







机器学习笔记之条件随机场——背景介绍
引言
从本节开始,将介绍条件随机场。本节将从分类模型开始,引出条件随机场的模型性质。
回顾:线性分类
在感知机算法中,第一次介绍线性分类的类型:
硬分类算法(Hard Classification)
硬分类的核心思想是:线性模型在激活函数的映射结果 y p r e d ( i ) y_{pred}^{(i)} ypred(i)的特征空间与真实标签结果 y ( i ) y^{(i)} y(i) 的特征空间相同。以二分类为例,数学符号表示如下:
- 已知数据集合
X
\mathcal X
X,以及对应的真实标签集合
Y
\mathcal Y
Y表示如下:
X = ( x 1 ( 1 ) , x 2 ( 1 ) , ⋯ , x p ( 1 ) x 1 ( 2 ) , x 2 ( 2 ) , ⋯ , x p ( 2 ) ⋮ x 1 ( N ) , x 2 ( N ) , ⋯ , x p ( N ) ) N × p Y = ( y ( 1 ) y ( 2 ) ⋮ y ( N ) ) N × 1 \mathcal X = \begin{pmatrix} x_1^{(1)},x_2^{(1)},\cdots,x_p^{(1)} \\ x_1^{(2)},x_2^{(2)},\cdots,x_p^{(2)} \\ \vdots \\ x_1^{(N)},x_2^{(N)},\cdots,x_p^{(N)} \\ \end{pmatrix}_{N \times p} \mathcal Y = \begin{pmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(N)} \end{pmatrix}_{N \times 1} X=⎝ ⎛x1(1),x2(1),⋯,xp(1)x1(2),x2(2),⋯,xp(2)⋮x1(N),x2(N),⋯,xp(N)⎠ ⎞N×pY=⎝ ⎛y(1)y(2)⋮y(N)⎠ ⎞N×1 - 基于二分类,真实标签结果
y
(
i
)
(
i
=
1
,
2
,
⋯
,
N
)
y^{(i)}(i=1,2,\cdots,N)
y(i)(i=1,2,⋯,N)仅包含
2
2
2个具体结果:
这里用-1,1两个数字分类信息。
y ( i ) ∈ { − 1 , 1 } ( i = 1 , 2 , ⋯ , N ) y^{(i)} \in \{-1,1\} \quad (i=1,2,\cdots,N) y(i)∈{−1,1}(i=1,2,⋯,N) - 硬分类中模型通过样本,对于标签的预测结果
y
p
r
e
d
(
i
)
y_{pred}^{(i)}
ypred(i)与
y
(
i
)
y^{(i)}
y(i)的特征空间 相同:
y p r e d ( i ) , y ( i ) ∈ { − 1 , 1 } ( i = 1 , 2 , ⋯ , N ) y_{pred}^{(i)},y^{(i)} \in \{-1,1\} \quad (i = 1,2,\cdots,N) ypred(i),y(i)∈{−1,1}(i=1,2,⋯,N) - 在线性分类中,
y
p
r
e
d
(
i
)
y_{pred}^{(i)}
ypred(i)的拟合方程(模型)表示如下:
y p r e d ( i ) = s i g n ( W T x ( i ) + b ) y_{pred}^{(i)} = sign(\mathcal W^{T}x^{(i)} + b) ypred(i)=sign(WTx(i)+b)
其中 s i g n sign sign函数表示激活函数(Activation Function),在硬分类中,激活函数通常以分段函数的形式表现出来:
k k k表示某‘具体阈值’。
s i g n ( a ) = { 1 i f a ≥ k − 1 e l s e sign(a) = \begin{cases} 1 \quad if \quad a \geq k \\ -1 \quad else \end{cases} sign(a)={1ifa≥k−1else
满足这种条件的模型,其代表有:
这里仅例举介绍过的模型。
- 线性判别分析(Linear Discriminant Analysis,LDA)
- 感知机算法(Perceptron Algorithm,PLA)
- 支持向量机(Support Vector Machine,SVM)
软分类算法(Soft Classification)
相对于硬分类算法直接比较预测标签与真实标签是否相同,软分类算法的核心思想是:其预测结果并非标签结果,而是概率结果,通过比较不同标签后验概率的大小关系来判定分类类别。
依然以二分类为例,已知某样本
x
(
i
)
x^{(i)}
x(i),该样本条件下关于对应预测标签
y
p
r
e
d
(
i
)
y_{pred}^{(i)}
ypred(i)分别是
−
1
,
1
-1,1
−1,1的后验概率表示如下:
P
(
y
p
r
e
d
(
i
)
=
−
1
∣
x
(
i
)
)
,
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
\mathcal P \left(y_{pred}^{(i)} = -1 \mid x^{(i)}\right),\mathcal P \left(y_{pred}^{(i)} = 1 \mid x^{(i)}\right)
P(ypred(i)=−1∣x(i)),P(ypred(i)=1∣x(i))
软分类思想数学符号表示如下:
{
y
p
r
e
d
(
i
)
=
−
1
i
f
P
(
y
p
r
e
d
(
i
)
=
−
1
∣
x
(
i
)
)
≥
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
y
p
r
e
d
(
i
)
=
1
e
l
s
e
\begin{cases} y_{pred}^{(i)} = -1 \quad if \quad \mathcal P\left(y_{pred}^{(i)} = -1 \mid x^{(i)}\right) \geq \mathcal P\left(y_{pred}^{(i)} =1 \mid x^{(i)}\right) \\ y_{pred}^{(i)} = 1 \quad else \end{cases}
{ypred(i)=−1ifP(ypred(i)=−1∣x(i))≥P(ypred(i)=1∣x(i))ypred(i)=1else
基于不同分类后验的比较思想,软分类思想分别衍生出两种模型:概率判别模型、概率生成模型。
本次针对概率判别模型、概率生成模型的思想描述相比于高斯判别分析(Gaussian Discriminant Analysis)中的描述更加泛化。
概率判别模型
概率判别模型(Probability Discriminant Model)的思想体现在:概率判别模型考虑的是条件概率分布之间的大小关系:
仍然以二分类为例:
P
(
y
p
r
e
d
(
i
)
=
−
1
∣
x
(
i
)
)
↔
?
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
\mathcal P \left(y_{pred}^{(i)} = -1 \mid x^{(i)}\right) \overset{\text{?}}{\leftrightarrow}\mathcal P \left(y_{pred}^{(i)} = 1 \mid x^{(i)}\right)
P(ypred(i)=−1∣x(i))↔?P(ypred(i)=1∣x(i))
基于该思想的典型模型是逻辑回归(Logistic Regression)。逻辑回归的特点在于直接将条件概率结果求解出来,并进行比较。逻辑回归使用连续激活函数描述样本点
x
(
i
)
x^{(i)}
x(i)与条件概率
P
(
y
p
r
e
d
(
i
)
)
\mathcal P(y_{pred}^{(i)})
P(ypred(i))之间的关系:
‘逻辑回归’只是二分类的判别方式,而基于多分类的判别方式被称为softmax Regression。
P
(
y
p
r
e
d
(
i
)
∣
x
(
i
)
)
=
s
i
g
m
o
i
d
(
W
T
x
(
i
)
+
b
)
=
1
1
+
e
−
(
W
T
x
(
i
)
+
b
)
\begin{aligned} \mathcal P(y_{pred}^{(i)} \mid x^{(i)}) & = sigmoid(\mathcal W^{T}x^{(i)} +b) \\ & = \frac{1}{1 + e^{-\left(\mathcal W^{T}x^{(i)} + b\right)}} \end{aligned}
P(ypred(i)∣x(i))=sigmoid(WTx(i)+b)=1+e−(WTx(i)+b)1
对应两种条件概率结果表示如下:
{
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
=
1
1
+
e
−
(
W
T
x
(
i
)
+
b
)
P
(
y
p
r
e
d
(
i
)
=
−
1
∣
x
(
i
)
)
=
1
−
1
1
+
e
−
(
W
T
x
(
i
)
+
b
)
=
e
−
(
W
T
x
(
i
)
+
b
)
1
+
e
−
(
W
T
x
(
i
)
+
b
)
\begin{cases} \mathcal P(y_{pred}^{(i)} = 1 \mid x^{(i)}) = \frac{1}{1 + e^{-\left(\mathcal W^{T}x^{(i)} + b\right)}} \\ \mathcal P(y_{pred}^{(i)} = -1 \mid x^{(i)}) = 1 - \frac{1}{1 + e^{-\left(\mathcal W^{T}x^{(i)} + b\right)}} = \frac{e^{-\left(\mathcal W^{T}x^{(i)} + b\right)}}{1 + e^{-\left(\mathcal W^{T}x^{(i)} + b\right)}} \end{cases}
⎩
⎨
⎧P(ypred(i)=1∣x(i))=1+e−(WTx(i)+b)1P(ypred(i)=−1∣x(i))=1−1+e−(WTx(i)+b)1=1+e−(WTx(i)+b)e−(WTx(i)+b)
最终通过求解模型参数
W
,
b
\mathcal W,b
W,b来确定条件概率之间的大小关系。
在最大熵原理与softmax激活函数关系中介绍过,sigmoid函数,softmax函数它不仅仅是激活函数,并且它们均是指数族分布,并且这两种分布是满足对应条件下熵最大的分布:
基于数据集合 X \mathcal X X中各样本特征使用经验概率分布(Empirical Probability Distribution);
经验概率分布是表达‘给定已知事实’的形式。对已知数据通过‘统计’的方式表示概率分布结果。
其中x i x_i xi表示数据的k k k种离散表示,可以看成k k k种离散的标签结果,而标签对应的概率表示如下:
P ^ ( x ( j ) = x i ) = c o u n t ( x i ) N { x ( i ) ∈ X i = 1 , 2 , ⋯ , k \hat P(x^{(j)} = x_i) = \frac{count(x_i)}{N} \quad \begin{cases}x^{(i)} \in \mathcal X \\ i = 1,2,\cdots,k\end{cases} P^(x(j)=xi)=Ncount(xi){x(i)∈Xi=1,2,⋯,k
其中sigmoid函数表示的 k = 2 k = 2 k=2,而softmax表示 k ≥ 2 k \geq2 k≥2,sigmoid函数是softmax函数在二分类下的特殊表示:
s i g m o i d ( x ) = 1 1 + e − x = e 0 e 0 + e − x \begin{aligned}sigmoid(x) & = \frac{1}{1 + e^{-x}} \\ & = \frac{e^0}{e^0 + e^{-x}}\end{aligned} sigmoid(x)=1+e−x1=e0+e−xe0
因此,同样可以从 最大熵模型 的角度去理解逻辑回归模型。
概率生成模型
相比于概率判别模型,概率生成模型(Probability Generation Model)的思想体现在:并不直接针对条件概率进行求解,而是通过联合概率分布的大小关系来表示条件概率的大小关系。
其中
P
(
x
(
i
)
)
\mathcal P(x^{(i)})
P(x(i))是关于
x
(
i
)
x^{(i)}
x(i)的边缘概率分布。和
y
p
r
e
d
(
i
)
y_{pred}^{(i)}
ypred(i)无关,可视作常数。
依然以二分类为例,使用条件概率公式将
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
\mathcal P(y_{pred}^{(i)} =1 \mid x^{(i)})
P(ypred(i)=1∣x(i))展开成如下形式:
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
=
P
(
y
p
r
e
d
(
i
)
=
1
,
x
(
i
)
)
P
(
x
(
i
)
)
∝
P
(
y
p
r
e
d
(
i
)
=
1
,
x
(
i
)
)
=
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
⋅
P
(
x
(
i
)
)
\begin{aligned} \mathcal P(y_{pred}^{(i)} =1\mid x^{(i)}) & = \frac{\mathcal P(y_{pred}^{(i)} =1, x^{(i)})}{\mathcal P(x^{(i)})} \\ & \propto \mathcal P(y_{pred}^{(i)} =1, x^{(i)}) \\ & = \mathcal P(y_{pred}^{(i)} =1 \mid x^{(i)}) \cdot \mathcal P(x^{(i)}) \end{aligned}
P(ypred(i)=1∣x(i))=P(x(i))P(ypred(i)=1,x(i))∝P(ypred(i)=1,x(i))=P(ypred(i)=1∣x(i))⋅P(x(i))
最终通过比较
P
(
y
p
r
e
d
(
i
)
=
1
,
x
(
i
)
)
\mathcal P(y_{pred}^{(i)} =1, x^{(i)})
P(ypred(i)=1,x(i))和
P
(
y
p
r
e
d
(
i
)
=
−
1
,
x
(
i
)
)
\mathcal P(y_{pred}^{(i)} =-1, x^{(i)})
P(ypred(i)=−1,x(i))之间的大小关系来描述条件概率的大小关系:
P
(
y
p
r
e
d
(
i
)
=
1
∣
x
(
i
)
)
⇔
?
P
(
y
p
r
e
d
(
i
)
=
−
1
∣
x
(
i
)
)
⇓
P
(
x
(
i
)
,
y
p
r
e
d
(
i
)
=
1
)
⇔
?
P
(
x
(
i
)
,
y
p
r
e
d
(
i
)
=
−
1
)
\mathcal P(y_{pred}^{(i)} = 1 \mid x^{(i)}) \overset{\text{?}}{\Leftrightarrow} \mathcal P(y_{pred}^{(i)} = -1 \mid x^{(i)})\\ \Downarrow \\ \mathcal P(x^{(i)},y_{pred}^{(i)} = 1) \overset{\text{?}}{\Leftrightarrow} \mathcal P(x^{(i)},y_{pred}^{(i)} = -1)
P(ypred(i)=1∣x(i))⇔?P(ypred(i)=−1∣x(i))⇓P(x(i),ypred(i)=1)⇔?P(x(i),ypred(i)=−1)
从宏观角度观察,未知变量的后验概率有时可能很难求解,因而需要使用推断(Inference):通过已知变量推测未知变量的条件概率分布。
说远了~
常见的概率生成模型,如概率图模型系列:
最大熵马尔可夫模型
隐马尔可夫模型的缺陷
首先,隐马尔可夫模型本身是概率生成模型。在介绍隐马尔可夫模型的解码问题时,并没有对单一隐变量的后验概率进行求解,而是通过维特比算法(Viterbi)找出关于隐变量 联合概率分布之间的关联关系,从而求解出迭代关系式:
δ
t
(
k
)
=
max
i
1
,
⋯
,
i
t
−
1
P
(
o
1
,
⋯
,
o
t
,
i
1
,
⋯
,
i
t
=
q
k
∣
λ
)
δ
t
+
1
(
j
)
=
max
i
1
,
⋯
,
i
t
P
(
o
1
,
⋯
,
o
t
+
1
,
i
1
,
⋯
,
i
t
+
1
=
q
j
∣
λ
)
δ
t
=
1
(
j
)
=
δ
t
(
k
)
⋅
a
k
j
⋅
b
j
(
o
t
+
1
)
\begin{aligned} \delta_{t}(k) & = \mathop{\max}\limits_{i_1,\cdots,i_{t-1}} \mathcal P(o_1,\cdots,o_t,i_1,\cdots,i_t = q_k \mid \lambda) \\ \delta_{t+1}(j) & = \mathop{\max}\limits_{i_1,\cdots,i_t} \mathcal P(o_1,\cdots,o_{t+1},i_1,\cdots,i_{t+1} = q_j \mid \lambda) \\ \delta_{t=1}(j) & = \delta_t{(k)} \cdot a_{kj} \cdot b_{j}(o_{t+1}) \end{aligned}
δt(k)δt+1(j)δt=1(j)=i1,⋯,it−1maxP(o1,⋯,ot,i1,⋯,it=qk∣λ)=i1,⋯,itmaxP(o1,⋯,ot+1,i1,⋯,it+1=qj∣λ)=δt(k)⋅akj⋅bj(ot+1)
由于隐马尔可夫模型的隐状态是离散型随机变量,因此:
- q k , q j ∈ Q q_k,q_j \in \mathcal Q qk,qj∈Q, Q \mathcal Q Q表示隐状态可选择的离散值集合;
- a k j a_{kj} akj表示状态转移矩阵 A \mathcal A A中 i t = q k i_t = q_k it=qk行, i t + 1 = q j i_{t+1} = q_j it+1=qj列对应的转移概率结果;
-
b
j
(
o
t
+
1
)
b_j(o_{t+1})
bj(ot+1)表示发射矩阵
B
\mathcal B
B中
i
t
+
1
=
q
j
i_{t+1} = q_j
it+1=qj行,
o
t
+
1
o_{t+1}
ot+1列对应的发射概率结果。
这里为简化计算,将观测变量也设置为‘离散型随机变量’。
隐马尔可夫模型的第一个缺陷在于:针对维特比算法,在求解最优隐状态序列的过程中,不得不求解各时刻隐状态取值对应的联合概率分布,并从中挑选出各时刻最优的联合概率分布。而联合概率分布求解过程并不容易,因此提高了计算代价。
隐马尔可夫模型的另一个缺陷在于:观测独立性假设。该假设定义某时刻的观测变量只与该时刻的隐变量相关,与其他变量无关:
P
(
o
t
∣
o
1
,
⋅
o
t
−
1
,
i
1
,
⋯
,
i
t
)
=
P
(
o
t
∣
i
t
)
\mathcal P(o_t \mid o_1,\cdot o_{t-1},i_1,\cdots,i_{t}) = \mathcal P(o_t \mid i_t)
P(ot∣o1,⋅ot−1,i1,⋯,it)=P(ot∣it)
但在真实环境中,某一个观测变量结果,可能并非由一个隐变量决定的,而是由多个时刻的隐状态共同决定的。因而,隐马尔可夫模型的假设过强,缺乏灵活性。
最大熵马尔可夫模型介绍
最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)本身是概率判别模型:对隐状态
I
\mathcal I
I和观测变量
O
\mathcal O
O的条件概率进行建模。
相比于隐马尔可夫模型,它最大的特点是抛弃了观测独立性假设,并且考虑到各时刻观测变量之间的关联关系:
P
(
I
∣
O
)
=
∏
t
=
1
T
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
\mathcal P(\mathcal I \mid \mathcal O) = \prod_{t=1}^{T} \mathcal P(i_t \mid i_{t-1},o_{1:T})
P(I∣O)=t=1∏TP(it∣it−1,o1:T)
对于每一个条件概率结果
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
(
t
=
1
,
⋯
,
T
)
\mathcal P(i_t \mid i_{t-1},o_{1:T}) (t=1,\cdots,T)
P(it∣it−1,o1:T)(t=1,⋯,T)通过最大熵模型(Maximum Entropy Model)进行建模。在最大熵原理与指数族分布关系中介绍过:概率分布存在约束条件的情况下,满足约束条件下熵最大的分布就是指数族分布:
Z
\mathcal Z
Z又称‘配分函数’,可以看成‘归一化因子’;
h
(
x
)
h(x)
h(x)是关于
x
x
x的函数,通常以常数形式出现。
P
(
x
)
=
h
(
x
)
⋅
e
λ
T
f
(
x
)
−
A
(
λ
)
=
h
(
x
)
Z
e
λ
T
f
(
x
)
(
Z
=
e
A
(
λ
)
)
\begin{aligned} \mathcal P(x) & = h(x) \cdot e^{\lambda^{T}f(x) - \mathcal A(\lambda)} \\ & = \frac{h(x)}{\mathcal Z} e^{\lambda^{T}f(x)} \quad (\mathcal Z = e^{\mathcal A(\lambda)}) \end{aligned}
P(x)=h(x)⋅eλTf(x)−A(λ)=Zh(x)eλTf(x)(Z=eA(λ))
因此,针对每一时刻的后验结果:
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
\mathcal P(i_t \mid i_{t-1},o_{1:T})
P(it∣it−1,o1:T) 具体公式表示如下:
该公式不仅是‘最大熵模型’中的概率分布公式,同时也是‘指数族分布’中的概率分布公式。
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
=
1
Z
(
o
1
:
T
,
i
t
−
1
)
e
λ
a
T
f
a
(
o
1
:
T
,
i
t
,
i
t
−
1
)
=
1
Z
(
o
1
:
T
,
i
t
−
1
)
exp
[
∑
a
λ
a
f
a
(
o
1
:
T
,
i
t
,
i
t
−
1
)
]
\begin{aligned} \mathcal P(i_t \mid i_{t-1},o_{1:T}) & = \frac{1}{\mathcal Z(o_{1:T},i_{t-1})} e^{\lambda_a^{T}f_a(o_{1:T},i_t,i_{t-1})}\\ & = \frac{1}{\mathcal Z(o_{1:T},i_{t-1})} \exp\left[{\sum_{a} \lambda_af_a(o_{1:T},i_{t},i_{t-1})}\right] \end{aligned}
P(it∣it−1,o1:T)=Z(o1:T,it−1)1eλaTfa(o1:T,it,it−1)=Z(o1:T,it−1)1exp[a∑λafa(o1:T,it,it−1)]
其中, Z ( o 1 : T , i t − 1 ) \mathcal Z(o_{1:T},i_{t-1}) Z(o1:T,it−1)是关于观测变量 o 1 : T o_{1:T} o1:T与过去时刻隐状态 i t − 1 i_{t-1} it−1的归一化函数; a a a表示特征集合,该集合中包含若干个特征对(pairs) < b , i t > \text{<}b,i_t\text{>} <b,it>。 b b b被称为 观测特征(Feature of Observation);而 i t i_t it自然是目标状态(D)。 f a ( o t , i t ) f_a(o_t,i_t) fa(ot,it)表示特征函数(Feature Function)——对观测变量 o 1 : T o_{1:T} o1:T与目标状态 i t i_t it的某一事实进行描述。
示例:已知特征对表示如下:
<Is-capitalized,Company>
\text{<Is-capitalized,Company>}
<Is-capitalized,Company>
通过该特征对发现:不仅给出了目标状态(Company),并给出了规则:要求上一时刻隐状态给出的词汇是大写的(首字母大写)。
基于该规则,构建特征函数(Feature Function):
f
<b,i>
(
o
t
,
i
t
)
=
{
1
b
(
o
t
)
=
T
r
u
e
;
i
=
i
t
0
o
t
h
e
r
w
i
s
e
f_{\text{<b,i>}}(o_t,i_t) = \begin{cases} 1 \quad b(o_t) = True;i=i_t \\ 0 \quad otherwise \end{cases}
f<b,i>(ot,it)={1b(ot)=True;i=it0otherwise
假设给
o
t
o_t
ot一个单词:
Microsoft
\text{Microsoft}
Microsoft(微软),
i
t
i_t
it依然给
Company
\text{Company}
Company(公司)。此时:
Microsoft
\text{Microsoft}
Microsoft是首字母大写的单词,并且
i
t
=
i
=
C
o
m
p
a
n
y
i_t = i = Company
it=i=Company,针对特征函数的条件,特征函数
f
<b,i>
(
o
t
,
i
t
)
f_{\text{<b,i>}}(o_t,i_t)
f<b,i>(ot,it)返回结果1.
f
<Is-capitalized,Company>
(
Apple,Company
)
=
1
f_{\text{<Is-capitalized,Company>}}(\text{Apple,Company}) = 1
f<Is-capitalized,Company>(Apple,Company)=1
对应的最大熵结果自然高于
f
=
0
f=0
f=0的结果。
该示例是‘寻找表示公司名字单词’的一个示例,它制定的规则很简单,只要满足首字母大写,并且该词后面是“公司”,该词就满足“是公司名字的条件”。传送门
最终,通过最大熵模型表示
P
(
I
∣
O
)
\mathcal P(\mathcal I \mid \mathcal O)
P(I∣O)表示如下:
从该表示可以看出,它保留了‘齐次马尔可夫假设’。
P
(
I
∣
O
)
=
∏
t
=
1
T
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
=
∏
t
=
1
T
e
x
p
(
∑
a
λ
a
f
a
(
i
t
,
i
t
−
1
,
o
1
:
T
)
)
Z
(
i
t
−
1
,
o
1
:
T
)
\begin{aligned} \mathcal P(\mathcal I \mid \mathcal O) & = \prod_{t=1}^{T} \mathcal P(i_t \mid i_{t-1},o_{1:T}) \\ & = \prod_{t=1}^{T} \frac{exp(\sum_a \lambda_af_a(i_t,i_{t-1},o_{1:T}))}{\mathcal Z(i_{t-1},o_{1:T})} \end{aligned}
P(I∣O)=t=1∏TP(it∣it−1,o1:T)=t=1∏TZ(it−1,o1:T)exp(∑aλafa(it,it−1,o1:T))
基于公式的表示过程,MEMM的概率图模型表示如下:

这是从狭义角度对MEMM模型进行描述。从图中观察,它删除了观测独立性假设,使得各时刻的观测变量之间存在关联关系。
观察任意一个
V
\mathcal V
V型结构,仍然以一阶齐次马尔可夫模型为例,
t
t
t时刻的隐状态
i
t
i_t
it(未知状态下)与相互独立的变量
o
t
o_t
ot和
i
t
−
1
i_{t-1}
it−1相关联:
P
(
i
t
∣
i
t
−
1
,
o
t
)
i
t
−
1
⊥
o
t
\mathcal P(i_t \mid i_{t-1},o_t) \quad i_{t-1} \perp o_t
P(it∣it−1,ot)it−1⊥ot
但实际上,这种狭义的模型假设对于观测变量
o
1
:
T
o_{1:T}
o1:T仍然过强,如序列标注过程中,某一时刻词语的标注结果不仅和过去的前一个词相关联,而是可能与前若干个词语甚至是整个句子序列都有关联。这种假设相比上述狭义假设更加合理。因此,广义角度的MEMM模型表示如下:
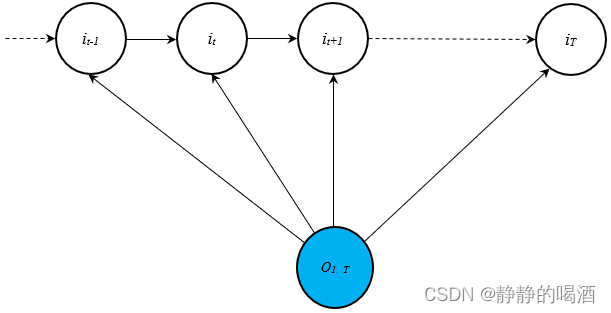
这种概率图表示彻底打破了观测变量相互独立的条件,更符合最大熵模型对于
P
(
i
t
∣
i
t
−
1
,
o
1
:
T
)
\mathcal P(i_t \mid i_{t-1},o_{1:T})
P(it∣it−1,o1:T)的描述。
下一节将介绍隐马尔可夫模型(HMM)到最大熵马尔可夫模型(MEMM)的转化过程。
















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











