







文章目录
一、三种继承的方式
| 继承方式/基类成员 | public成员 | protected成员 | private成员 |
|---|---|---|---|
| public继承 | public | protected | 不可见 |
| protected继承 | protected | protected | 不可见 |
| private继承 | private | private | 不可见 |
注意:
-
基类成员在派生类中的访问权限不得高于继承方式中指定的权限。
-
不管继承方式如何,基类中的 private 成员在派生类中始终不能使用(不能在派生类的成员函数中访问或调用)。但是基类的 private 成员不能在派生类中使用,并没有说基类的 private 成员不能被继承。实际上,基类的 private 成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
-
在派生类中访问基类 private 成员的唯一方法就是借助基类的非 private 成员函数,如果基类没有非 private 成员函数,那么该成员在派生类中将无法访问。
-
使用 using 关键字可以改变基类成员在派生类中的访问权限,但是using 只能改变基类中 public 和 protected 成员的访问权限,不能改变 private 成员的访问权限,因为基类中 private 成员在派生类中是不可见的,根本不能使用,所以基类中的 private 成员在派生类中无论如何都不能访问。代码如下:
#include<iostream> using namespace std; //基类People class People { public: void show(); protected: char *m_name; int m_age; }; void People::show() { cout << m_name << "的年龄是" << m_age << endl; } //派生类Student class Student : public People { public: void learning(); public: using People::m_name; //将protected改为public using People::m_age; //将protected改为public float m_score; private: using People::show; //将public改为private }; void Student::learning() { cout << "我是" << m_name << ",今年" << m_age << "岁,这次考了" << m_score << "分!" << endl; } int main() { Student stu; stu.m_name = "小明"; stu.m_age = 16; stu.m_score = 99.5f; stu.show(); //compile error stu.learning(); return 0; }
二、继承的对象内存模型
没有继承关系时
成员变量和成员函数会分开存储:
- 对象的内存中只包含成员变量,存储在栈区或堆区(使用 new 创建对象);
- 成员函数与对象内存分离,存储在代码区。
存在单继承关系时
派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域——代码区,由所有对象共享。
若存在A、B、C三个类,C继承于B,B继承于A:
-
无成员变量遮蔽时的内存分布
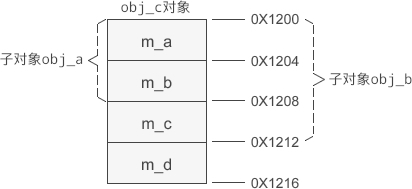
-
存在成员变量遮蔽时的内存分布
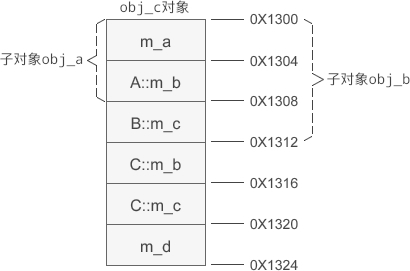
在派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。
存在多继承关系时
A、B 是基类,C 是派生类,假设 obj_c 的起始地址是 0X1000,那么 obj_c 的内存分布如下图所示:
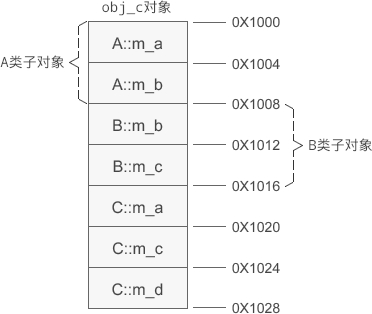
由此可知:基类对象的排列顺序和继承时声明的顺序相同。
存在虚继承关系时
对于普通继承,基类子对象始终位于派生类对象的前面(也即基类成员变量始终在派生类成员变量的前面),而且不管继承层次有多深,它相对于派生类对象顶部的偏移量是固定的。请看下面的例子:
class A{
protected:
int m_a1;
int m_a2;
};
class B: public A{
protected:
int b1;
int b2;
};
class C: public B{
protected:
int c1;
int c2;
};
class D: public C{
protected:
int d1;
int d2;
};
int main(){
A obj_a;
B obj_b;
C obj_c;
D obj_d;
return 0;
}
obj_a、obj_b、obj_c、obj_d 的内存模型如下所示:
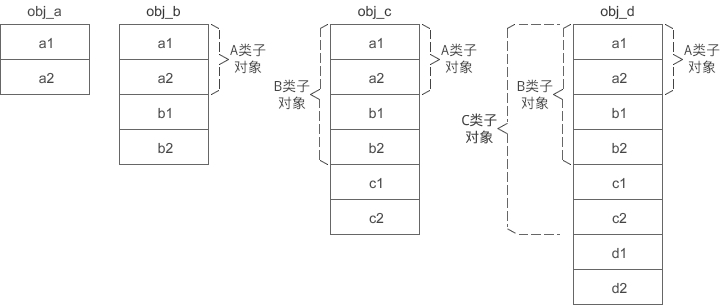
-
修改上面的代码,使得 A 是 B 的虚基类:
class B: virtual public A此时 obj_b、obj_c、obj_d 的内存模型就会发生变化,如下图所示:
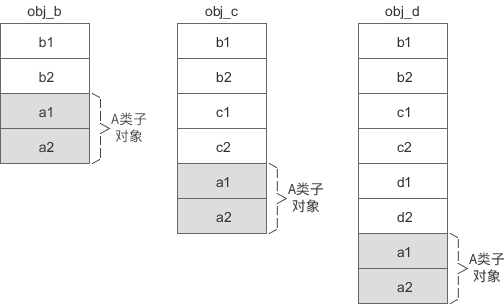
不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。
-
再假设 A 是 B 的虚基类,B 又是 C 的虚基类,那么各个对象的内存模型如下图所示:
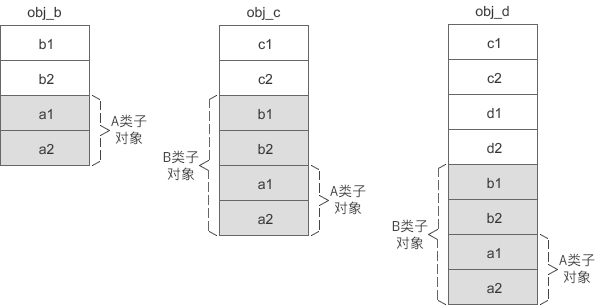
从上面的两张图中可以发现,虚继承时的派生类对象被分成了两部分:
- 不带阴影的一部分偏移量固定,不会随着继承层次的增加而改变,称为固定部分;
- 带有阴影的一部分是虚基类的子对象,偏移量会随着继承层次的增加而改变,称为共享部分。
三、继承时的构造函数
单继承
-
类的构造函数不能被继承,但是可以在派生类的构造函数中调用基类的构造函数,用于对继承过来的基类中的成员变量进行初始化工作。注意只能将基类构造函数的调用放在函数头部,不能放在函数体中。
// 正确示范 Student::Student(char *name, int age, float score): People(name, age), m_score(score){ } // 错误操作 Student::Student(char *name, int age, float score){ People(name, age); m_score = score; } -
基类构造函数总是优先被调用,并且派生类构造函数中只能调用直接基类的构造函数,不能调用间接基类的构造函数。
假如继承关系:A --> B --> C 创建C类对象时构造函数的执行顺序为(自顶向下):A类构造函数 --> B类构造函数 --> C类构造函数 调用顺序为(只能调用直接基类的构造函数):C类构造函数 --> B类构造函数,B类构造函数 --> A类构造函数
多继承
-
多继承构造函数写法:
D(形参列表): A(实参列表), B(实参列表), C(实参列表){ //其他操作 } -
基类构造函数的调用顺序和和它们在派生类构造函数中出现的顺序无关,而是和声明派生类时基类出现的顺序相同。
虚继承
-
在虚继承中,虚基类是由最终的派生类初始化的,换句话说,最终派生类的构造函数必须要调用虚基类的构造函数。
-
虚继承时构造函数的执行顺序与普通继承时不同:在最终派生类的构造函数调用列表中,不管各个构造函数出现的顺序如何,编译器总是先调用虚基类的构造函数,再按照出现的顺序调用其他的构造函数;而对于普通继承,就是按照构造函数出现的顺序依次调用的。
四、析构函数
单继承
- 析构函数不能被继承。
- 执行析构函数的顺序同构造函数执行顺序相反,先执行派生类的析构函数,在执行基类的构造函数。
多继承
- 多继承形式下析构函数的执行顺序和构造函数的执行顺序相同。
- 其他问题
① 继承时的名字遮蔽问题以及作用域嵌套
- 如果派生类中的成员(包括成员变量和成员函数)和基类中的成员重名,那么就会遮蔽从基类继承过来的成员。
- 基类成员函数和派生类成员函数不构成重载,不管函数的参数如何,只要名字一样就会造成遮蔽。
只有一个作用域内的同名函数才具有重载关系,不同作用域内的同名函数是会造成遮蔽,使得外层函数无效。派生类和基类拥有不同的作用域,所以它们的同名函数不具有重载关系。
- 当存在继承关系时,派生类的作用域嵌套在基类的作用域之内,如果一个名字在派生类的作用域内无法找到,编译器会继续到外层的基类作用域中查找该名字的定义。一旦在外层作用域中声明(或者定义)了某个名字,那么它所嵌套着的所有内层作用域中都能访问这个名字。同时,允许在内层作用域中重新定义外层作用域中已有的名字。
② 借助指针突破访问权限的限制,访问private、protected属性的成员变量 — 使用偏移
对象的内存模型中,成员变量和对象的开头位置会有一定的距离。以 obj 为例,它的内存模型为:
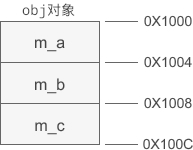
图中假设 obj 对象的起始地址为 0X1000,m_a、m_b、m_c 与对象开头分别相距 0、4、8 个字节,我们将这段距离称为偏移(Offset)。一旦知道了对象的起始地址,再加上偏移就能够求得成员变量的地址,知道了成员变量的地址和类型,也就能够轻而易举地知道它的值。
当通过对象指针访问成员变量时,编译器实际上也是使用这种方式来取得它的值。
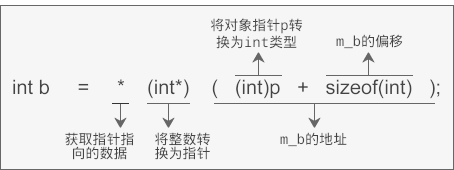
int b = p->m_b;
此时编译器内部会发生类似下面的转换:
int b = *(int*)( (int)p + sizeof(int) );
p 是对象 obj 的指针,(int)p将指针转换为一个整数,这样才能进行加法运算;sizeof(int)用来计算 m_b 的偏移;(int)p + sizeof(int)得到的就是 m_b 的地址,不过因为此时是int类型,所以还需要强制转换为int 类型;开头的用来获取地址上的数据。
③ 虚继承
为了解决多继承时的命名冲突和冗余数据问题,C++ 提出了虚继承,使得在派生类中只保留一份间接基类的成员。虚派生只影响从指定了虚基类的派生类中进一步派生出来的类(间接派生类),它不会影响派生类本身(直接派生类)。
虚继承的目的是让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类(Virtual Base Class)。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
④ C++向上转型
类其实也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义,并且只能将派生类赋值给基类,包括将派生类对象赋值给基类对象、将派生类指针赋值给基类指针、将派生类引用赋值给基类引用,这在 C++ 中称为向上转型(Upcasting)。相应地,将基类赋值给派生类称为向下转型(Downcasting)。
数据类型转换的前提是,编译器知道如何对数据进行取舍。
-
将派生类对象赋值给基类对象
赋值的本质是将现有的数据写入已分配好的内存中,对象的内存只包含了成员变量,所以对象之间的赋值是成员变量的赋值,成员函数不存在赋值问题。
将派生类对象赋值给基类对象时,会舍弃派生类新增的成员,也就是“大材小用”,如下图所示:
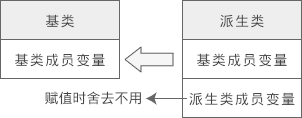
这种转换关系是不可逆的,只能用派生类对象给基类对象赋值,而不能用基类对象给派生类对象赋值。
-
将派生类指针赋值给基类指针
-
通过基类指针访问派生类的成员
将派生类指针赋值给基类指针时,通过基类指针只能使用派生类的成员变量,但不能使用派生类的成员函数。
一句话:编译器通过指针来访问成员变量,指针指向哪个对象就使用哪个对象的数据;编译器通过指针的类型来访问成员函数,指针属于哪个类的类型就使用哪个类的函数。
-
赋值后值不一致的情况
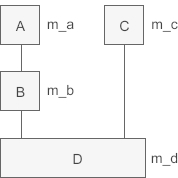
将派生类的指针赋值给基类的指针时,编译器可能会在赋值前进行处理。
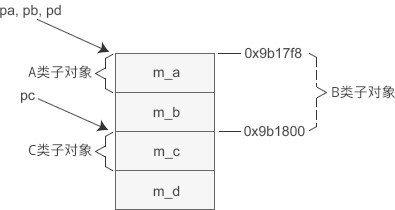
首先要明确的一点是,对象的指针必须要指向对象的起始位置。对于 A 类和 B 类来说,它们的子对象的起始地址和 D 类对象一样,所以将 pd 赋值给 pa、pb 时不需要做任何调整,直接传递现有的值即可;而 C 类子对象距离 D 类对象的开头有一定的偏移,将 pd 赋值给 pc 时要加上这个偏移,这样 pc 才能指向 C 类子对象的起始位置。也就是说,执行pc = pd;语句时编译器对 pd 的值进行了调整,才导致 pc、pd 的值不同。
-
-
将派生类引用赋值给基类引用
同 将派生类指针赋值给基类指针 原理一致。
注意:向上转型后通过基类的对象、指针、引用只能访问从基类继承过去的成员(包括成员变量和成员函数),不能访问派生类新增的成员。
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









