






一、文章概述
- 研究背景
NGCF的设计无脑继承了GCN,这对于协同过滤任务来说过于沉重,减慢了训练速度和效率。 - 本文贡献
1)通过实验证明,GCN的特征转换和非线性激活,对协同过滤的有效性没有积极影响;
2)提出LightGCN,它通过仅包括GCN最重要的推荐组件,简化了模型设计并提高了性能;
3)按照相同的设置同其他先进协同过滤和图卷积推荐模型进行比较,对LightGCN的合理性进行了深入分析。
二、相关工作
1. 相关工作
1)协同过滤:CF模型的一个常见范例是将用户和项目参数化为嵌入,并通过重构历史用户项目交互来学习嵌入参数。
2)推荐的图方法:最近的工作(NGCF、PinSage、SGCN)使GCN适应用户-项目交互图,捕捉高跳邻居中的CF信号以进行推荐。
2. Preliminaries
1)NGCF
(1)初始化:每个用户和项目斗都与一个ID嵌入向量相关联,
e
u
(
0
)
e_u^{(0)}
eu(0)表示用户u的ID嵌入,
e
i
(
0
)
e_i^{(0)}
ei(0)表示项目i的ID嵌入。
(2)传播:NGCF利用用户项目交互图传播方式如下:

其中,
- e u ( k ) e_u^{(k)} eu(k)、 e u ( k ) e_u^{(k)} eu(k)表示用户u和项目i在k层传播后的精细嵌入;
- σ σ σ为非线性激活函数;
- N u N_u Nu表示与用户u交互的项目集合, N i N_i Ni表示与项目i交互的用户集合;
- W 1 , W 2 W_1,W_2 W1,W2为可训练的权重矩阵,用于在每层中执行特征变换。
(3)预测:NGCF获得L + 1个嵌入,分别为
(
e
u
(
0
)
,
e
u
(
1
)
,
.
.
.
,
e
u
(
k
)
)
,
(
e
i
(
0
)
,
e
i
(
1
)
,
.
.
.
,
e
i
(
k
)
)
(e_u^{(0)},e_u^{(1)},...,e_u^{(k)}),(e_i^{(0)},e_i^{(1)},...,e_i^{(k)})
(eu(0),eu(1),...,eu(k)),(ei(0),ei(1),...,ei(k)),最后分别将这L+1个嵌入连接,获得最终的用户嵌入和项目嵌入,并使用内积运算生成预测得分。
2)NGCF的消融研究
用NGCF的三个简化变体表明LightGCN改进的必要性,
- NGCF-f:去除特征变换矩阵 W 1 , W 2 W_1,W_2 W1,W2;
- NGCF-n:去除非线性激活函数σ;
- NGCF-fn:去除特征变换矩阵和非线性激活函数σ。
除此以外,保留所有超参数(例如,学习率、正则化系数、辍学率等)与NGCF的最佳设置相同。
实验结果如下,
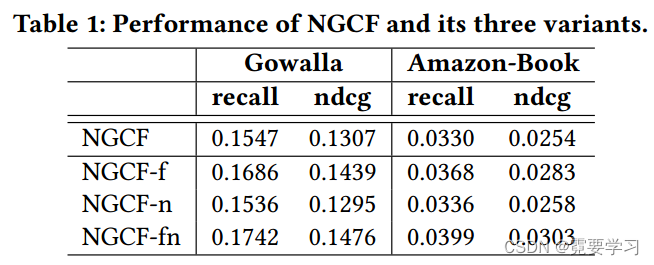
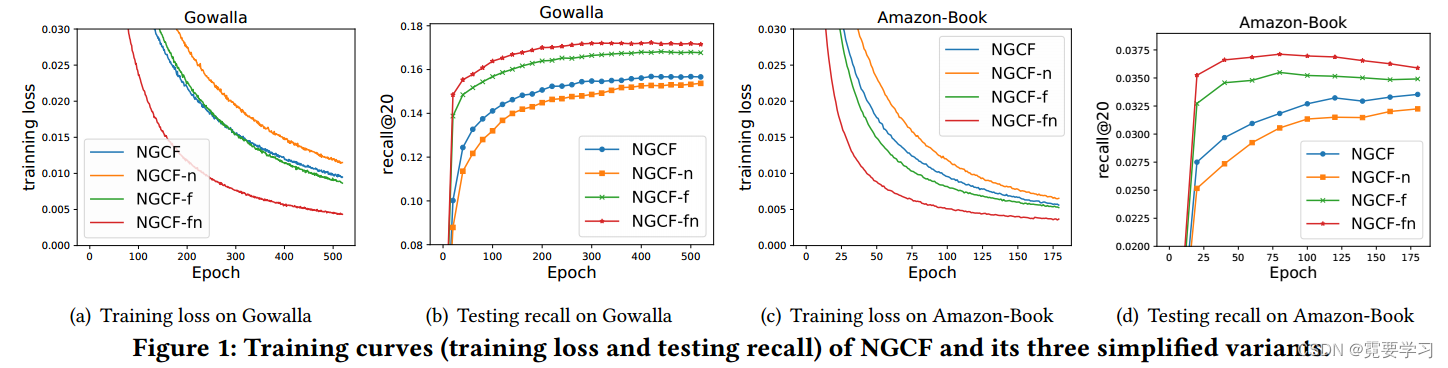
从这些观察中,我们得出结论:
- 添加特征变换对NGCF有负面影响,因为在NGCF和NGCF-n模型中去除特征变换显著提高了性能;
- 当包含特征变换时,添加非线性激活影响较小,但当特征变换被禁用时,它施加负面影响;
- 总体而言,特征转换和非线性激活对NGCF产生了相当负面的影响,因为通过同时去除它们,NGCF-fn的性能有巨大改进。
三、LightGCN
1.轻型图卷积(LGC)
原始GCN基本思想是通过平滑图中的特征来学习节点的表示,为了实现这一点,它迭代地执行图卷积,即聚合邻居的特征作为目标节点的新表示,这样的邻域聚合可以抽象为
e
u
(
k
+
1
)
=
A
G
G
(
e
u
(
k
)
,
{
e
i
(
k
)
:
i
∈
N
u
}
)
e_u^{(k+1)}=AGG(e_u^{(k)},\{e_i^{(k)}:i∈N_u\})
eu(k+1)=AGG(eu(k),{ei(k):i∈Nu}),AGG是聚合函数——图卷积的核心——它考虑了目标节点及其邻居节点的第k层表示。根据上一节的实验验证,将特征变换或非线性激活喝AGG激活函数相联系对于协同过滤来说可能是繁重的。
所以在LightGCN中,使用轻型图卷积(LGC),其图卷积运算(传播规则)如下:
e u ( k + 1 ) = ∑ i ∈ N u 1 ∣ N u ∣ ∣ N i ∣ e u ( k ) e_u^{(k+1)}=\sum_{i∈N_u}\frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}e_u^{(k)} eu(k+1)=∑i∈Nu∣Nu∣∣Ni∣1eu(k)
e i ( k + 1 ) = ∑ u ∈ N i 1 ∣ N u ∣ ∣ N i ∣ e i ( k ) e_i^{(k+1)}=\sum_{u∈N_i}\frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}e_i^{(k)} ei(k+1)=∑u∈Ni∣Nu∣∣Ni∣1ei(k)
其中,
1
∣
N
u
∣
∣
N
i
∣
\frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}
∣Nu∣∣Ni∣1为对称的归一化项,遵循标准的GCN设计,这样可以避免嵌入的规模随着图卷积运算而增加(还有其他选择,根据后期实验验证,这种方式性能良好)
在LGC中,仅聚合连接的邻居,而不整合目标节点本身(即自连接)。这不同于大多数现有的图卷积运算,大多数图卷积运算通常不仅聚合扩展的邻居,还需要专门处理自连接。
2.层组合及模型预测
在LightGCN中,唯一可训练的模型参数是第0层的嵌入,即
e
u
(
0
)
e_u^{(0)}
eu(0)用于所有用户,
e
i
(
0
)
e_i^{(0)}
ei(0)用于所有项目。
当给定该参数时,可以通过LGC的传播规则来计算更高层的嵌入。在K层LGC之后,进一步组合在每一层获得的嵌入以形成最终的表示如下
e
u
=
∑
k
=
0
K
α
k
e
u
(
k
)
;
e
i
=
∑
k
=
0
K
α
k
e
i
(
k
)
e_u=\sum_{k=0}^Kα_ke_u^{(k)};e_i=\sum_{k=0}^Kα_ke_i^{(k)}
eu=k=0∑Kαkeu(k);ei=k=0∑Kαkei(k)其中,
α
k
α_k
αk表示第k层嵌入在构成最终嵌入中的重要性,可以作为手动调整的超参数,或者自动优化的模型参数(如注意力网络的输出),本文实验证明设为
1
K
+
1
\frac{1}{K+1}
K+11具有良好的性能。
执行层组合来获得最终表示原因如下:
- (1)随着层数的增加,嵌入会过度平滑,因此,简单地使用最后一层并不准确。
- (2)不同层的嵌入捕获不同的语义。例如,第一层对具有交互的用户和项目实施平滑,第二层平滑在交互的项目(用户)上有重叠的用户(项目),并且较高层捕获较高阶的接近度。因此,将它们结合起来会使表示更全面。
- (3)将不同层的嵌入与加权和相结合与包含自连接的图卷积具有相同效果。
模型预测定义为用户和项目最终表示的内积,作为推荐的排名分数: y ^ u i = e u T e i \hat{y}_{ui}=e_u^Te_i y^ui=euTei
四、模型分析
1.LightGCN矩阵形式
为讨论和其他现在模型的联系,定义LightGCN矩阵形式。
设用户-项目交互矩阵为R∈
R
M
×
N
\Bbb{R}^{M×N}
RM×N,若用户u与项目i有交互则
R
u
i
R_{ui}
Rui为1,否则为0。用户项目图邻接矩阵如下
A
=
(
0
R
R
0
)
A=\begin{pmatrix}\textbf{0}&R\\R&\textbf{0}\end{pmatrix}
A=(0RR0)
设第0层嵌入矩阵为
E
(
0
)
∈
R
(
M
+
N
)
×
T
E^{(0)}∈\Bbb{R}^{(M+N)×T}
E(0)∈R(M+N)×TT为嵌入大小,则LGC矩阵等价形式为
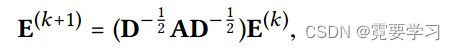
其中,D是一个(M+N)×(M+N)对角矩阵,
D
i
i
D_{ii}
Dii表示邻接矩阵A的第I行向量中非零条目的个数。
用于模型预测的最终嵌入矩阵如下:
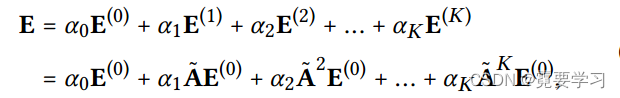
其中
A
=
D
−
1
2
A
D
−
1
2
A=D^{-\frac{1}{2}}AD^{-\frac{1}{2}}
A=D−21AD−21为对称归一化矩阵。
2.与SGCN关系
SGCN的图卷积定义如下:
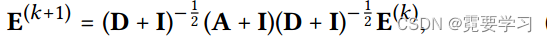
其中,
I
∈
R
(
M
+
N
)
×
(
M
+
N
)
I∈\Bbb{R}^{(M+N)×(M+N)}
I∈R(M+N)×(M+N)为一个单位矩阵,与A相加用于包括自连接,由于
(
D
+
I
)
−
1
2
(D+I)^{-\frac{1}{2}}
(D+I)−21只用于对嵌入进行缩放,为了简单起见,后续分析对其省略。
在SGCN中,最后一层的嵌入被用于下游预测,表示如下:
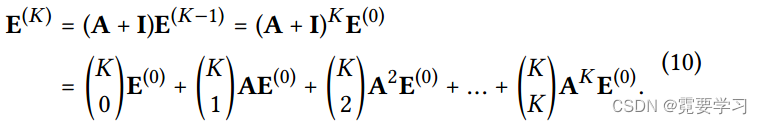
上述推导表明,SGCN的最终嵌入表示形式与LGC类似,即在A中插入自连接并在其上传播嵌入,本质上等价于在每个LGC层传播的嵌入的加权和。
3.与APPNP关系
APPNP是将GCN与个性化PageRank联系起来提出的一个GCN变体,它可以长距离传播且没有过度平滑的风险。受个性化PageRank中的传播设计的启发,APPNP用起始特征,即第0层嵌入补充每个传播层,以平衡保持局部性是其信息靠近根节点来减轻过度平滑,并利用来自大型邻域的信息。APPNP中的传播层定义为:
其中,β表示传输概率,用于控制传播中第0层嵌入的保留。
在APPNP中,最后一层用于最终预测
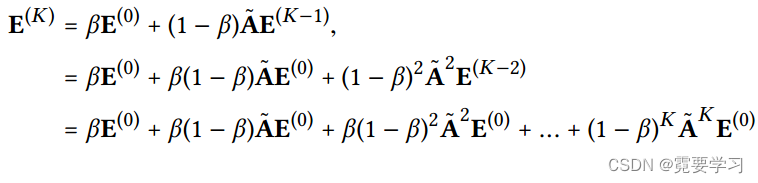
由上述公式推导可知,LightGCN最后一层具有与APPNP相同的形式,因此,LightGCN分享了APPNP在对抗过度平滑方面的优势——通过适当设置α,LightGCN允许使用大型邻域K进行具有可控过度平滑的远程建模。
4.二层嵌入光滑性
为证明LightGCN的合理性,这里分析一个2层的LightGCN。以用户端为例,直观来看,第二层是平滑在交互项目上有重叠的用户,具体如下:
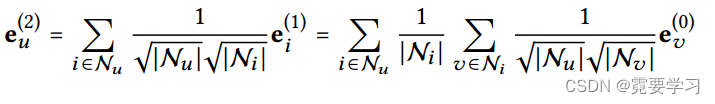
上述推导是将
e
i
(
1
)
e_i^{(1)}
ei(1)的公式带入整理得出。
如果另一个用户v已经与目标用户u进行了交互,则v对u的平滑强度由以下系数(否则为0)来度量:
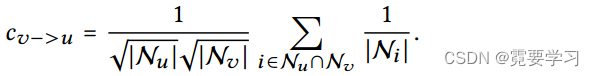
该系数表示二阶邻居v对u的影响,对系数的影响因素如下:
- 共同交互项的数量决定,越多越大;
- 共同交互项的受欢迎程度,受欢迎程度越低(即,更能表明用户的个性化偏好)越大;
- v的活性,活性越低越大.
由于LightGCN的对称公式,项目端会有相同的结论。
5.模型训练要点
- LightGCN的可训练参数只有第0层的嵌入,即 Θ = E ( 0 ) Θ= { E^{(0)}} Θ=E(0),模型复杂度同标准矩阵分解相同;
- 损失函数采用贝叶斯个性化排序(BPR)损失
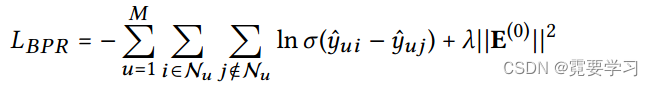
其中λ控制L2正则化强度; - 以小批量方式使用采用Adam优化器,负采样策略可以有所改进;
- 未使用GCN及NGCF中的dropout机制,这使得LightGCN更容易训练和调整;
- 还需要调整两个丢失率(节点丢失和消息丢失),并将每层的嵌入标准化为单位长度;
- 学习层组合参数 { α k } k = 0 K \{α_k\}_{k=0}^K {αk}k=0K,或者用注意力网络将它们参数化,但其最佳设置还需要在以后的工作中探索。
五、实验
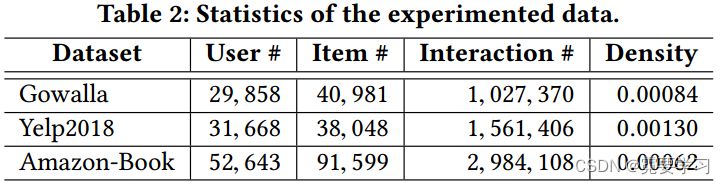
1.数据集
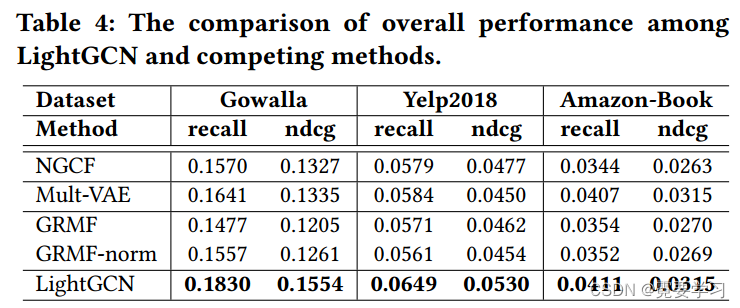
2.效果对比结果
存在的疑问
- 第二层平滑分析中,用户v对u的平滑强度系数如何得来?
- 两个丢失率。
欢迎友友们在评论区提问和交流,如果同为推荐系统研究方向的友友还可以加我的联系方式交流和学习哦,qq1304377062!
原创笔记转载需声明

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









