







引言
从本节开始,将介绍生成模型的相关概念。
生成模型介绍
生成模型,单从名字角度,可以将其认识为:生成样本的模型。从流程的角度,它可以理解为:
- 给定一个数据集合,基于该数据集合进行建模,并通过数据集合学习出模型的参数信息;
- 根据已学习出的参数信息,使用模型构建出新的数据。
但生成新的数据仅是生成模型的一个任务/目标,通过生成新数据的模型对生成模型进行判别可能是很片面的。
例如之前介绍的高斯混合模型( Gaussain Mixture Model,GMM \text{Gaussain Mixture Model,GMM} Gaussain Mixture Model,GMM),它的概率图结构可表示为:
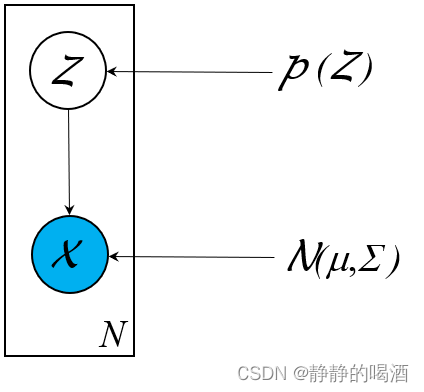
其中 Z \mathcal Z Z是一个一维、离散型随机变量,对应的 X ∣ Z \mathcal X \mid \mathcal Z X∣Z服从高斯分布:
Z ∼ Discrete Distribution ( 1 , 2 , ⋯ , K ) X ∣ Z ∼ N ( μ k , Σ k ) k ∈ { 1 , 2 , ⋯ , K } \begin{aligned} \mathcal Z & \sim \text{Discrete Distribution}(1,2,\cdots,\mathcal K) \\ \mathcal X \mid \mathcal Z & \sim \mathcal N(\mu_{k},\Sigma_k) \quad k \in \{1,2,\cdots,\mathcal K\} \end{aligned} ZX∣Z∼Discrete Distribution(1,2,⋯,K)∼N(μk,Σk)k∈{
1,2,⋯,K}
只要能够确定隐变量 Z \mathcal Z Z的概率分布 P Z \mathcal P_{\mathcal Z} PZ,以及高斯分布参数 ( μ Z , Σ Z ) (\mu_{\mathcal Z},\Sigma_{\mathcal Z}) (μZ,ΣZ),就可以从概率模型中源源不断生成出样本:
这里 μ Z , Σ Z , P Z \mu_{\mathcal Z},\Sigma_{\mathcal Z},\mathcal P_{\mathcal Z} μZ,ΣZ,PZ均表示模型参数。
{ ∀ z ( i ) ∈ Z z ( i ) ∼ P z ( i ) x ( i ) ∣ z ( i ) ∼ N ( μ z ( i ) , Σ z ( i ) ) \begin{cases} \forall z^{(i)} \in \mathcal Z \\ z^{(i)} \sim \mathcal P_{z^{(i)}}\\ x^{(i)} \mid z^{(i)} \sim \mathcal N(\mu_{z^{(i)}},\Sigma_{z^{(i)}}) \end{cases} ⎩
⎨
⎧∀z(i)∈Zz(i)∼Pz
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











