






 文章讨论了ava_train_v2.2.csv和ava_val_v2.2.csv文件中行为标签的特性,指出每个时间点可能对应多个框,表示同一时间内不同个体的行为。一个框可能对应多个行为,如跳舞、站立和说话。文章强调了在处理时空检测数据集时对行为多样性的理解。
文章讨论了ava_train_v2.2.csv和ava_val_v2.2.csv文件中行为标签的特性,指出每个时间点可能对应多个框,表示同一时间内不同个体的行为。一个框可能对应多个行为,如跳舞、站立和说话。文章强调了在处理时空检测数据集时对行为多样性的理解。

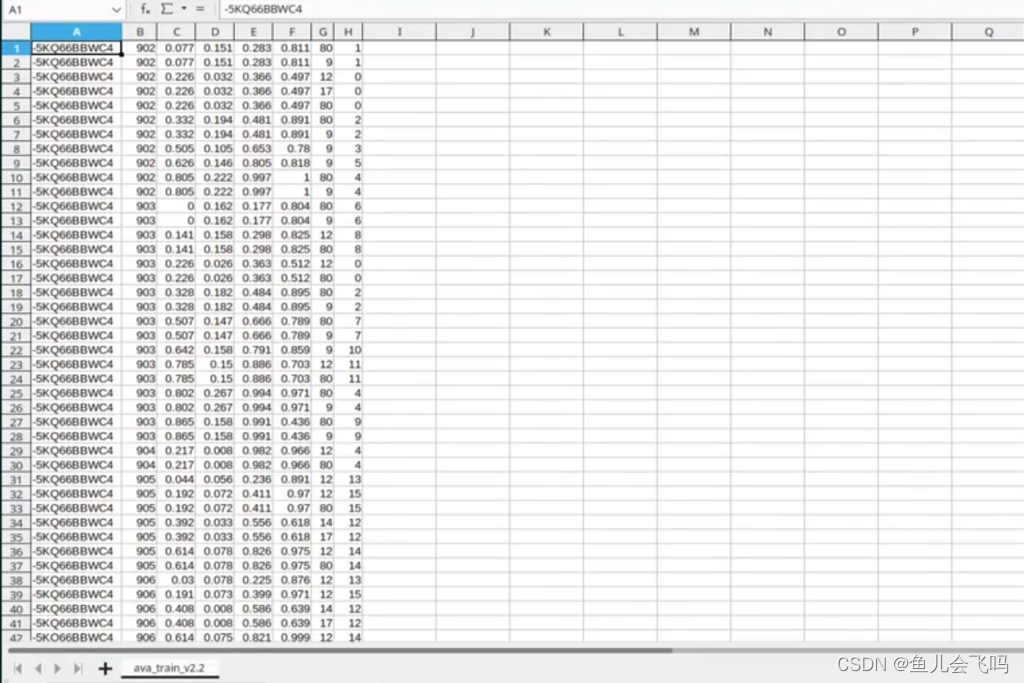
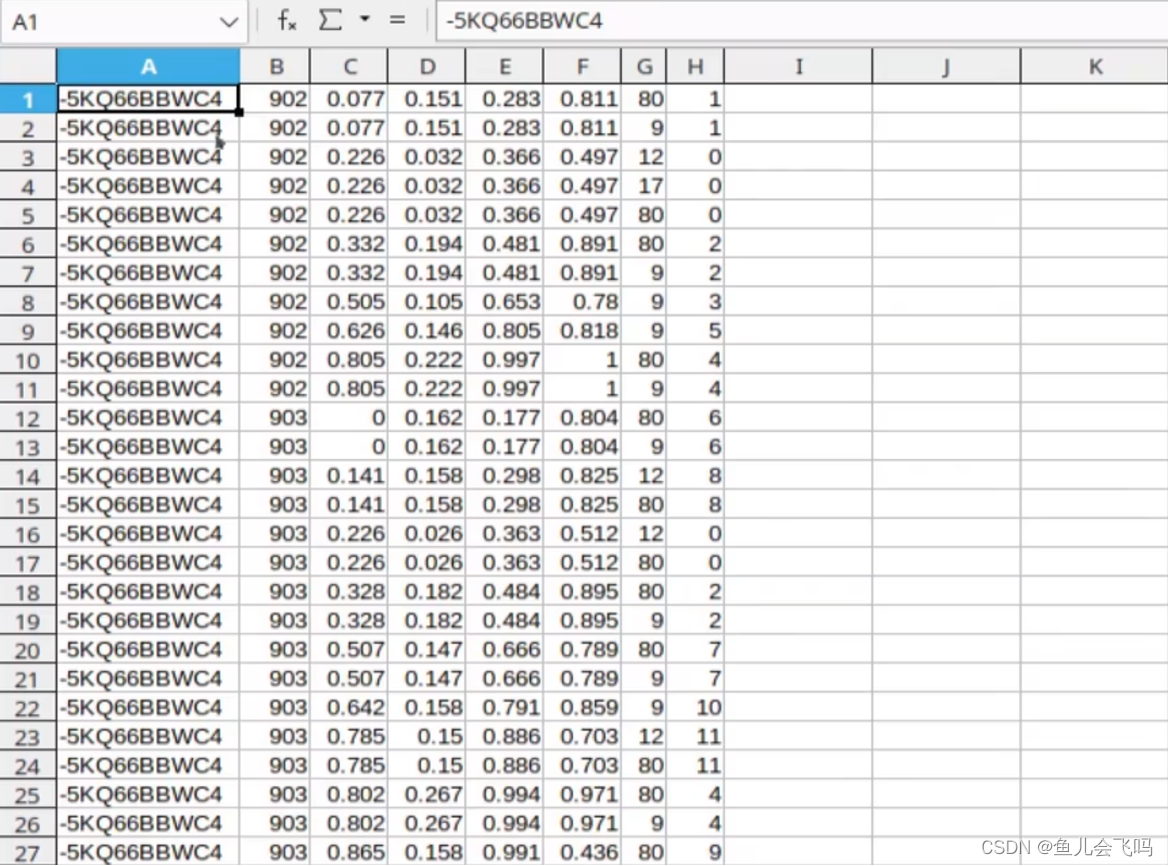
通过看ava_train_v2.2.csv和ava_val_v2.2.csv,每一个字段的含义,发现是按秒为单位来给对应的行为打标签的。
比如第902秒对应的某个人的框对应的某个行为是什么?
比如第903秒对应的某个人的框对应的某个行为是什么?
...
大家可能会有疑问,怎么902当中,这1秒,怎么有这么多框,不就1个人怎么多个框?
答:是这样的,在这1秒当中,可能是多个人,每个人都有一个框,所以说这一块这个框是有多个的。
并且比如说有1个人,有1个人是不是一个框呢,其实也不是
因为一个人,我们说一个框对应着一个标签,但这个人有可能既是在跳舞,又是在站着,又是在说话。

参考:















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









