






一、准备工作
首先找一下init_dist的官方文档
from mmcv.runner import get_dist_info, init_dist, set_random_seed
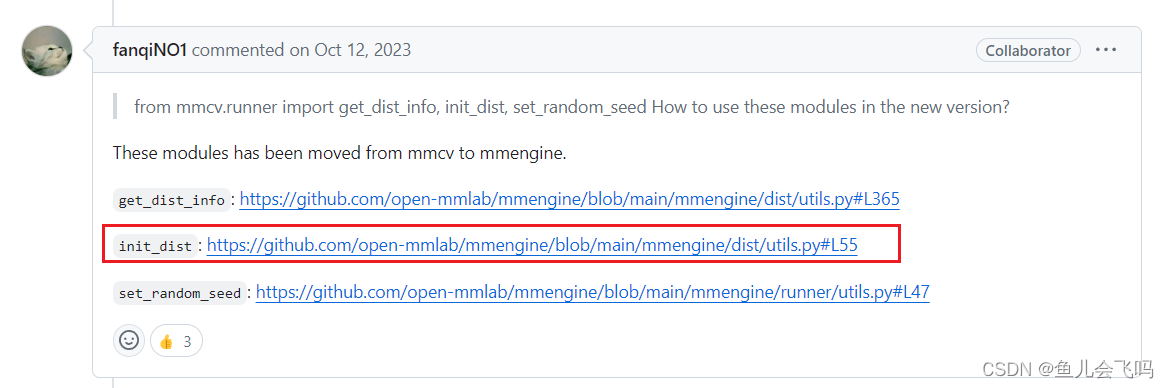
mmengine/mmengine/dist/utils.py at main · open-mmlab/mmengine · GitHub
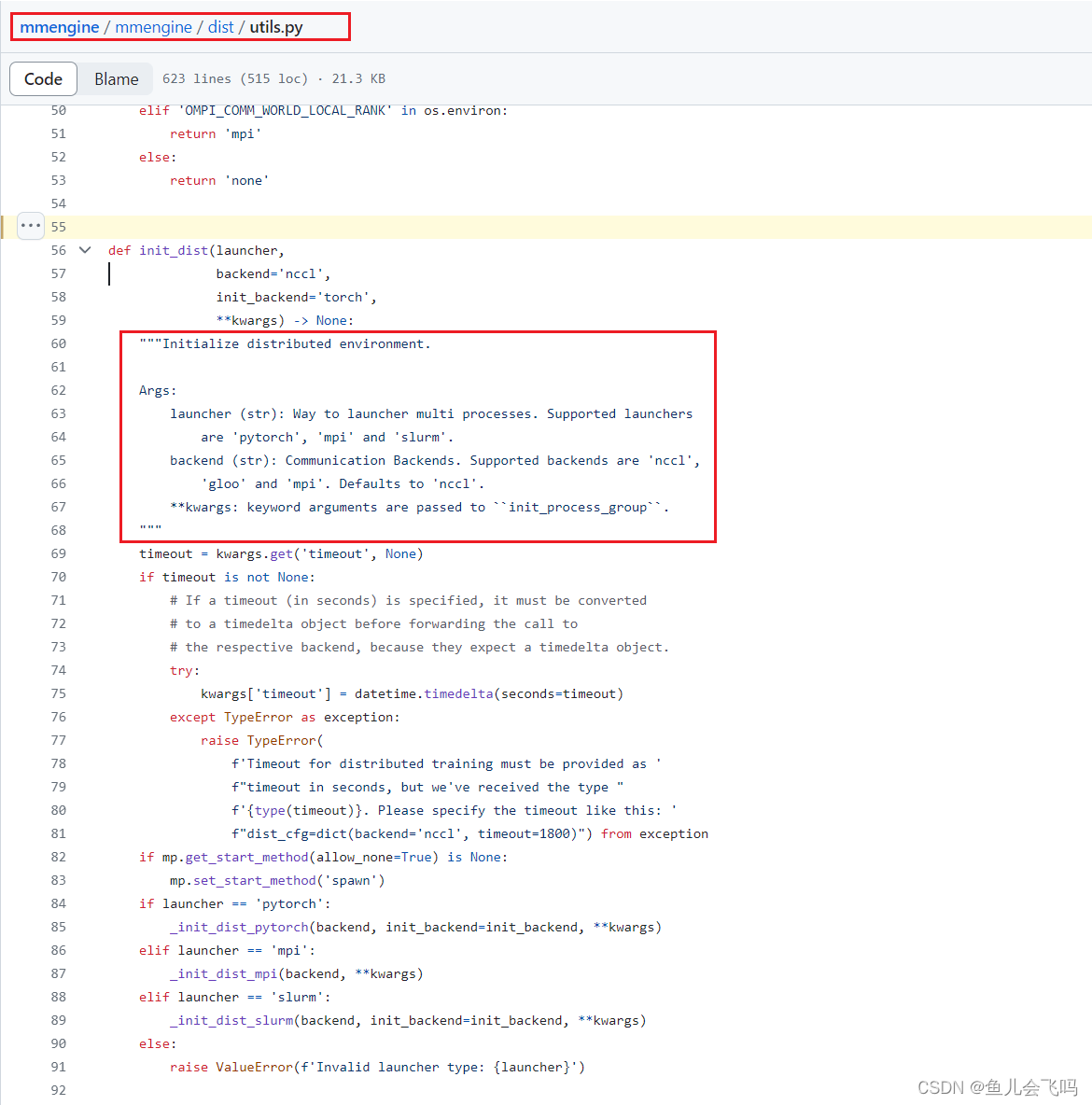
def init_dist(launcher,
backend='nccl',
init_backend='torch',
**kwargs) -> None:
"""Initialize distributed environment.
Args:
launcher (str): Way to launcher multi processes. Supported launchers
are 'pytorch', 'mpi' and 'slurm'.
backend (str): Communication Backends. Supported backends are 'nccl',
'gloo' and 'mpi'. Defaults to 'nccl'.
**kwargs: keyword arguments are passed to ``init_process_group``.
"""def init_dist(launcher,
backend='nccl',
init_backend='torch',
**kwargs) -> None:
"""初始化分布式环境。
参数:
launcher (str): 启动多进程的方式。支持的启动器有 'pytorch'、'mpi' 和 'slurm'。
backend (str): 通信后端。支持的后端有 'nccl'、'gloo' 和 'mpi'。默认为 'nccl'。
**kwargs: 关键字参数会传递给 ``init_process_group``。
"""这段代码定义了一个名为 init_dist 的函数,用于初始化分布式环境。函数接受以下参数:
launcher:启动多进程的方式,可以是 'pytorch'、'mpi' 或 'slurm'。backend:通信后端,可以是 'nccl'、'gloo' 或 'mpi',默认为 'nccl'。**kwargs:额外的关键字参数会传递给init_process_group。
该函数的作用是根据参数初始化分布式环境,设置分布式训练所需的通信后端和其他相关配置。具体的实现和使用方式可能会因具体的代码框架或项目而有所不同。
需要注意的是,该代码段的注释是中文的,提供了对函数功能和参数的简要说明。
timeout = kwargs.get('timeout', None)
if timeout is not None:
# If a timeout (in seconds) is specified, it must be converted
# to a timedelta object before forwarding the call to
# the respective backend, because they expect a timedelta object.
try:
kwargs['timeout'] = datetime.timedelta(seconds=timeout)
except TypeError as exception:
raise TypeError(
f'Timeout for distributed training must be provided as '
f"timeout in seconds, but we've received the type "
f'{type(timeout)}. Please specify the timeout like this: '
f"dist_cfg=dict(backend='nccl', timeout=1800)") from exception
if mp.get_start_method(allow_none=True) is None:
mp.set_start_method('spawn')
if launcher == 'pytorch':
_init_dist_pytorch(backend, init_backend=init_backend, **kwargs)
elif launcher == 'mpi':
_init_dist_mpi(backend, **kwargs)
elif launcher == 'slurm':
_init_dist_slurm(backend, init_backend=init_backend, **kwargs)
else:
raise ValueError(f'Invalid launcher type: {launcher}')timeout = kwargs.get('timeout', None)
if timeout is not None:
# 如果指定了超时时间(以秒为单位),在转发调用到各个后端之前,必须将其转换为 timedelta 对象,
# 因为后端期望一个 timedelta 对象。
try:
kwargs['timeout'] = datetime.timedelta(seconds=timeout)
except TypeError as exception:
raise TypeError(
f'分布式训练的超时时间必须以秒为单位提供,但我们收到的是类型 '
f'{type(timeout)}。请像这样指定超时时间:'
f"dist_cfg=dict(backend='nccl', timeout=1800)") from exception
if mp.get_start_method(allow_none=True) is None:
mp.set_start_method('spawn')
if launcher == 'pytorch':
_init_dist_pytorch(backend, init_backend=init_backend, **kwargs)
elif launcher == 'mpi':
_init_dist_mpi(backend, **kwargs)
elif launcher == 'slurm':
_init_dist_slurm(backend, init_backend=init_backend, **kwargs)
else:
raise ValueError(f'无效的启动器类型:{launcher}')这段代码根据给定的启动器类型 launcher,以及其他相关参数,初始化分布式环境。具体解释如下:
-
timeout = kwargs.get('timeout', None): 从关键字参数kwargs中获取timeout参数的值,如果不存在则设为None。 -
if timeout is not None:: 如果timeout不为None,则执行下面的代码块。-
try: kwargs['timeout'] = datetime.timedelta(seconds=timeout): 将timeout转换为datetime.timedelta对象,以便传递给后端模块,因为后端期望接收一个timedelta对象作为超时时间。 -
except TypeError as exception: ...: 如果转换失败,抛出TypeError异常,并提供相应的错误信息,提示正确指定超时时间。
-
-
if mp.get_start_method(allow_none=True) is None: mp.set_start_method('spawn'): 检查当前的多进程启动方法,如果尚未设置,则使用'spawn'方法进行设置。这是为了确保在启动多进程之前设置正确的启动方法,以便在某些平台上实现更好的兼容性。 -
if launcher == 'pytorch': _init_dist_pytorch(backend, init_backend=init_backend, **kwargs): 如果启动器类型是'pytorch',则调用_init_dist_pytorch函数来初始化 PyTorch 分布式环境。 -
elif launcher == 'mpi': _init_dist_mpi(backend, **kwargs): 如果启动器类型是'mpi',则调用_init_dist_mpi函数来初始化 MPI 分布式环境。 -
elif launcher == 'slurm': _init_dist_slurm(backend, init_backend=init_backend, **kwargs): 如果启动器类型是'slurm',则调用_init_dist_slurm函数来初始化 Slurm 分布式环境。 -
else: raise ValueError(f'无效的启动器类型:{launcher}'): 如果启动器类型不是上述三种类型之一,则抛出ValueError异常,提示无效的启动器类型。
这段代码是根据具体的启动器类型调用相应的初始化函数,以适配不同的分布式训练环境。同时,它还处理了超时时间的转换,并确保正确的多进程启动方法的设置。
二、进入正题
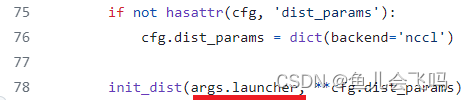
if not hasattr(cfg, 'dist_params'):
cfg.dist_params = dict(backend='nccl')
init_dist(args.launcher, **cfg.dist_params)首先第一个参数args.launcher
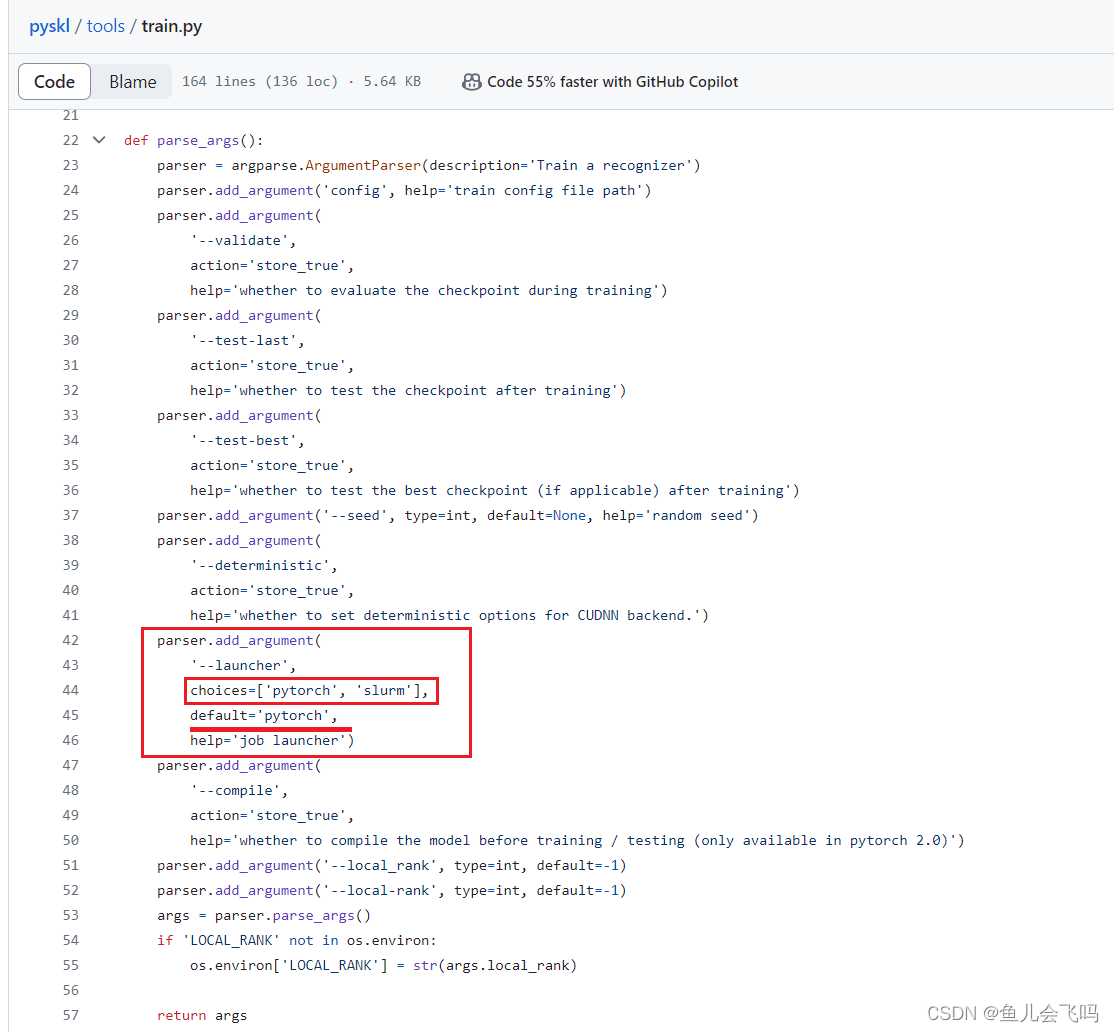
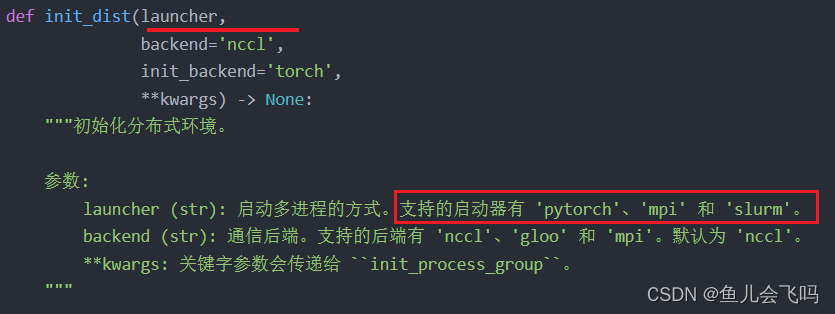
第一个参数发现和官方文档对应上了,默认启动器是pytorch
接下来看第二个参数**cfg.dist_params
if not hasattr(cfg, 'dist_params'):
cfg.dist_params = dict(backend='nccl')
这段代码是一个条件语句,用于检查cfg对象中是否存在名为dist_params的属性。下面是对代码的逐行解释:
-
if not hasattr(cfg, 'dist_params'):
这行代码使用hasattr()函数检查cfg对象是否具有名为dist_params的属性。hasattr()函数接受两个参数,第一个参数是要检查的对象,第二个参数是要检查的属性名。如果cfg对象中不存在名为dist_params的属性,条件表达式返回True,表示不存在该属性。 -
cfg.dist_params = dict(backend='nccl')
如果条件表达式返回True,即cfg对象中不存在dist_params属性,那么这行代码会执行。它为cfg对象添加一个名为dist_params的属性,并将其值设置为一个字典{'backend': 'nccl'}。
因此,如果cfg对象中没有dist_params属性,代码会将其添加为一个字典类型的属性,并设置初始值为{'backend': 'nccl'}。
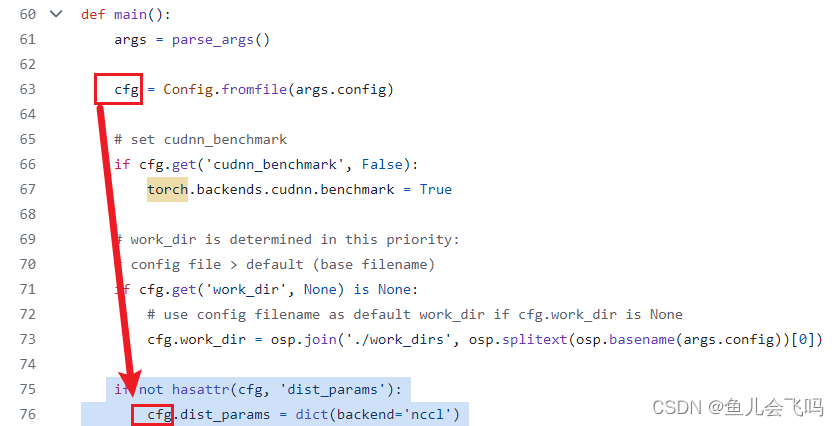
检查了一下配置文件发现没有dist_params属性,于是条件表达式返回True,那么这行代码会执行。它为cfg对象添加一个名为dist_params的属性,并将其值设置为一个字典{'backend': 'nccl'}。
backend='nccl'表示将使用NCCL作为分布式训练的后端。
在深度学习中,分布式训练是指在多个计算设备(例如多台计算机或多个GPU)上同时进行训练任务,以加快训练速度和增加可扩展性。NCCL(NVIDIA Collective Communications Library)是NVIDIA提供的用于高性能GPU集群通信的库。它专门针对NVIDIA GPU进行了优化,可以实现高效的数据传输和通信操作,使得多个GPU之间的数据传输和同步更快速和高效。
在这段代码中,backend='nccl'指定了使用NCCL作为分布式训练的后端。这意味着在进行分布式训练时,将使用NCCL库来处理多个GPU之间的通信和数据传输操作,以提高训练效率和性能。
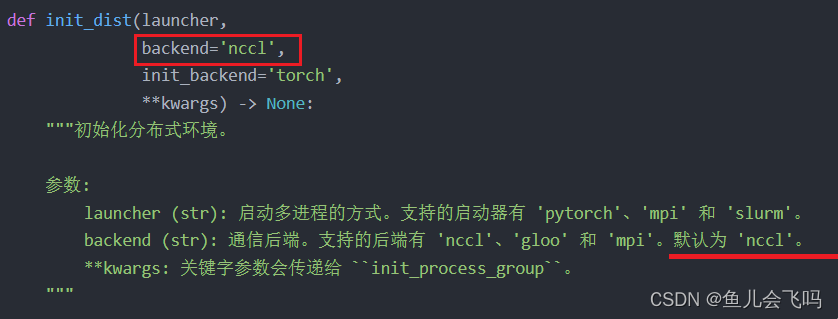
第二个参数发现和官方文档对应上了。
三、总结
init_dist(args.launcher, **cfg.dist_params) 是一个函数调用语句,它调用名为 init_dist 的函数,并传递了两个参数:args.launcher 和 **cfg.dist_params。
根据函数调用的上下文,可以推测 init_dist 函数用于初始化分布式训练环境。下面对函数调用中的参数进行解释:
-
args.launcher是一个参数,它的值是通过命令行传递进来的--launcher参数的值。它指定了作业启动器的类型,即指定了分布式训练的后端或启动方式。 -
**cfg.dist_params表示将cfg.dist_params字典中的键值对作为关键字参数传递给函数。cfg.dist_params是一个字典对象,其中包含了初始化分布式训练所需的参数信息。通过使用**符号,字典中的每个键值对会被拆解为关键字参数的形式。
综上所述,这段代码的含义是调用 init_dist 函数来初始化分布式训练环境。函数接受两个参数:args.launcher 用于指定作业启动器的类型,以及 cfg.dist_params 字典中的其他参数作为关键字参数传递给函数。这样可以根据指定的作业启动器类型和其他参数信息,正确地初始化分布式训练环境。具体的初始化逻辑和参数解析应当在 init_dist 函数内部进行。
参考:
mmengine/mmengine/dist/utils.py at main · open-mmlab/mmengine · GitHub















 8130
8130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









