







1.读取prototxt
from caffe.proto import caffe_pb2
from google.protobuf import text_format
net = caffe_pb2.NetParameter()
solver = caffe_pb2.SolverParameter()
f1=open('deploy.prototxt')
f2=open('solver.prototxt')
text_format.Merge(f1.read(), net) #把文本内容读进
text_format.Merge(f2.read(), solver)
layers = net.layer #众多层的内容,理解为list
l = layers[0] #取其中一层
#以下为各变量读取方法
l.name
l.type
l.bottom
l.top
l.convolution_param.num_output
#后面类比一样方法。solver的操作方法一样
2.修改prototxt
比如我要修改某层的名字,并另存为新的prototxt,操作如下,代码接上面:
net.layer[0].name = 'hello'
f = open('new.prototxt', 'w')
f.write(str(net))
f.close()
这样根据索引修改层有点麻烦。比如我想要把一个名为conv1的卷积层的kernel_size修改为5,怎么办?代码接上面:
dic_name = {} #根据名字对各层建立字典
layers = net.layer
for l in layers:
dic_name[str(l.name)]=l
dic_name['conv1'].convolution_param.kernel_size = 5
#这个kernel_size,包括所有的数值型参数,如pad等等,直接显示是 7L,
#通过type查看类型是long长整型。看的有点奇怪,但是可以像上面正常赋值,赋值之后变为5L。
同样,可以根据各自的需求,根据type、bottom、top建立字典。
3.读取caffemodel各层权重及中间blobs数值、形状
import caffe
model = caffe.Net('deploy.prototxt','m.caffemodel',caffe.TEST)
#注:这里是根据deploy的层来读取的。如果deploy没有的层而caffemodel有的层,是不会读进来的
#根据这个原理,分类模型的预训练模型,就要把最后的全连接层去掉,因为用于finetune的数据集类别数不一样。
#deploy去掉全连接层读取后,再model.save('caffemodel')即可得到预训练模型
#此处存放的是所有“有参数的层”的名字,无参数层如relu等不会进来
layer_names = model.params.keys()
#以卷积层为例
weight = model.params['conv1'][0].data #是numpy数组,形状用shape查看
bias = model.params['conv1'][1].data
#此处存放的是所有blob的名字
blob_names = model.blobs.keys()
blob = model.blobs['blob1'].data #是numpy数组,形状用shape查看
4.从caffemodel读取prototxt的内容
from caffe.proto import caffe_pb2
net = caffe_pb2.NetParameter()
f=open('m.caffemodel','rb') #这里注意,要用rb模式,就是二进制读入
net.ParseFromString(f.read())
#下面操作与第一部分一样,建立字典
layers = net.layer
dic_name = {}
for l in layers:
dic_name[str(l.name)] = l
直接显示dic_name['conv1_7x7_s2'],输出如下
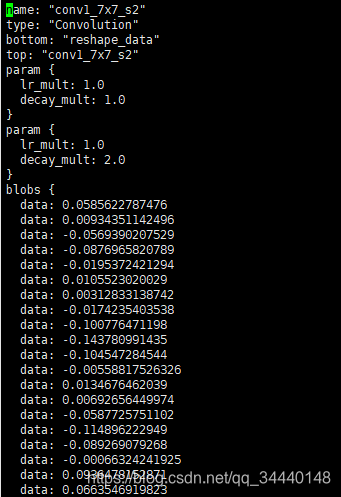
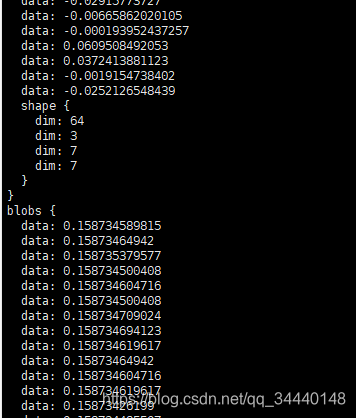
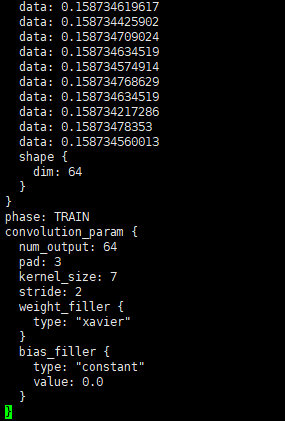
这个输出就有点像我们直接读取prototxt的内容了,但是有点区别。注意到中间有2个blob,并且内部还各有一个shape,不难判断出这2个blob分别是这个卷积层的weight和bias。注意:这里的blob和第3部分的blob含义不一样
以下为各示例(感觉这里的操作没什么用,因为在第3部分就能实现,看看就好):
>>> len(dic_name['conv1_7x7_s2'].blobs[0].data)
9408
>>> len(dic_name['conv1_7x7_s2'].blobs[1].data)
64
>>> dic_name['conv1_7x7_s2'].blobs[0].shape #weight
dim: 64
dim: 3
dim: 7
dim: 7
>>> dic_name['conv1_7x7_s2'].blobs[0].shape.dim
[64L, 3L, 7L, 7L]
>>> dic_name['conv1_7x7_s2'].blobs[1].shape #bias
dim: 64
>>> dic_name['conv1_7x7_s2'].blobs[1].shape.dim
[64L]
上面我们已经读取了一个layer的所有信息的prototxt内容,我们想把他写入prototxt里面,但是这个weight和bias的data太多了是我们不需要的,需要把他删除。于是通过dir()查找该变量的所有属性值,发现了一个ClearField
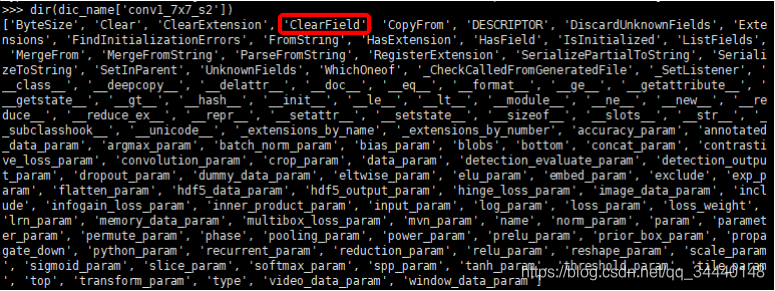
经过尝试
>>> dic_name['conv1_7x7_s2'].ClearField('blobs')
>>> dic_name['conv1_7x7_s2']
name: "conv1_7x7_s2"
type: "Convolution"
bottom: "reshape_data"
top: "conv1_7x7_s2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 1.0
decay_mult: 2.0
}
phase: TRAIN
convolution_param {
num_output: 64
pad: 3
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
已经可以看到不需要的杂乱的数据已经被删除了
对每一层都去掉blobs
for l in layers:
l.ClearField('blobs')
l.ClearField('phase')
f=open('aa.prototxt','w')
f.write(str(net))
f.close()
----实用代码:----
①BN层改为batchnorm+scale
以把BN层修改为batchnorm+scale为例:
from caffe.proto import caffe_pb2
from google.protobuf import text_format
net = caffe_pb2.NetParameter()
f1=open('a.prototxt')
text_format.Merge(f1.read(), net) #把文本内容读进
以此为例,我要将整个网络的BN层都修改为batchnorm+scale
>>> net.layer[1]
name: "conv1_7x7_s2_bn"
type: "BN"
bottom: "conv1_7x7_s2"
top: "conv1_7x7_s2_bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
bn_param {
slope_filler {
type: "constant"
value: 1.0
}
bias_filler {
type: "constant"
value: 0.0
}
}
使用type命令可以发现,net.layer是一个容器之类的类型,可能类似于list。
再使用dir查看net.layer的属性,发现有与list相同的append,pop,insert等成员函数
>>> type(net.layer)
<type 'google.protobuf.pyext._message.RepeatedCompositeContainer'>
>>> dir(net.layer)
['MergeFrom', '__class__', '__deepcopy__', '__delattr__', '__delitem__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__',
'__hash__', '__init__', '__le__', '__len__', '__lt__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__',
'__str__', '__subclasshook__', 'add', 'append', 'extend', 'insert', 'pop', 'remove', 'sort']
以下是完整代码:
改prototxt:
#coding=UTF-8
import sys
sys.path.insert(0,'/home/cdli/ECO2/caffe_3d/python')
import copy
from caffe.proto import caffe_pb2
from google.protobuf import text_format
import google
def create_layer(base_name_,type_,bottom_,top_):
layer = caffe_pb2.LayerParameter() #创建layer
layer.name = base_name_+'/'+type_
layer.type = type_
if type_ == 'batchnorm':
layer.bottom.append(bottom)
layer.top.append(top)
temp = caffe_pb2.ParamSpec()
temp.lr_mult = 0
temp.decay_mult = 0
layer.param.append(temp)
layer.param.append(temp)
layer.param.append(temp)
layer.batch_norm_param.use_global_stats = False
layer.batch_norm_param.eps = 0.00001
elif type_ == 'scale':
layer.bottom.append(top)
layer.top.append(top)
temp = caffe_pb2.ParamSpec()
temp.lr_mult = 0.2
temp.decay_mult = 0.2
layer.param.append(temp)
layer.param.append(temp)
layer.scale_param.filler.value = 1
layer.scale_param.bias_filler.value = 0
return layer
net1 = caffe_pb2.NetParameter()
net2 = copy.copy(net1)
deploy = 'deploy-pool3.prototxt'
text_format.Merge(open(deploy).read(), net1) #把文本内容读进
layers = net1.layer
for i, l in enumerate(layers):
if str(l.type)!='BN':
continue
name = str(l.name)
print name
bottom = str(l.bottom[0])
top = str(l.top[0])
batchnorm = create_layer(name,'batchnorm',bottom,top)
scale = create_layer(name,'scale',bottom,top)
layers.pop(i)
layers.insert(i, batchnorm)
layers.insert(i, scale)
with open(deploy.split('.')[0]+'-batchnorm.prototxt','w') as f:
f.write(str(net1))
caffemodel参数移动:
#coding=UTF-8
import sys
sys.path.insert(0,'/home/cdli/ECO2/caffe_3d/python')
import caffe
import numpy as np
import cv2
import scipy.io as sio
caffe.set_device(0)
caffe.set_mode_gpu()
deploy1='../deploy-lite-8-permute-batchnorm.prototxt'
deploy2='/home/cdli/ECO/model/lite/8fpermute/deploy-lite-8-permute.prototxt'
#model1='base.caffemodel'
model2='/home/cdli/ECO/model/lite/8fpermute/parse/after.caffemodel'
net1=caffe.Net(deploy1,caffe.TEST)
net2=caffe.Net(deploy2,model2,caffe.TEST)
net_layer1=net1.params.keys()
net_layer2=net2.params.keys()
net_blob1=net1.blobs.keys()
net_blob2=net2.blobs.keys()
for l in net_layer2:
print l
if 'bn' in l:
batchnorm_name=l.replace('_bn','/BatchNorm')
scale_name=l.replace('_bn','/scale')
bn=net2.params[l]
scale_=bn[0].data.reshape((-1,)) #BN参数
bias_=bn[1].data.reshape((-1,))
mean_=bn[2].data.reshape((-1,))
var_=bn[3].data.reshape((-1,))
batchnorm=net1.params[batchnorm_name]
scale=net1.params[scale_name]
batchnorm[0].data[:]=mean_[:] #移参数
batchnorm[1].data[:]=var_[:]
batchnorm[2].data[:]=1.0
scale[0].data[:]=scale_[:]
scale[1].data[:]=bias_[:]
else:
layer1=net1.params[l]
layer2=net2.params[l]
layer1[0].data[:]=np.copy(layer2[0].data)
layer1[1].data[:]=np.copy(layer2[1].data)
input1=np.zeros(shape=(224,224,3,8),dtype=np.float64)
input2=np.zeros(shape=(240,320,3),dtype=np.float64)
d = sio.loadmat("../rgb_mean.mat")
image_mean = d['image_mean'] # 224 224 3
lis=[]
for i in range(0,8):
img=cv2.imread('img/img_000'+str(i+1)+'.jpg')
img_reshape=img[16:240,60:284,:]-image_mean
input1[:,:,:,i]=img_reshape
lis.append(img_reshape)
if i==0:
input2=img_reshape
else:
input2=np.append(input2,img_reshape,axis=2)
# 输入数据确定
p=8
input2=input2[...,None]
input1=np.transpose(input1[:,:,:,:],(3,2,1,0)) #8 3 224 224
input2=np.transpose(input2[:,:,:,:],(3,2,1,0)) #1 24 224 224
input_minus=(input1[p-1,:,:,:]-input2[0,3*(p-1):3*p,:,:]).sum()
net1.blobs['data'].data[...]=input2
net2.blobs['data'].data[...]=input2
output1=net1.forward()
output2=net2.forward()
print 'out1=',output1
print 'out2=',output2
net1.save('after.caffemodel')
②batchnorm+scale转换为BN
修改prototxt:
#coding=UTF-8
import caffe
from caffe.proto import caffe_pb2
from google.protobuf import text_format
def create_layer(base_name_,type_,bottom_,top_):
layer = caffe_pb2.LayerParameter()
layer.name = base_name_+'_'+type_
layer.type = 'BN'
layer.bottom.append(bottom_)
layer.top.append(top_)
return layer
net = caffe_pb2.NetParameter()
deploy = 'deploy.prototxt'
f1=open(deploy)
text_format.Merge(f1.read(), net) #把文本内容读进
layers = net.layer #容器类型
dic_name = {}
for l in layers:
dic_name[str(l.name)] = l
#print layers
for i, l in enumerate(layers):
if l.type == 'Convolution':
print i,l.name
if l.name == 'conv1':
bottom = str(layers[i+1].bottom[0])
top = str(layers[i+2].top[0])
BN = create_layer('conv1','BN',bottom,top)
layers.pop(i+1).name
layers.pop(i+1).name
layers.insert(i+1, BN)
else:
bottom = str(layers[i+1].bottom[0])
top = str(layers[i+2].top[0])
base_name = l.name
BN = create_layer(base_name,'BN',bottom,top)
layers.pop(i+1).name
layers.pop(i+1).name
layers.insert(i+1, BN)
with open(deploy.split('.')[0]+'-batchnorm.prototxt','w') as f:
f.write(str(net))

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









