







SIGIR20|LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation

文章链接:https://dl.acm.org/doi/10.1145/3397271.3401063
代码链接:https://github.com/gusye1234/LightGCN-PyTorch
ABSTRACT
图卷积网络已经成为结合协同过滤算法的最新技术。但是,它推荐的有效性的原因还不是很明确。现有的使GCN适应推荐的工作缺乏对GCN的消融分析,GCN由于参考了卷积神经网络改造而来,所以包含许多神经网络操作。但是作者基于实验发现GCN最常见的两个设计-特征转换和非线性激活对协同过滤的性能几乎没有影响。反而增加了训练的难度,并降低性能。
作者提出一个简化GCN的模型LightGCN,只包含GCN最重要的组成部分,例如领域的聚合,多层传播。通过在用户-项目交互图上线性传播用户和项目的嵌入来学习它们,最后将所有层上学习到的用户和项目嵌入加权和算作最后的预测得分。项目NGCF性能虽然改进了很多,但是通过消融性分析,我们发现性能有所提升,最后我们进行实验对LightGCN合理性进行分析。
1 Instruction
为了减轻网络上的信息过载,推荐器系统已被广泛部署以执行个性化信息过滤。 推荐系统的核心是预测用户是否将与商品交互,例如点击,评分,购买以及其他形式的交互。 因此,专注于利用过去的用户项目交互来实现预测的协作过滤(CF)仍然是实现有效个性化推荐的一项基本方法。 CF的最常见范例是学习表示用户和商品的潜在特征(也称为嵌入),并基于嵌入矢量进行预测。 矩阵分解是一种早期的模型,它直接将用户的单个ID投影到她的嵌入中。 后来,一些研究发现,使用用户交互历史作为输入来增加用户ID可以提高嵌入质量。 例如,SVD ++ 演示了用户交互历史记录在预测用户数字评分方面的好处,而神经注意力项目相似度(NAIS)则在交互历史记录中区分了项目的重要性,并显示了预测项目排名方面的改进。 鉴于用户项交互图,这些改进可以看作来自使用用户的子图结构(更具体地说,是她的单跳邻居)来改进嵌入学习。 为了加深与高跳邻居的子图结构的使用,Wang等人。 最近提出了NGCF,并实现了CF的最新性能。 它从图卷积网络(GCN)[14,23]得到启发,传播的方法包括特征变换,邻域聚合和非线性激活。
我们基于实验提出的LightGCN表明特征变换和非线性激活对协同过滤的有效性没有积极影响。
•我们提出了LightGCN,通过仅在GCN中包含最重要的组件以供推荐,从而大大简化了模型设计。
•我们通过遵循相同的设置,以经验将LightGCN与NGCF进行比较,并展示出实质性的改进。 从技术和经验角度对LightGCN的合理性进行了深入分析。
2 Preliminaries
2.1 NGCF简介
我们在将用户和项目从ID嵌入成向量后,然后利用用户-项目二部图来进行传播,传播算法如下:
e
u
(
k
+
1
)
=
σ
(
W
1
e
u
(
k
)
+
∑
i
∈
N
u
1
∣
N
u
∣
∣
N
i
∣
(
W
1
e
i
(
k
)
+
W
2
(
e
i
(
k
)
⊙
e
u
(
k
)
)
)
)
e
i
(
k
+
1
)
=
σ
(
W
1
e
i
(
k
)
+
∑
i
∈
N
i
1
∣
N
u
∣
∣
N
i
∣
(
W
1
e
u
(
k
)
+
W
2
(
e
u
(
k
)
⊙
e
i
(
k
)
)
)
)
e^{(k+1)}_u = \sigma(W_1e_u^{(k)} + \sum_{i \in N_u}\frac{1}{\sqrt{|N_u||N_i|}}(W_1e_i^{(k)}+W_2(e_i^{(k)}⊙ e_u^{(k)})))\\ e^{(k+1)}_i = \sigma(W_1e_i^{(k)} + \sum_{i \in N_i}\frac{1}{\sqrt{|N_u||N_i|}}(W_1e_u^{(k)}+W_2(e_u^{(k)}⊙ e_i^{(k)})))
eu(k+1)=σ(W1eu(k)+i∈Nu∑∣Nu∣∣Ni∣1(W1ei(k)+W2(ei(k)⊙eu(k))))ei(k+1)=σ(W1ei(k)+i∈Ni∑∣Nu∣∣Ni∣1(W1eu(k)+W2(eu(k)⊙ei(k))))
其中
e
u
(
k
)
e^{(k)} _u
eu(k) 和
e
i
(
k
)
e^{(k)} _i
ei(k) 分别表示用户u的嵌入和项目i的嵌入,k表示传播的层数,
σ
\sigma
σ表示非线性激活函数,
N
i
N_i
Ni 表示与用户u交互的邻居项目i,
W
1
W_1
W1和
W
2
W_2
W2 是训练的权重矩阵。
2.2 NGCF的实验探索
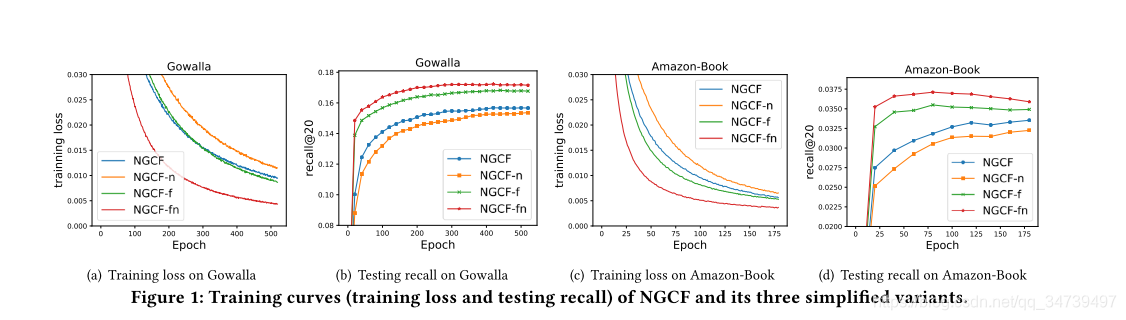
- NGCF-f,它删除了特征转换矩阵W1和W2。
- NGCF-n,它消除了非线性激活函数σ。
- NGCF-fn,它删除了两个特征转换矩阵和非线性激活函数。
可以看到NGCF-fn的召回率和loss都有明显改善。所以通过准备阶段的实验研究,我们发现特征转换矩阵和非线性激活函数对我们的结果影响不大,反而性能还有所下降,于是下面提出我们的模型LightGCN。
3 Method
本节中,我们首先介绍我们设计的轻图卷积网络(LightGCN)模型,如图2所示。然后,我们对LightGCN进行深入分析,以显示其简单设计背后的合理性。 最后,我们描述了如何进行模型训练以进行推荐。
3.1 LightGCN
GCN的基本思想是通过平滑图上的特征来学习节点的表示。 为了实现这一点,它迭代地执行图卷积,即,将邻居的特征聚合为目标节点的新表示。 这种邻域聚合可以抽象为:
e
u
(
k
+
1
)
=
A
G
G
(
e
u
(
k
)
,
e
i
(
k
)
:
i
∈
N
u
)
e^{(k+1)}_ u = AGG(e^{(k)}_ u , {e^{(k)}_ i : i ∈ N_u })
eu(k+1)=AGG(eu(k),ei(k):i∈Nu)
AGG是一个聚合函数(图形卷积的核心),它考虑了目标节点及其邻居节点的第k层表示形式。 例如GIN 中的加权和聚合器,GraphSAGE 中的LSTM聚合器和BGNN 中的双线性交互聚合器等。但是,大多数都具有转换或非线性激活的功能。 具有AGG功能。 尽管它们在具有语义输入功能的节点或图分类任务上表现良好,但是它们对于协作过滤可能很繁琐。
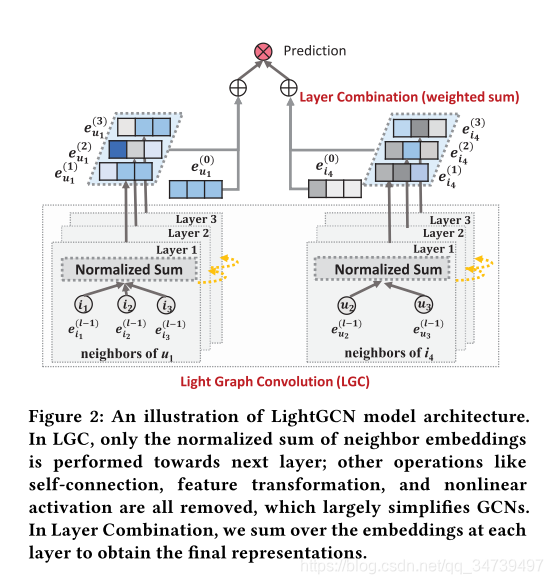
3.1.1 Light Graph Convolution
在LightGCN中,我们采用简单的加权和聚合器,而不使用特征变换和非线性激活。 LightGCN中的图卷积运算定义为:
e
u
(
k
+
1
)
=
∑
i
∈
N
u
1
∣
N
u
∣
∣
N
i
∣
e
i
(
k
)
e
i
(
k
+
1
)
=
∑
u
∈
N
i
1
∣
N
u
∣
∣
N
i
∣
e
u
(
k
)
e^{(k+1)}_u =\sum_{i \in N_u}\frac{1}{\sqrt{|N_u||N_i|}} e^{(k)}_i\\ e^{(k+1)}_i =\sum_{u \in N_i}\frac{1}{\sqrt{|N_u||N_i|}} e^{(k)}_u
eu(k+1)=i∈Nu∑∣Nu∣∣Ni∣1ei(k)ei(k+1)=u∈Ni∑∣Nu∣∣Ni∣1eu(k)
3.1.2 层组合和模型预测
e u = ∑ k = 0 K α k e u ( k ) ; e i = ∑ k = 0 K α k e i ( k ) e_u = \sum^K_{k=0} α_ke^{(k)}_u ; \\ ei = \sum^K_{k=0} α_ke^{(k)}_i eu=k=0∑Kαkeu(k);ei=k=0∑Kαkei(k)
其中,αk≥0表示第k层嵌入在构成最终嵌入中的重要性。 可以将其视为要手动调整的超参数,也可以将其视为要自动优化的模型参数。 在我们的实验中,我们发现将αk统一设置为1 /(K +1)通常可获得良好的性能。 因此,我们无需设计特殊组件来优化αk,从而避免不必要地使LightGCN复杂化并保持其简单性。 我们执行图层组合以获得最终表示的原因有三点。 (1)随着层数的增加,嵌入会变得更加平滑[27]。 因此,仅使用最后一层是有问题的。 (2)不同层的嵌入具有不同的语义。 例如,第一层对具有交互作用的用户和项目强制执行平滑操作,第二层对在交互的项(用户)上重叠的用户(项目)进行平滑操作,更高的层则捕获较高级别的邻近度。 因此,将它们结合起来将使表示更加全面。 (3)将不同层的嵌入与加权和结合起来,可以捕获图卷积和自连接的效果,。
模型预测被定义为用户和项目最终表示的得分:
y
^
u
i
=
e
u
T
e
i
,
\hat{y}_{ui} = e^T _u e_i ,
y^ui=euTei,
3.1.3 矩阵形式
将用户与项目i交互矩阵R,其中
R
u
i
R_{ui}
Rui 为1表示u与i交互,反之为0。我们将领接矩阵表示为:
A
=
(
0
R
R
T
0
)
A=\begin{pmatrix} 0 & R\\ R^T & 0 \end{pmatrix}
A=(0RTR0)
E = α 0 E ( 0 ) + α 1 E ( 1 ) + α 2 E ( 2 ) + . . . + α K E ( K ) = α 0 E ( 0 ) + α 1 ˜ A E ( 0 ) + α 2 ˜ A 2 E ( 0 ) + . . . + α K ˜ A E ( 0 ) E = α_0E(0) + α_1E(1) + α_2E(2) + ... + α_KE(K)\\ = α_0E(0) + α_1 ˜AE(0) + α_2 ˜A 2 E(0) + ... + α_K ˜A E(0) E=α0E(0)+α1E(1)+α2E(2)+...+αKE(K)=α0E(0)+α1˜AE(0)+α2˜A2E(0)+...+αK˜AE(0)
其中 A ~ = D − 1 2 A D − 1 2 \widetilde{A}= D^{-\frac{1} {2}} AD^{-\frac{1} {2}} A =D−21AD−21是对称归一化矩阵, α \alpha α 是学习层组合系数。
3.2 模型训练
我们采用BPR作为损失函数训练模型:
L
B
P
R
=
−
∑
u
=
1
M
∑
i
∈
N
u
∑
j
∉
N
u
l
n
σ
(
y
^
u
i
−
y
^
u
j
)
+
λ
∣
∣
E
(
0
)
∣
∣
2
L_{BPR} = − \sum^M_{u=1}\sum_{i\in N_u}\sum_{j \notin N_u} lnσ( \hat{y}_{ui} − \hat{y}_{uj} ) + λ||E(0) ||2
LBPR=−u=1∑Mi∈Nu∑j∈/Nu∑lnσ(y^ui−y^uj)+λ∣∣E(0)∣∣2
其中λ控制L2正则化强度。我们用Adam优化并且小批量方法。
4 实验
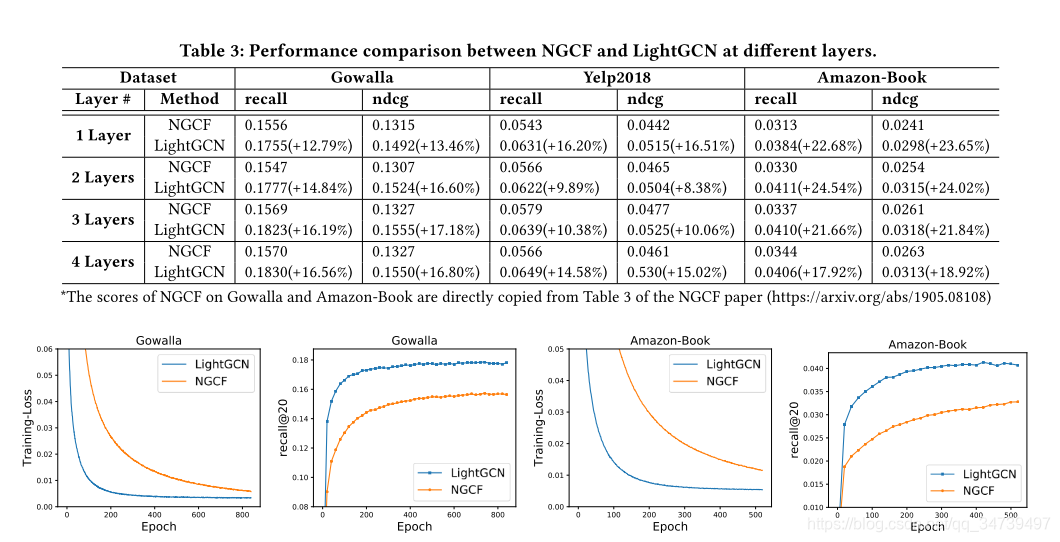
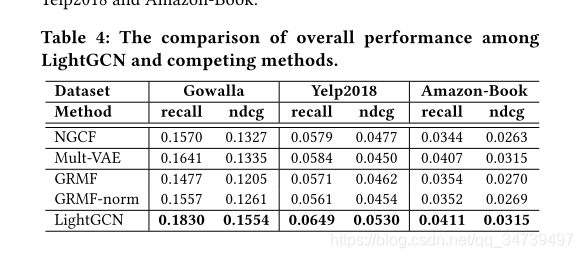
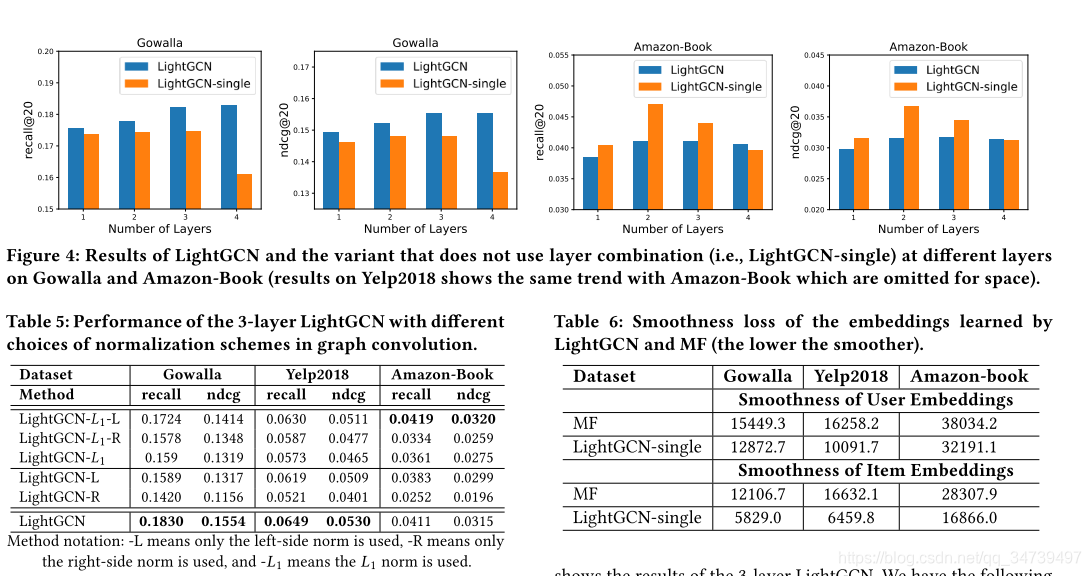
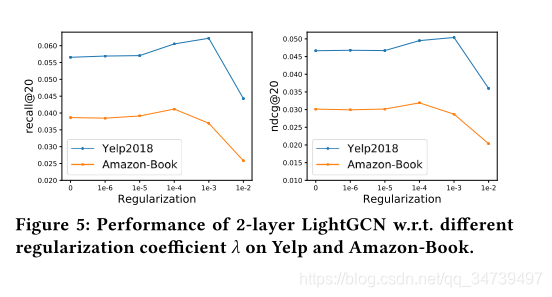














 3463
3463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









