







笔者来聊聊指令集的理解
ARM学习(6) 指令集学习
1、问题由来
-
笔者是一名嵌入式开发者,经常会碰到一些板子运行的程序,不按我们写的逻辑来运行,首先肯定是怀疑我们写的逻辑不对,这当然没问题,但是如果是我们写的逻辑确实是对的,但是它就是不按我们的逻辑运行,那又该怎么办呢?还有什么根本的分析方法吗?
-
那就是要分析汇编语言了,为啥要分析汇编语言呢?
-
因为高级语言最终还是转化成汇编语言,然后进一步转成成二进制运行,我们知道,要分析问题就要到源头分析,越接近源头分析,越能清楚的了解问题的真像,所以C语言写的逻辑代码说到底还是高级语言,不是最终板子运行的形态,所以说还得是分析最终的运行形态,才能知道问题,汇编语言其实与二进制差不多,只是多了助记符以及伪指令而已,所以一般分析汇编语言就可以了。
4.分析汇编语言就得知道指令集了,
比如这个问题,笔者调用了禁止中断好打开中断,发现中断一直没打开?查阅了相关资料,确实是这样写的,但就是有这个问题,“”“玄学问题”
u32 disable_interrupt_and_save()
{
u32 save_status;
asm("mrs %0, DAIF" : "r"(save_status));
asm("msr DAIFSet, #0x0F");
return save_status;
}
void restore_interrupt(u32 save_status)
{
asm("msr DAIF, %0" :: "r"(save_status));
}
还有一些很奇怪的问题,模拟器上面计算的CRC都一样,但是一到板子上面计算CRC就错误,数据都一样,就是算出来不一样。
还比如多核下面,程序前后执行顺序反了,真的会出现failed,的情况,
/* core1 运行*/
u32 a=0;
u32 b=0;
void data_add()
{
a++;
b++;
}
/* core 2 运行*/
void data_get()
{
u32 temp_a = a;
u32 temp_b = b;
if(b > a)
{
assert("Test failed,a %p,b %p\r\n",temp_a,temp_b);
}
}

2、简单介绍
所以接着我们来介绍指令集,首先来回到几个问题,介绍一下有哪些内容
- 为什么要学习指令集?
- 指令集和架构有什么区别?比如ARMv7,和Cortex-M3/4,哪个是指令集,哪个是架构呢,
- 指令集有哪些分类,主要了解的有哪些?
2.1、学习指令集可以有如下这些好处:
- 帮助理解、分析和开发嵌入式底层启动异常等代码
- 提高编写代码效率和性能
- 深入理解计算机底层运行原理
明显ARMv7是指令集,Cortex-M3/4是架构,
2.2、那指令集和架构有什么区别呢?
我们来看两张图,第一张图是ARM架构的发展,第二张图是Cortex-M3的架构手册目录。
-
从以下的图我们可以这样说,一般架构里面包含指令集,比如Cortex-M3架构使用的是armv7的指令集,会专门有一章节来介绍这个,然后,每个指令集版本下面有会多个架构使用这个指令集,比如第一张图,
-
架构往往包括的方面更多,比如存储器系统、指令集异常、中断系统、MPU、调试组件架构以及编程模型等,不仅仅是指令集,而指令集主要就是规定了,有哪些指令集可以使用,比如加载指令,分支跳转指令,以及指令的使用方法,指令的位数等
-
总之来说,两者都是在纵向发展,架构作为一种软件IP,采用了某一种指令集,二指令集又贯穿于多个架构之中。


2.3、指令集有哪些分类呢?
- 加载存储指令
- 分支跳转指令
- 数据处理指令(逻辑运算)
- 协处理器指令
- 浮点运算指令
- ……(特权指令、异常产生指令以及混杂指令)
3、指令集介绍
笔者主要来介绍一下加载存储指令以及分支跳转指令,这两种指令比较常见,相对比较有用,问题也往往出现在在这些指令当中。
3.1、加载存储指令
3.1.1、 常见的存储指令

多字节的存储加载指令

用法主要是如下:
用法
1、LDR R3, [R4] ; 将存储器地址为 R4 的字数据读入寄存器 R3
2、LDR R3, [R1, #8] ; 将存储地址为 R1+8 的字数据读入寄存器 R3
3、LDR R3, [R1, R2] ; 将存储器地址为 R1+R2 的字数据读入寄存器 R3
4、LDR R3, [R1, #8]! ; 将存储器地址为 R1+8 的字数据读入寄存器 R3,并将新地址 R1+8 写入 R1
5、STR R3, [R4] ; 将寄存器 R3写入存储器地址为 R4的地址处
6、STR R3, [R4,#8] ;寄存器 R3写入存储器地址为 R4+8的地址 处
7、STR R3, [R4,R2] ;寄存器 R3写入存储器地址为 R4+R2的地址 处
8、STR R3, [R4,#8]! ;寄存器 R3写入存储器地址为 R4+8的地址 处,并将新地址写入R4,即R4+=8
来举例子进行说明

ldrh r6,[r4]
strd r6,r4,[r13]
adr r3,0x80087BC
movs r2,#0xC
movs r1,#0x2
movw r0,$0x141,
b1 0x800AAAC
ldm r4,{r0-r2,r5}
来,简单看一下上面的几条指令,r4是rx_buf的地址,那么下面下面那条C语言语句翻译成汇编指令就是加载rx buf的前两个字节 组成一个half word(ldrh),然后放到temp_value里面,也就是放到了r6里面。
uint16_t temp_value = (*(uint16_t*)rx_buf);
ldrh r6,[r4]
接着看起来是要打印temp_value 以及rx_buf的地址,由于打印函数的参数较多,所以这两个参数只能存在栈里面,这个主要是AAPCS(Procedure Call Standard for the ARM Architecture)决定的。
strd r6,r4,[r13]
然后就是参数传递,函数调用了,也是函数调用准则里面决定的,r0-r3用来传递参数,后续的放到栈中。

ldr r1,0x80088D0
ldrh r1,[r1,#0x2]
muls r0,r1,r0
mov r1,#-0x1FFF2000
str r0,[r1,#0x14]
- 这上面的几条语句,其实执行了一行C代码,SysTick->LOAD=(u32)time_ms*fac_ms;
- time_ms是参数,所以r0就是这个参数,然后r1就是把fac_ms的值加载进来,
- 然后就是相乘返回到r0里面,
- 最后要把算出来的值,存储到SysTick->LOAD这个寄存器里面,所以需要找到这个地址,然后存储,就是后面的两条指令,
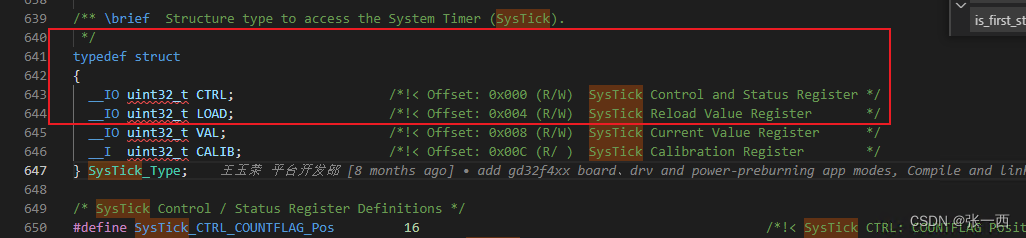
- 这里面可能疑问为什么地址是“-”的呢,这里其实用了补码的形式,所以地址E000E000,然后SysTick->Load的地址需要寻址,根据下面的来看,SysTick_BASE的地址偏移是0x10,然后load相对偏移是4,所以综合下来就是0x14
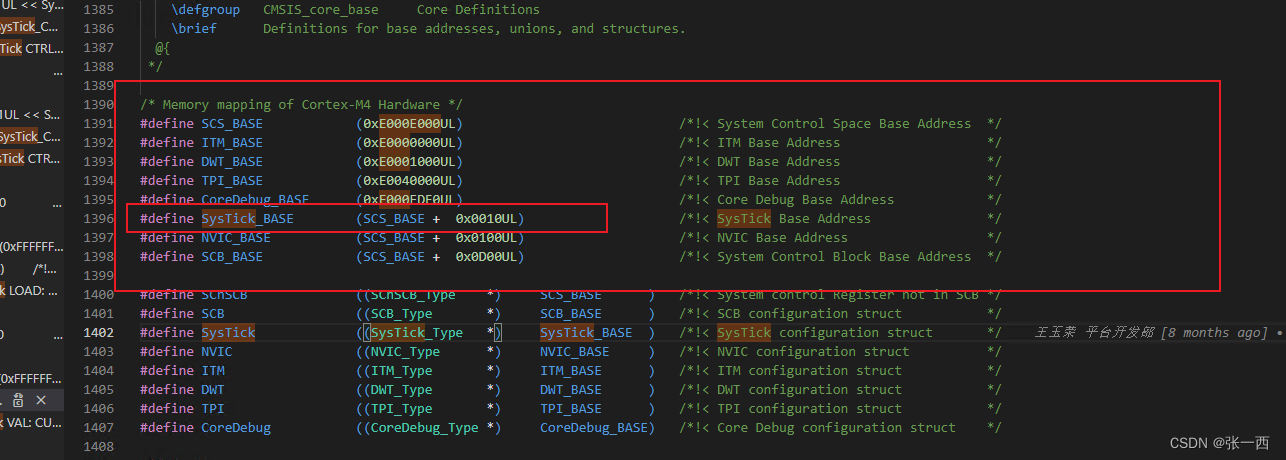

- 接着来看看这个多字节加载指令,r0就是结构体的地址,然后加载到结构体变量里面,恰好是16个字节,所以用r0-r3,这个用先后顺序,先r0后r3,
- 然后把这些数据放到栈里面,r12=r13+4,所以是放到栈的某个位置处。
ldm r0,{r0-r3}
stm r12,{r0-r3}
3.1.2、屏障指令
-
DMB(Data Memory Barrier):数据内存屏障,指令将保证程序前面的数据存储操作都完成后,才会执行后面的加载操作。
-
DSB(Data Synchronization Barrier):数据同步屏障,保证前面所有指令都完成。
-
ISB(Instruction Synchronization Barrier):指令同步屏障,,确保前面的读写操作已经完成,且清空流水线
指令操作耗时比较:DMB < DSB < ISB
- 编译屏障:保证编译前后指令顺序不会跌倒(优化情况下)。
例如:下面的程序就是编译屏障指令,保证这些数据写到寄存器之后,然后再进行while(1)动作,

来介绍一个编译屏障的问题
来介绍一个屏障指令的问题,就开始提到的这个问题,
/* core1 运行*/
u32 a=0;
u32 b=0;
void data_add()
{
a++;
b++;
}
/* core 2 运行*/
void data_get()
{
u32 temp_a = a;
u32 temp_b = b;
if(b > a)
{
assert("Test failed,a %p,b %p\r\n",temp_a,temp_b);
}
}
- 上述代码在多core当中确实会运行到assert的代码,因为多core的乱序执行,有时会执行b++,然后执行a++,然后会导致assert。
- 所以需要加屏障指令,读写都需要增加屏障指令,如下面代码所示。
u32 a=0;
u32 b=0;
void data_add()
{
a++;
__DMB();
b++;
}
/* core 2 运行*/
void data_get()
{
u32 temp_a = a;
__DMB();
u32 temp_b = b;
if(b > a)
{
assert("Test failed,a %p,b %p\r\n",temp_a,temp_b);
}
}
下面的文档中也有介绍,

如果不加屏障指令,那么P2加载到的R5 就可能不是P1保存的R5。
P1
STR R5,[R1]
DMB [ST]
STR R0,[R2]
P2
WAIT ([R2]==1)
DMB
LDR R5,[R1]
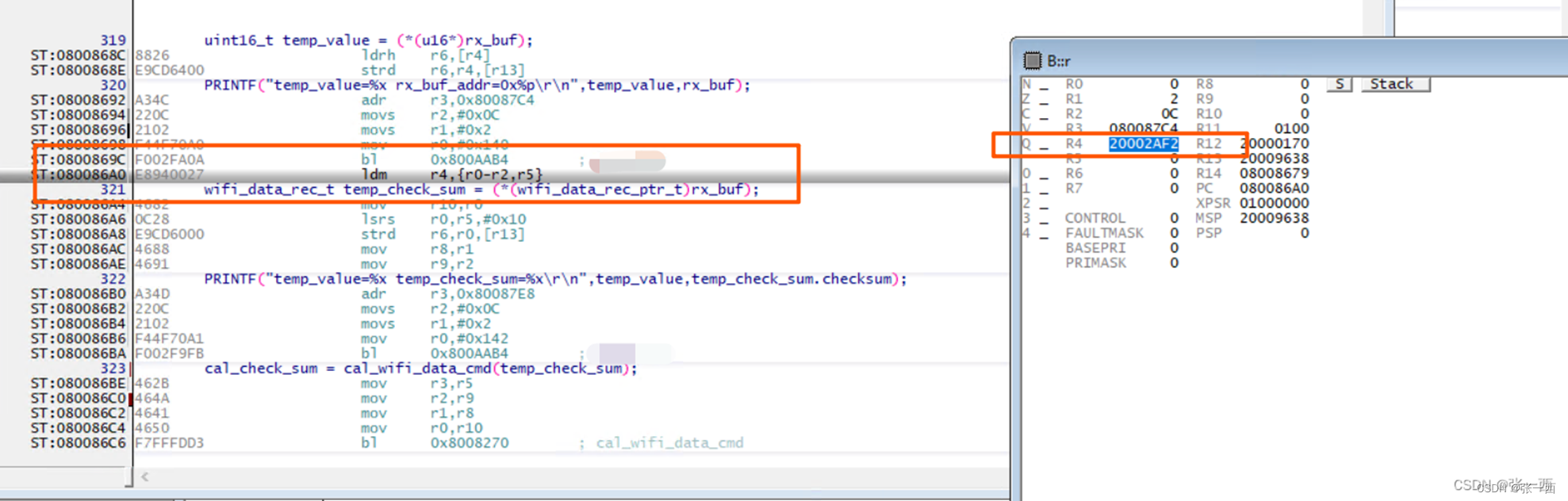
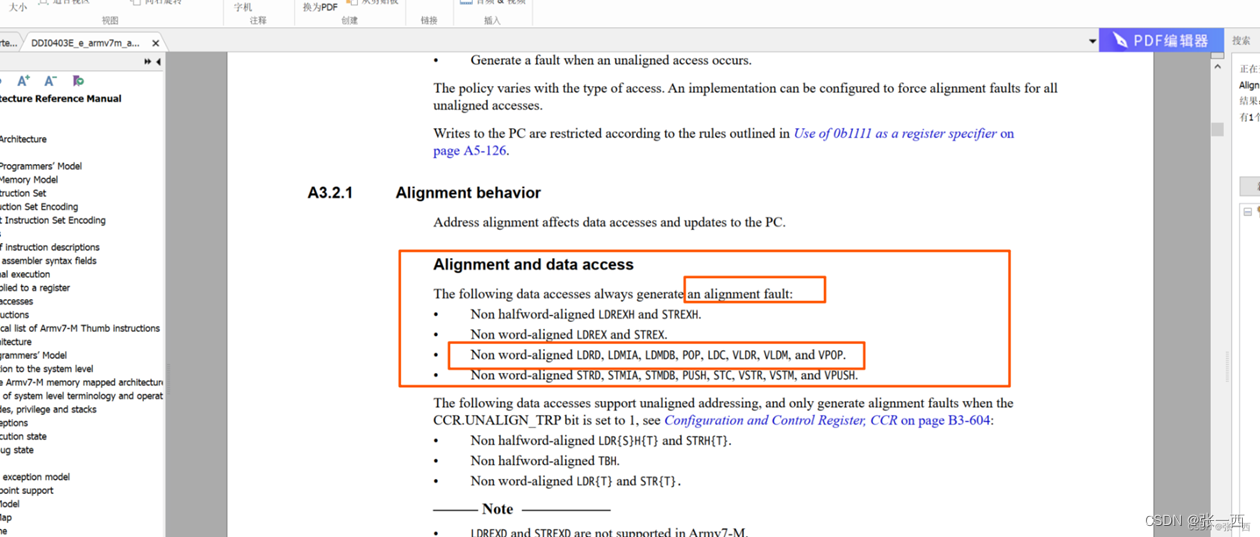
再来介绍一个存储指令对齐的问题,
- 27行 打印temp value的时候就出现了异常,Ozone调试软件出现非对齐的错误,触发coredump
- printf(“temp_value=%x rx_buf_addr=0x%p \r\n”,temp_value, rx_buf); 光看这个真看不出来为啥会产生非对齐错误,
- 具体原因可以参考这篇博客介绍ARM学习。(5) 异常模式学习(CortexM3/M4)


3.1.3、原子指令
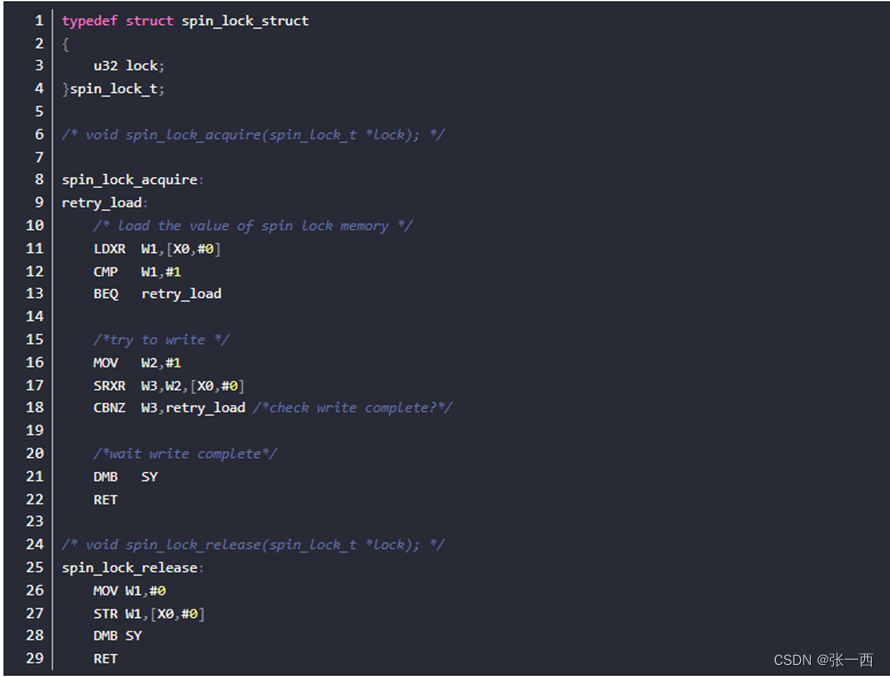
原子指令:其实就是执行某种功能指令,只不过是带有原子性的指令,也就是排他性访问指令,旨在为多核设计。


可以从下面的图看到,STREX会带有返回值(例如寄存器W3),可以知道成功还是失败,从而实现多核的互斥访问。
STREX W3,W2,[X0,#0]
CBNZ W3,retry_load

下面的代码可以参考自旋锁介绍ARM学习(20)自旋锁的理解与实现。
3.2、分支跳转指令
跳转指令主要用在函数调用等方面,以及栈回溯debug。
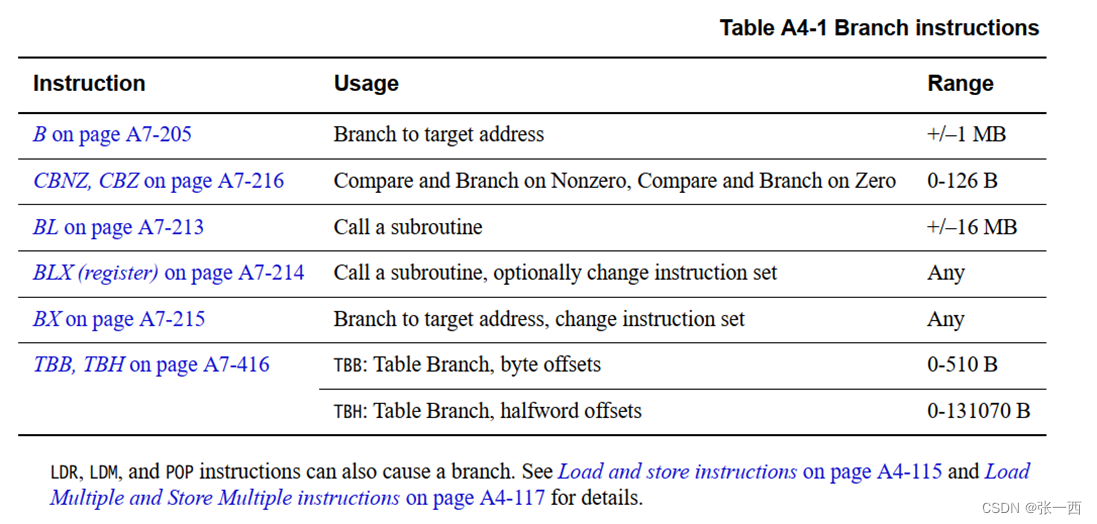
基本的跳转指令
B :跳转到目的地址,不跳回来,
BL:跳转到目的地之,然后将返回地址保存到LR,用于跳转回来
BX:跳到目的地址,并切换指令集,ARM分为ARM和Thumb指令集,两种指令切换,需要用到BX
BLX:带链接以及切换制冷剂的跳转
BR:br r0,跳转地址保存到寄存器当中,进行跳转,如下面第二种图
BLR:带连接的跳转,地址保存到寄存器当中
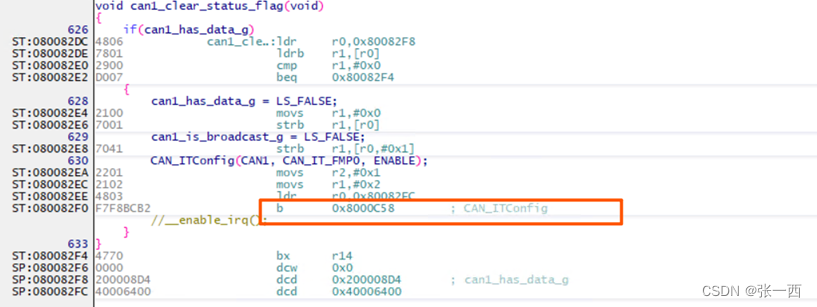
上面这个比较有点意思,直接跳到对应函数,不跳回来继续执行了,原因是什么呢?
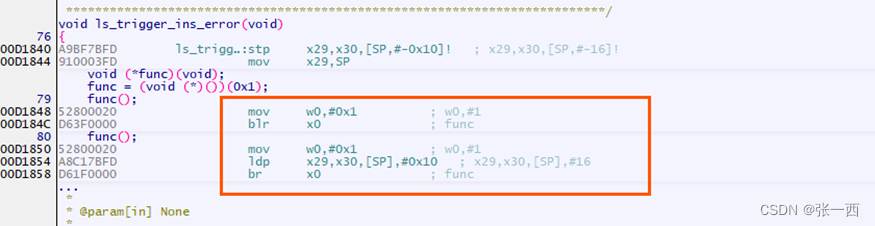
与比较进行结合,可以衍生出很多跳转指令,比如BEQ,相等则跳转,BNE,不等则跳转等等,看下面图介绍。

再来介绍一个具体的例子,跳转指令的例子。
当A、B、C和D四个函数,
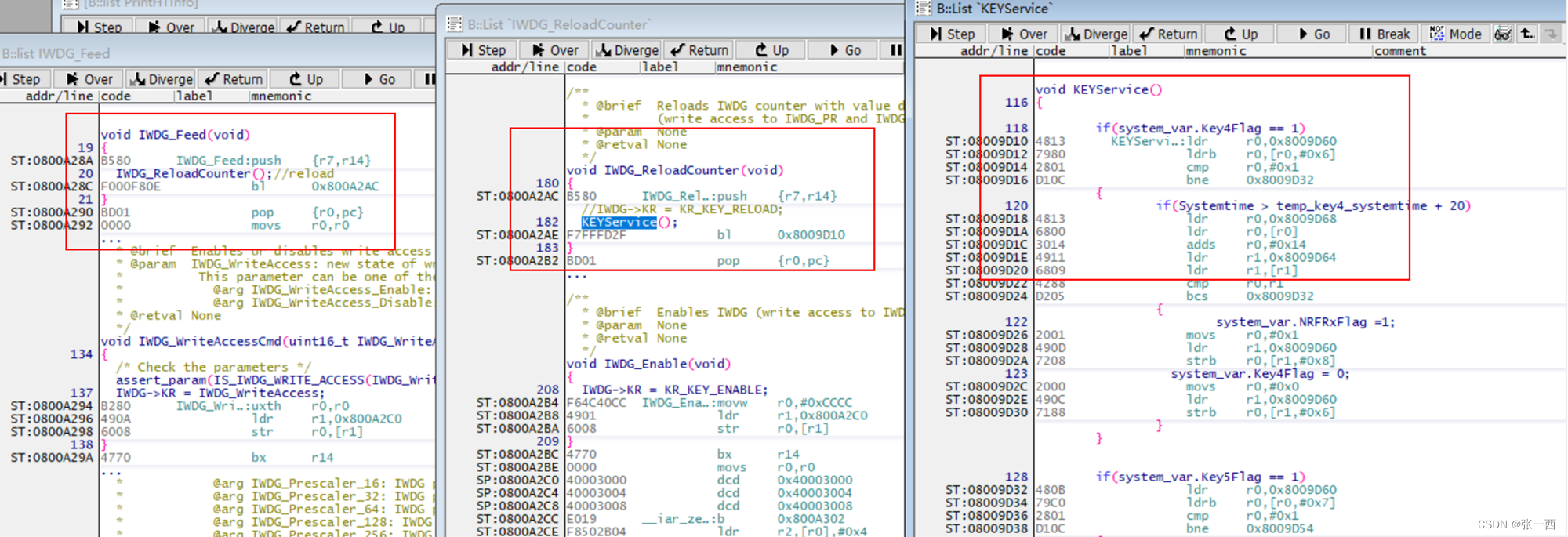
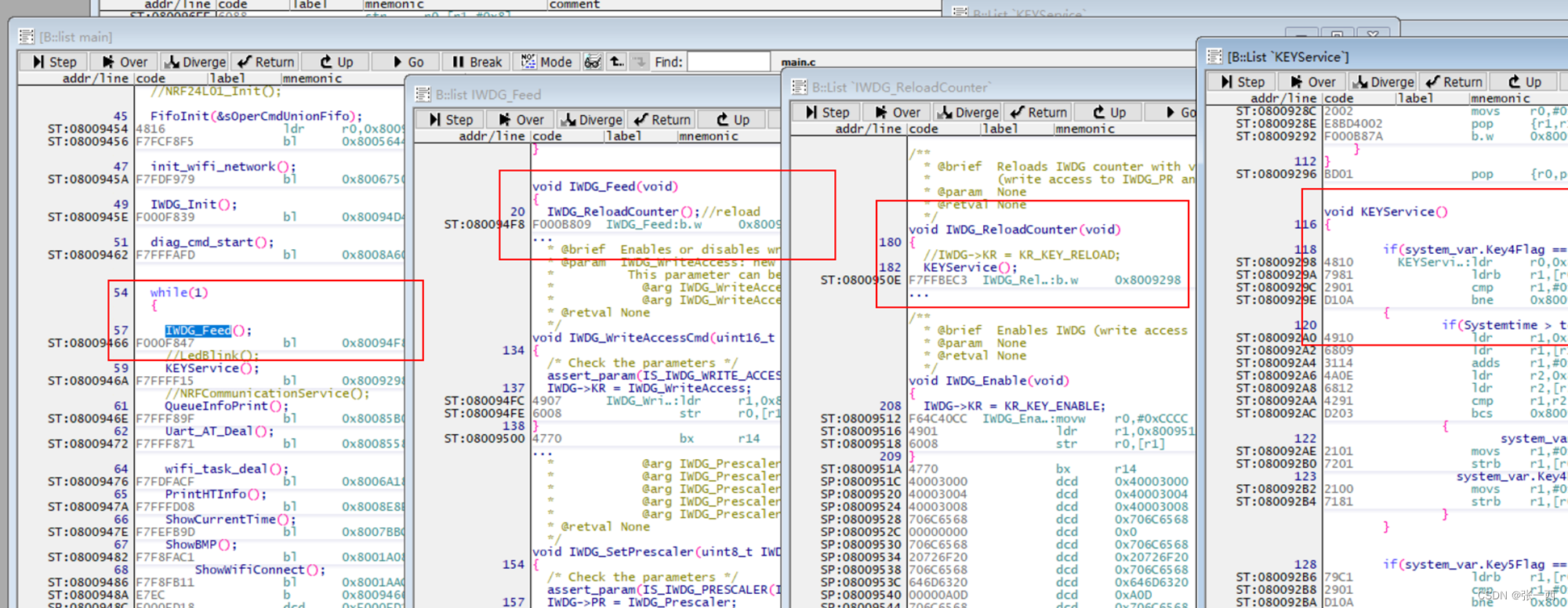
- A->B->C->D, main->IWDG_Feed->IWDG_ReloadCounter->KEYService是这样的调用关系时
- 没有优化时,可以看到A->B->C->D时,都是用到BL指令,D执行完了会跳回到C,然后再跳回到B,然后跳回到A。
- 仔细发现一下,还有个特点,B->C->D,都是只有一个函数,而且都是最后的函数调用,其实D执行完了,直接跳回到A就可以,不用跳回到C,因为跳回到C并没有执行任何用户有用的事情,
- 有些人不是看到释放栈空间的吗,其实可以看到栈基本都没有,只是原封不动的压入和压出,没有意义
- 所以优化之后,直接都是B 指令跳转,所以LR寄存器都不变,还是A函数中的下一行代码地址,所以D执行完成之后,直接跳回到A,也节省了很多指令,加快了速度,
- 所以再回到刚开始的问题,观察也是最后一行代码,执行完成之后,直接跳回到上一个调用本函数的地址处了,同样也没有压栈,也不需要释放栈空间。
















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











