







论文地址:https://github.com/msmsajjadi/FRVSR
一、常用视频超分方法:
将视频超分任务(video SR task)看成多帧超分任务(multi-frame SR task,多幅LR图像生成一幅HR图像):
(1)利用输入帧和与输入帧相邻的帧图像,去生成单幅的输出帧(eg:用 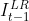 、
、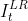 、
、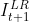 生成
生成 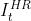 )。
)。
(2)通过滑窗的方式将(1)中方法作用在整个视频上,形成超分后的视频。
二、上面的多帧超分方法(multi-frame SR approach)的缺点:
(1)每个输出帧都是单独产生的,因此输出帧之间没有很好的时间一致性(temporally consistent results)。
(2)每一个视频输入帧都会经过多次处理(因为两个相邻的滑窗间会有交叠的视频帧),这增加了计算量。
三、本文提出的 frame-recurrent video super-resolution (FRVSR) 框架的优点
(1)相对于其他的方法不仅更有效率(只使用了当前时刻的LR图像,和前一时刻预测的HR图像),而且在生成图像的质量上也有很大的提升。
(2)生成的视频有更好的时间一致性。
(3)全卷积、端到端(fully convolutional and end-to-end trainable)。
四、本文提出的 FRVSR 的网络框架
(黑线左边是 FRVSR 框架,黑线右边是损失函数)
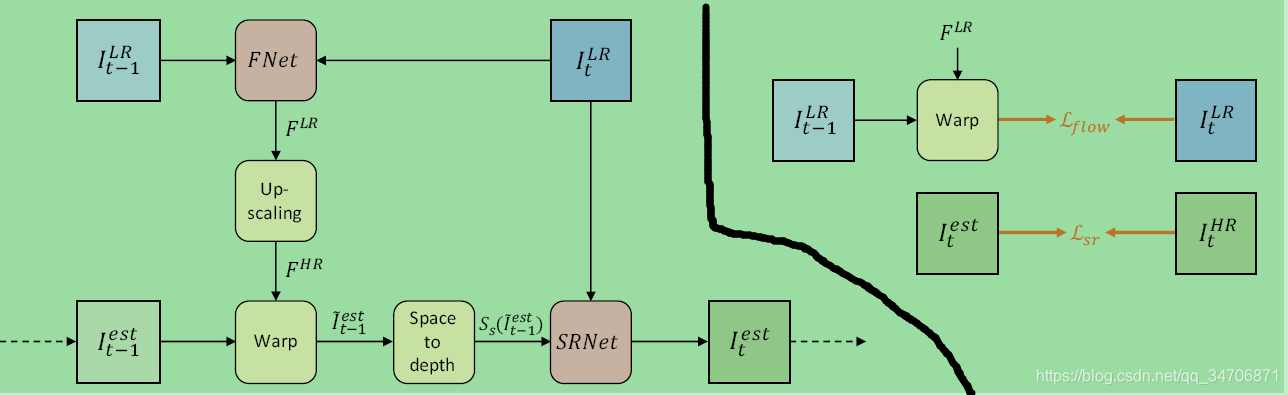
1、使用 FNet(光流预测网络) 在低分辨率空间(LR-space)生成 与 之间的光流(flow) 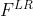 。
。
2、将低分辨率光流(LR flow) 上采样成高分辨率光流(HR flow) 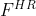 ,本文采用的是双线性插值的方法。
,本文采用的是双线性插值的方法。
3、将高分辨率光流 施加在前一帧的预测图像 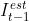 上,得到
上,得到 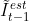 。
。
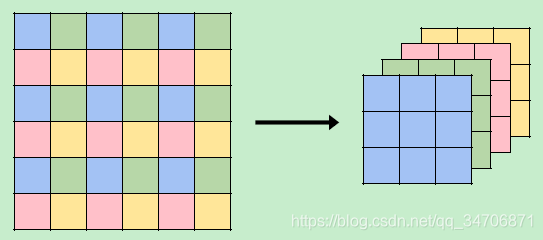
4、通过 space-to-depth 转换(Sub-pixel的相反过程,如下图)将 映射回低维空间(LR space),得到 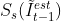 。
。
5、将 与当前时刻低分辨率帧 在channel 维度上连接起来,一起送到超分网络(SRNet),生成当前帧所对应的HR帧 。
五、损失函数
(如上图黑线右边所示)
1、FNet(光流预测网络)的损失函数:
由于没有关于光流()的标签(ground truth),因此将生成的光流作用在 上,然后计算其与 之间的均方误差:
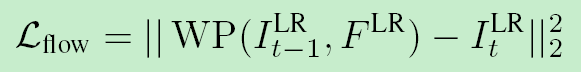
2、 SRNet(超分网络)的损失函数:
也是普通的均方误差
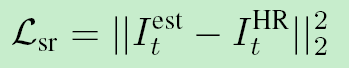
六、SRNet 与 FNet(光流预测网络)的结构
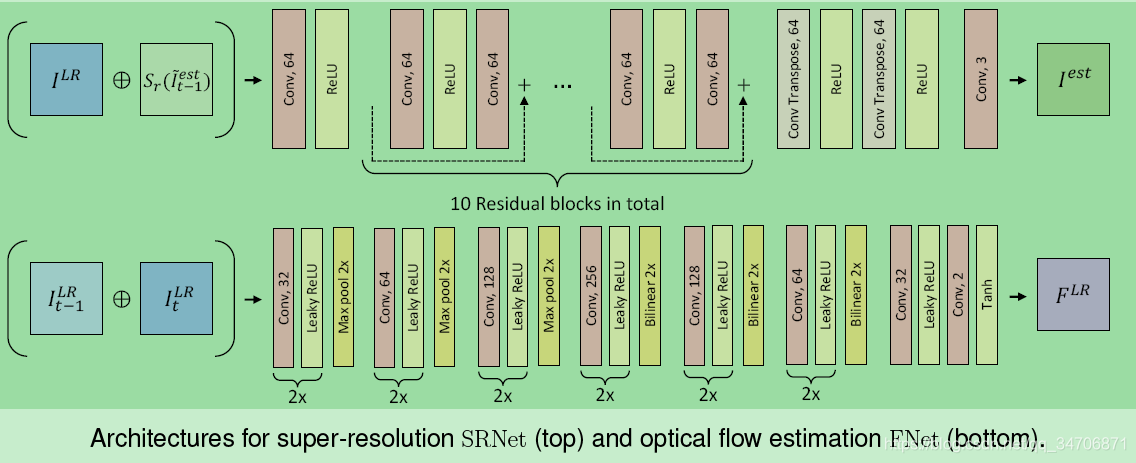
FRVSR 是一个灵活的网络框架,其中的 SRNet 和 FNet 可以有很多不同的选择。
本文采用的 SRNet 和 FNet 都是比较简单(为了平衡重建质量与计算复杂度)的全卷积网络,如上图所示:
(1)FNet(下)采用的是 encoder-decoder(编-解码)架构,也就是前半部分通过 max pool 下采样,后半部分通过 Bilinear 上采样, 目的是为了增大卷积的感受野。注:图中的 “2x” 表示的是重复的层。
(2)SRNet(上)采用的是残差结构,通过反卷积(transposed convolutions)完成上采样。
七、本文提出的方法的不足之处
FRVSR 架构依赖于 去获取当前帧之前的帧图像信息,虽然这种方法能够获得当前帧之前的很多帧的信息(而 multi-frame SR 只能获取指定数量的帧的信息,如 、、 ),但前提条件是这些信息必须在 中出现,否则这些信息将全部丢失(前面帧的信息只能通过 向后传),比如在第 t-2 帧出现了一条狗,而第 t-1 帧中有一辆车挡住了狗,则第 t-2 帧中狗的信息不能传播到第 t 帧(因为第 t 帧只接收来自第 t 帧的LR图像和第 t-1 帧的预测图像)

















 5616
5616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









