self-attention中最明显)。
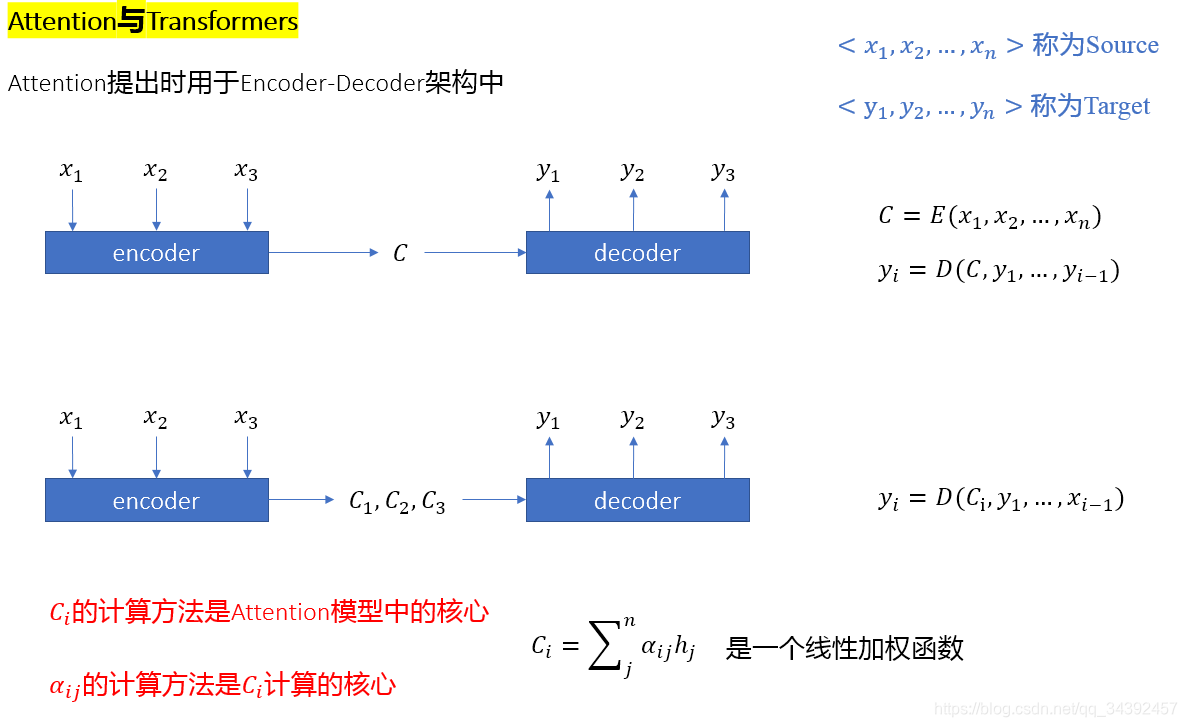
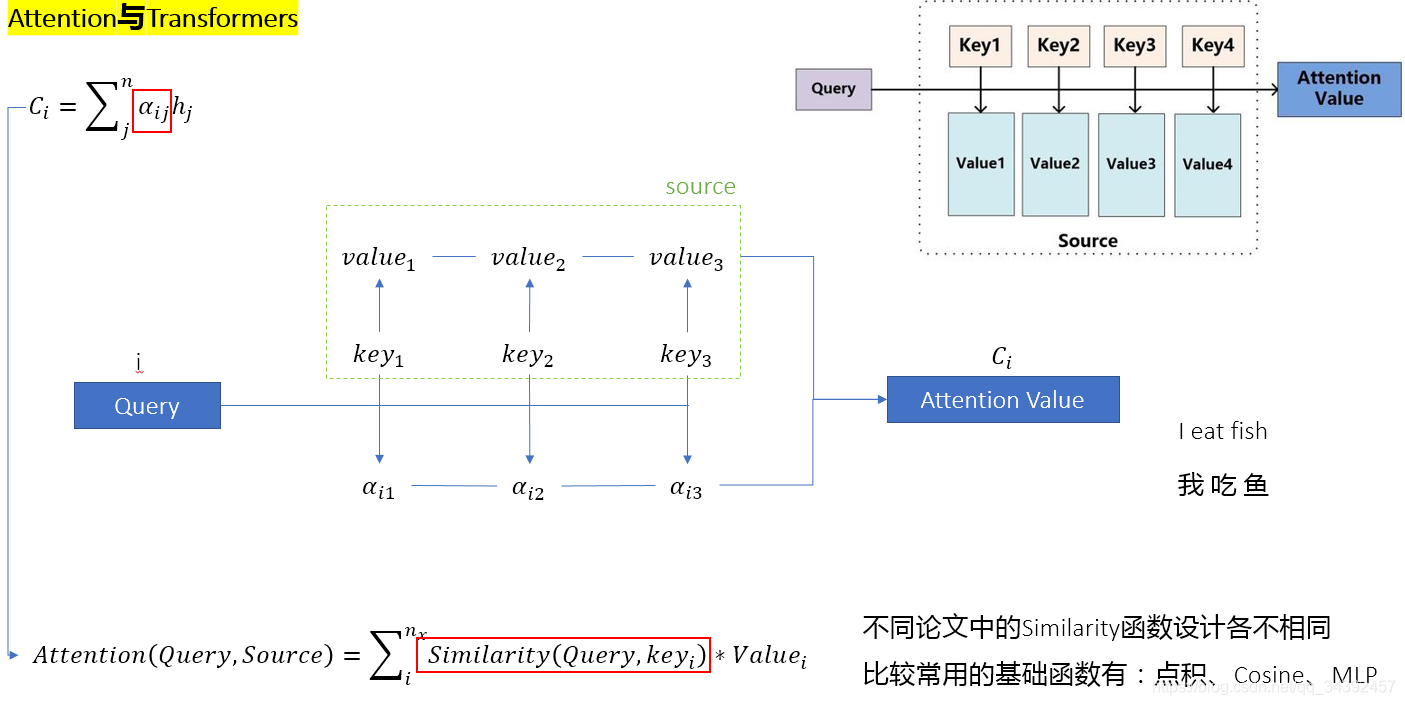
- Transformer:
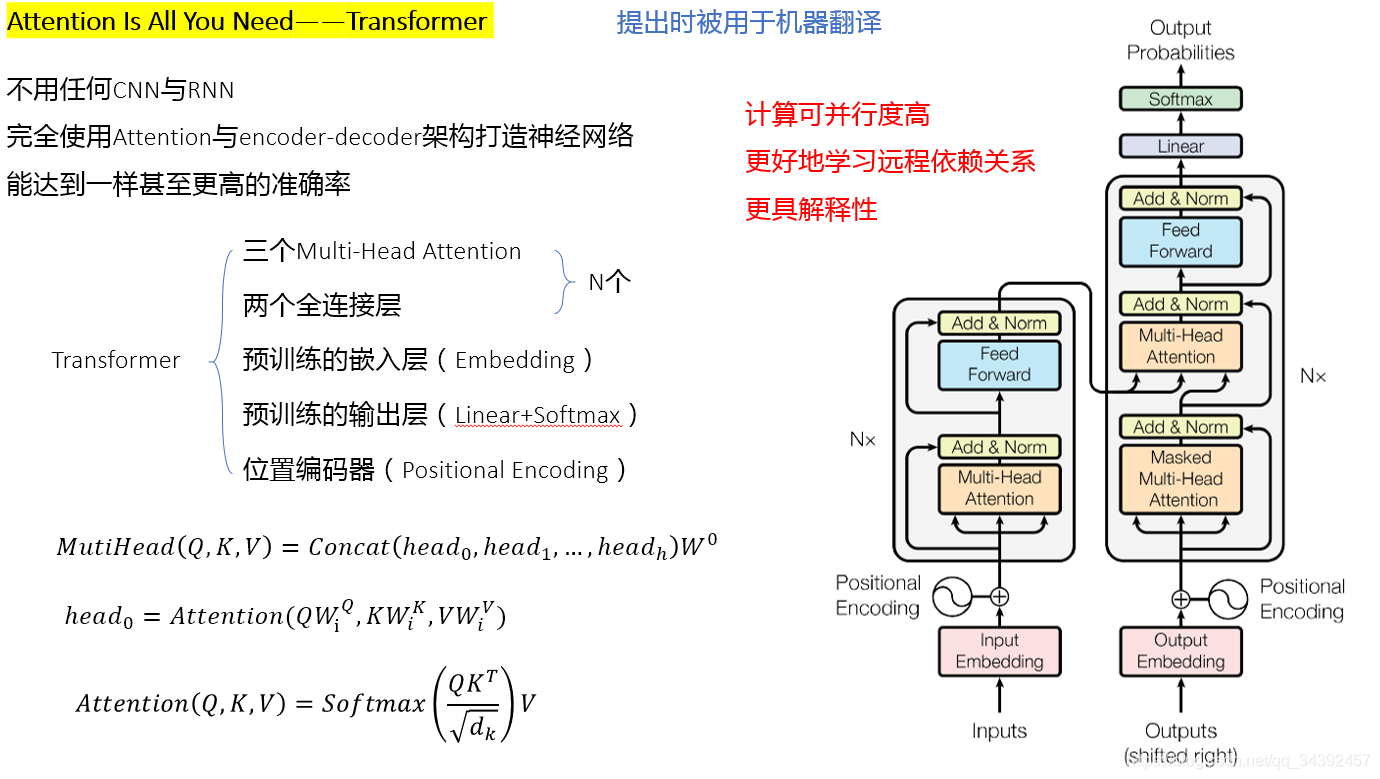
在cv领域比较有名的transformer模型有:DETR(目标检测)、ViT(分类)、SETR(分割)。
10. 什么是dropout
dropout的提出是为了解决过拟合问题,Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
11. NaiveBayes算法
已知特征为
X
=
x
1
,
x
2
,
.
.
.
,
x
m
X={x_1,x_2,...,x_m}
X=x1,x2,...,xm以及类别
y
1
,
y
2
,
.
.
.
,
y
k
{y_1,y_2,...,y_k}
y1,y2,...,yk,有如下公式:
P
(
y
i
∣
X
)
=
P
(
x
1
∣
y
i
)
×
P
(
x
2
∣
y
i
)
.
.
.
×
P
(
x
m
∣
y
i
)
×
P
(
y
i
)
P
(
X
)
P(y_i|X)=\frac{P(x_1|y_i)\times P(x_2|y_i)...\times P(x_m|y_i)\times P(y_i)}{P(X)}
P(yi∣X)=P(X)P(x1∣yi)×P(x2∣yi)...×P(xm∣yi)×P(yi)
在实际计算某个样本类别时,
P
(
X
)
P(X)
P(X)是固定的因此不需要考虑,即只需要对每个类别分别计算分子,看谁最大即可。
12. SVM算法
13. 卷积核是不是越大越好?如何确定卷积核大小
参考1:https://www.jianshu.com/p/bfd7011dd0bb
参考2:https://www.zhihu.com/question/38098038
基本思想就是卷积核越大,感受野(receptive field)越大,看到的图片信息越多,所获得的全局特征越好,其需要的参数也越大。而在相同感受野的情况下,多个小卷积的叠加会比一个大卷积参数少很多,且叠加可以使网络层数更深,捕获更多特征。
14. 卷积操作与池化操作的过程与意义
卷积用于提取特征,并增加通道(可以看做是提取不同层面的特征),而池化是一个采样过程,用于缩减图像尺度。
15. 基于树的模型(比如决策树)和线性模型有哪些区别,为什么需要编码
树模型(比如决策树):
- 产生的是可视化的分类规则,更接近人的决策方式,可解释性强。
- 拟合出来的是分区间的阶梯函数,可在特征空间复杂,无法用线性表达时使用。
- 决策树是对每一个特征进行划分,一般通过计算特征属性的信息增益率来训练,具有比较强的样本区分能力。
- 实验研究表明,在表格类型的数据上,没有任何模型(包括深度学习)能够超过基于决策树的模型。
线性模型(比如逻辑回归):
- 实际是对特征的加权和,理论上拟合出来的函数可以是任意曲线,比树模型精度更高。
- 一般线性模型对整体的全局结构分析or提取优于树模型,树模型容易产生过拟合。
16. dropout和BN的区别,是否可以一起用?
BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
17. 回归常用的平方误差和分类常用的交叉熵有什么区别?为什么这么用?
参考这篇文章:https://zhuanlan.zhihu.com/p/35709485
均方误差 vs 交叉熵损失:https://zhuanlan.zhihu.com/p/84431551
为什么两者分别用于回归和分类:https://blog.csdn.net/weixin_41888969/article/details/89450163
交叉熵的公式是:
L
=
−
1
N
∑
i
b
∑
j
c
q
j
l
o
g
(
p
j
i
)
L=-\frac{1}{N}\sum_i^b\sum_j^cq_jlog(p_j^i)
L=−N1i∑bj∑cqjlog(pji)
均方误差的公式是:
L
=
1
N
∑
i
b
∑
j
c
(
q
j
−
p
j
i
)
L=\frac{1}{N}\sum_i^b\sum_j^{c}(q_j-p_j^i)
L=N1i∑bj∑c(qj−pji)
p
j
i
p_j^i
pji是模型预测的
s
a
m
p
l
e
i
sample\ i
sample i属于
c
l
a
s
s
j
class\ j
class j的概率,
q
q
q是样本真实的类别编码(独热),
q
j
=
1
i
f
i
c
l
a
s
s
=
j
e
l
s
e
0
q_j = 1\ if\ i_{class}=j\ else\ 0
qj=1 if iclass=j else 0。
总的来说,交叉熵实际只关心对正确类别的预测概率,而均方误差会额外关心所有正确、错误预测。
18. 如何防止梯度消失
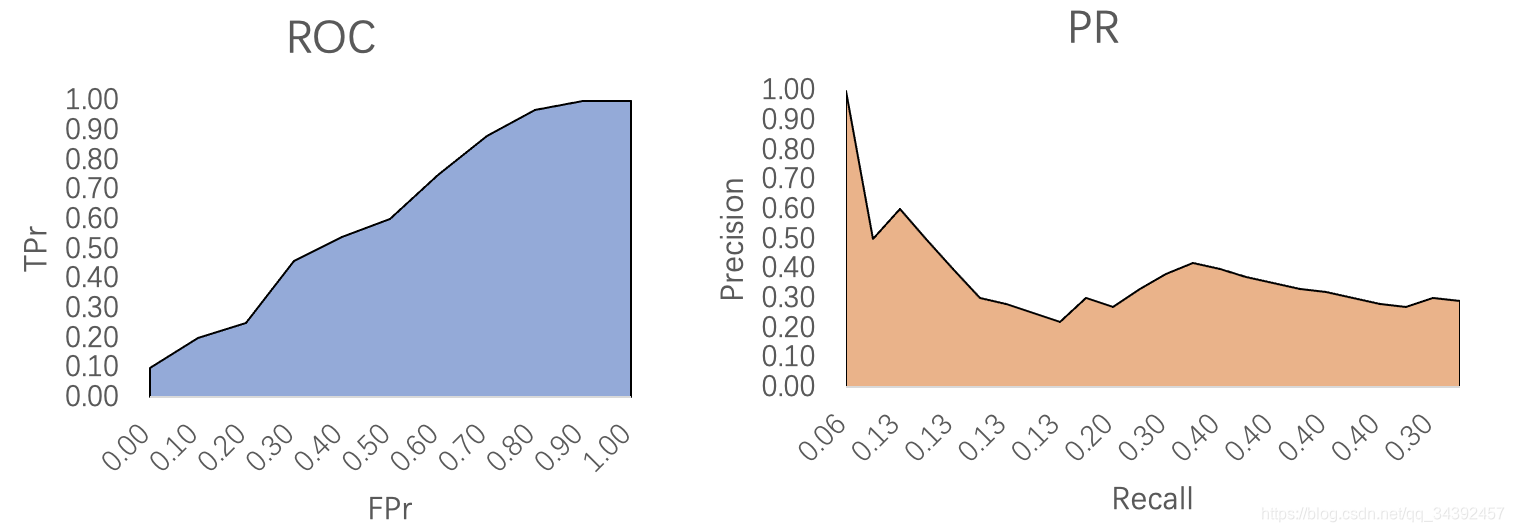
19. ROC、PR、Precision、Recall分别表示什么
FP、TP、FN、TN四个数值,其中后一个字母(P/N)代表的是模型的预测结果为positive还是negative,而前一个字母(F/T)代表的是预测结果是false还是true,
n
u
m
s
a
m
p
l
e
=
f
p
+
t
p
+
f
n
+
t
n
num_{sample}=fp+tp+fn+tn
numsample=fp+tp+fn+tn
有如下公式:
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision=\frac{TP}{TP+FP}
precision=TP+FPTP
r
e
c
a
l
l
=
T
P
T
P
+
F
N
recall=\frac{TP}{TP+FN}
recall=TP+FNTP
ROC是一个曲线,横坐标是FP,纵坐标是TP,曲线与x轴围成的面积为AUC值,通过调整判别阈值来得到此曲线。
PR是一个曲线,横坐标是Recall,纵坐标是Precision,曲线与坐标轴围成的面积为AP值,通过调整预测样本数来得到此曲线。
20. L1、L2是什么
L1、L2都是模型正则化手段,简单来说L1就是在loss上单纯的加参数值,L2就是加参数值的平方。
l
1
:
Ω
(
w
)
=
∣
∣
w
∣
∣
1
=
∑
i
∣
w
i
∣
l_1:\Omega (w)=||w||_1=\sum_i|w_i|
l1:Ω(w)=∣∣w∣∣1=i∑∣wi∣
l
2
:
Ω
(
w
)
=
∣
∣
w
∣
∣
2
=
∑
i
w
i
2
l_2:\Omega(w)=||w||_2=\sum_iw_i^2
l2:Ω(w)=∣∣w∣∣2=i∑wi2
从概率学似然估计的角度来说,L1对应的是假设w为拉普拉斯分布,而L2对应的是假设w为高斯(正态)分布。
21.归一化、标准化、正则化
归一化是让数据变成0-1的范围;标准化是让数据变成均值为0,方差为1;正则化则是对于模型来说防止过拟合。
- 归一化和标准化的英文都是Normalization,需要根据语境判断具体操作。
22. 逻辑回归是否需要归一化/标准化
总而言之需要分是否正则两种情况讨论,需要注意特征的归一化/标准化和BatchNorm不是一个东西。
安全相关问题
1. https流程以及中间人攻击
https实际就是http+ssl/tls,流程如下:
- 客户端发起https请求
- 服务端把自己的信息以证书的形式返回给客户端,比如公钥、网站、颁发机构等
- 客户端验证证书的合法性,若合法则生成随机的对称秘钥,并使用公钥机密,传输给服务器(如果不做证书校验,则会导致中间人攻击)
- 服务器收到后用私钥解密得到对称秘钥(会话秘钥)
https存在中间人攻击:
即攻击者在服务器返回证书时,自己生成一个证书返回给客户端,也就是同时充当服务器与客户端的角色,与服务器和客户端各有一个会话秘钥。
3. SQL注入
sql注入漏洞存在的原因一般是程序没有对sql语句进行检查,比如登录时查询用户名和密码的sql语句是:
SELECT * FROM user WHERE username='admin' AND password='passwd'
那如果用户输入'or 1=1 --,查询语句就变成了:
SELECT * FROM user WHERE username=''or 1=1 -- AND password='passwd'
此时服务器会返回所有的用户名。
防止sql注入的一个方法是:使用预编译,而不是直接使用用户输入的数据进行拼接。
4. 缓冲区溢出
指的是想程序缓冲区写超出长度的内容,导致破坏了程序堆栈,是程序转而执行其它指令。比如使用溢出使程序跳转到某个位置(比如执行一个shell之类的)。
预防措施:检查数据大小再存入缓冲区是一种比较常用的方法,或者使程序的数据段地址空间不可执行。
5. hook原理(frida为例)
6. xss相关知识点
开发问答汇总
1. 线程与进程区别
线程是cpu调度的最小单位,进程是资源分配的最小单位。
2. https流程
1)客户端发起一个http请求,告诉服务器自己支持哪些hash算法。
2)服务端把自己的信息以数字证书的形式返回给客户端(证书内容有密钥公钥,网站地址,证书颁发机构,失效日期等)。证书中有一个公钥来加密信息,私钥由服务器持有。
3)客户端收到服务器的响应后会先验证证书的合法性(证书中包含的地址与正在访问的地址是否一致,证书是否过期)。
4)生成随机密码(RSA签名),如果验证通过,或用户接受了不受信任的证书,浏览器就会生成一个随机的对称密钥(session key)并用公钥加密,让服务端用私钥解密,解密后就用这个对称密钥进行传输了,并且能够说明服务端确实是私钥的持有者。
5)生成对称加密算法,验证完服务端身份后,客户端生成一个对称加密的算法和对应密钥,以公钥加密之后发送给服务端。此时被黑客截获也没用,因为只有服务端的私钥才可以对其进行解密。之后客户端与服务端可以用这个对称加密算法来加密和解密通信内容了。
3. 浏览器打开一个网页的流程
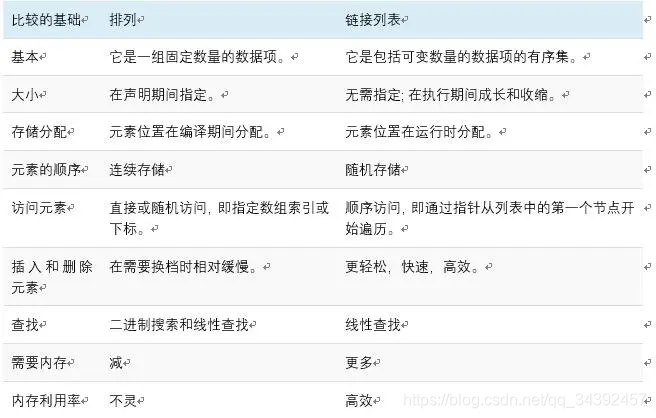
4. 链表与数组的区别与优势
5. python的GIL锁以及如何实现真正的多进程
GIL是一个限制多线程并发的线程互斥锁,为了保证线程安全而存在,所以python中的多线程并不是真正的多线程。
想要充分利用多核优势,需要开启多进程。
6. SQL查询如何不重复
用select distinct name from table命令查询,即加入distinct约束。
7. linux查看端口占用命令
方法1:lsof -i:端口号
方法2:netstat -tunlp | grep 端口号
8. springboot
9. python的垃圾回收机制
总体来说,在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
10. python中生成器和迭代器
生成器实际上是一个函数,每次调用时才进行计算并输出值(用yield)。
迭代器是一个数结构(或者说一个类),在产生时就把全部数据生成出来了,在调用时输出数据。

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









