









 文章详细比较了Garnet架构的x86-MoeshiHammer在Parsec基准测试中的仿真指令数(simInsts)和simOps,以及与ARM和gem5教程的性能对比。此外,还提供了CPU的IPC和CPI指标。
文章详细比较了Garnet架构的x86-MoeshiHammer在Parsec基准测试中的仿真指令数(simInsts)和simOps,以及与ARM和gem5教程的性能对比。此外,还提供了CPU的IPC和CPI指标。
常用的结果1:仿真指令数 simInst
不影响结果,只是跑的慢一点,花地球时间花的久一点才进系统。
下面是我们运行的代码,然后我们来看stat.txt
cd /home/gem5/parsec-benchmark; source env.sh; parsecmgmt -a run -p blackscholes -c gcc-hooks -i simsmall -n 2; sleep 5; m5 exit;
模拟运行了11.6s,我们的simInsts 仿真指令数是3,710,533,377,也就是3.7x1e9.
地球时间花了 11577.30 s,也就是192分钟,3个小时多。
我们的simOps 仿真操作数是 7659803667也就是 7.7x1e9.
--------- Begin Simulation Statistics ----------
simSeconds 11.651543 # Number of seconds simulated (Second)
simTicks 11,651,542,566,501 # Number of ticks simulated (Tick)
finalTick 11651542566501 # Number of ticks from beginning of simulation (restored from checkpoints and never reset) (Tick)
simFreq 1000,000,000,000 # The number of ticks per simulated second ((Tick/Second))
hostSeconds 11577.30 # Real time elapsed on the host (Second)
hostTickRate 1006412843 # The number of ticks simulated per host second (ticks/s) ((Tick/Second))
hostMemory 17317040 # Number of bytes of host memory used (Byte)
simInsts 3710533377 # Number of instructions simulated (Count)
simOps 7659803667 # Number of ops (including micro ops) simulated (Count)
hostInstRate 320501 # Simulator instruction rate (inst/s) ((Count/Second))
hostOpRate 661623 # Simulator op (including micro ops) rate (op/s) ((Count/Second))
很多文章不喜欢给绝对值,但我还是努力找了一些。
作为对比,看看arm rsk给的结果。用的simsmall, 模拟的2-core 4Ghz ,花了2x1e9。
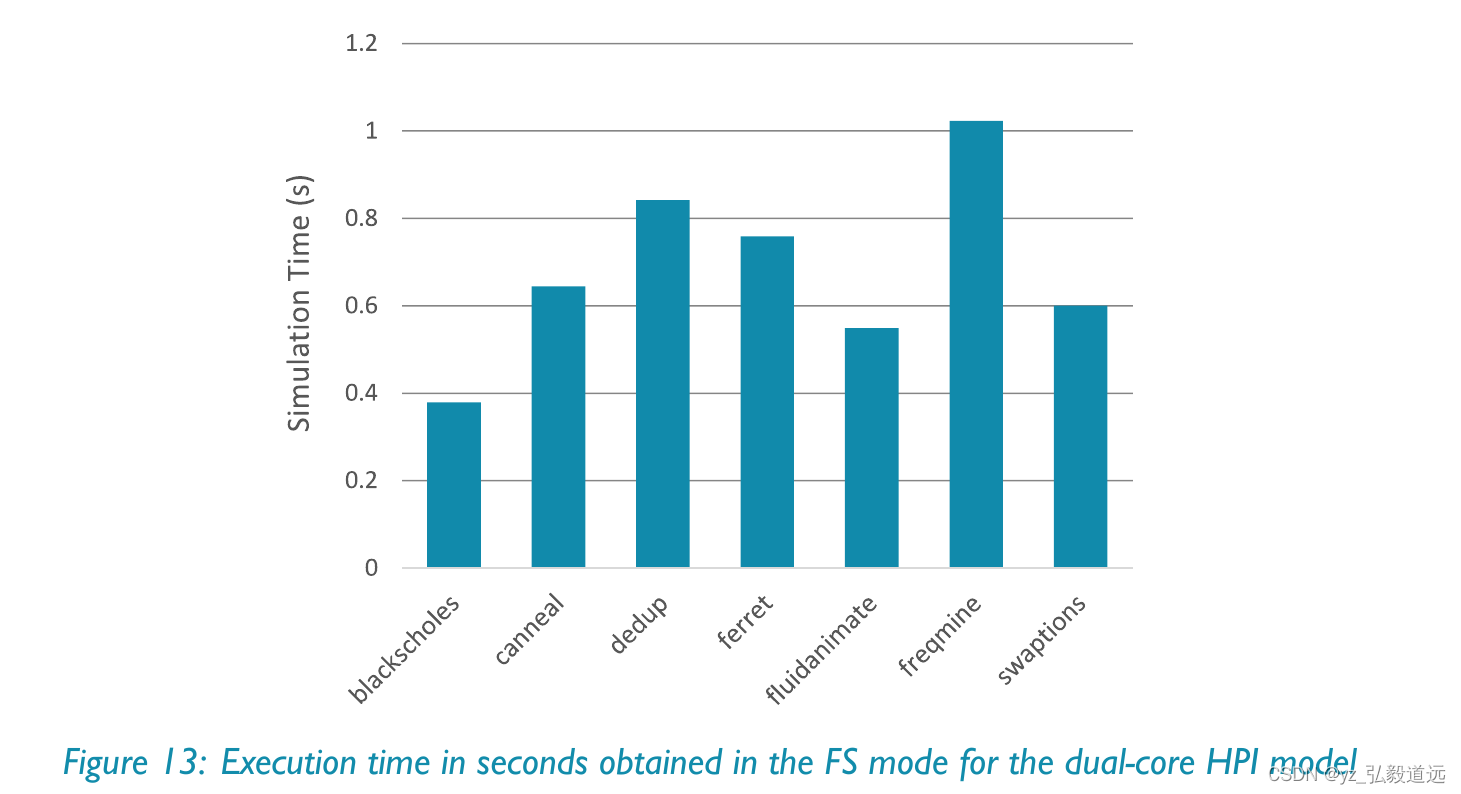
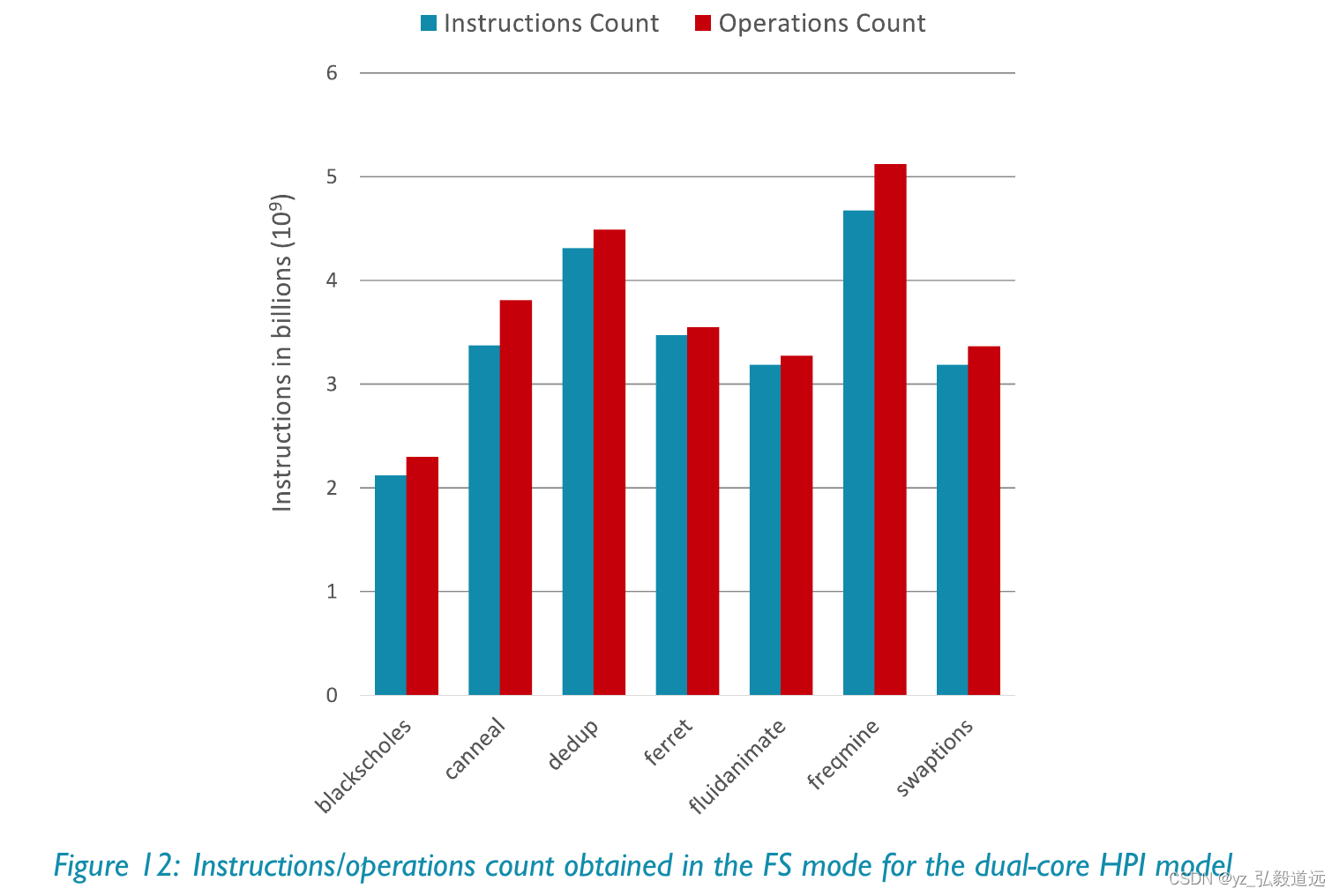
如果是gem5 的教程,用了一堆gem5art的,单核跑blackscholes,simsmall是 ~4x1e3 million=4x1e9。

作为对比,我们的用了garnet的x86-moeshi hammer是3.7x1e9的指令,gem5教程的x86用的是看上去4x1e9的指令,arm的则用了2x1e9多一点。
常用的结果1:仿真时间 simSeconds
gem5 parsec教程用的无garnet的cpu,仿真时间是0.2s左右。作为对比,我们的是11.6左右。
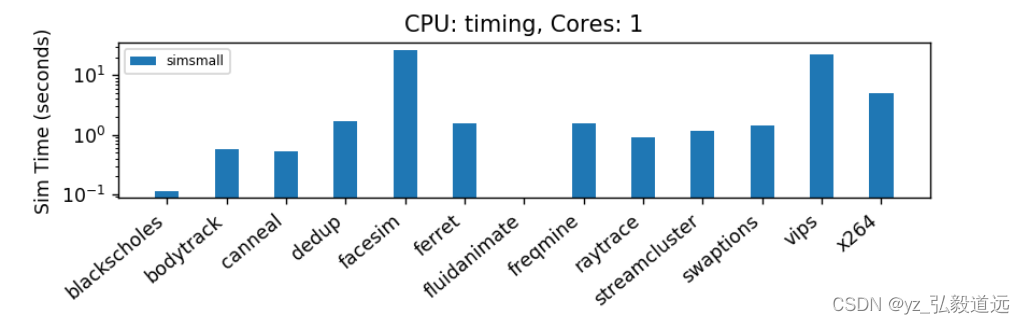
其他结果: IPC
我们的IPC结果是0.053,0.024,0.043,0.038。其中cpu1的ipc很低,可以留待以后观察。
system.cpu0.commitStats0.cpi 18.805689 # CPI: cycles per instruction (thread level) ((Cycle/Count))
system.cpu0.commitStats0.ipc 0.053175 # IPC: instructions per cycle (thread level) ((Count/Cycle))
system.cpu1.cpi 41.318331 # CPI: cycles per instruction (core level) ((Cycle/Count))
system.cpu1.ipc 0.024202 # IPC: instructions per cycle (core level) ((Count/Cycle))
system.cpu2.cpi 22.875346 # CPI: cycles per instruction (core level) ((Cycle/Count))
system.cpu2.ipc 0.043715 # IPC: instructions per cycle (core level) ((Count/Cycle))
system.cpu3.commitStats0.cpi 26.217850 # CPI: cycles per instruction (thread level) ((Cycle/Count))
system.cpu3.commitStats0.ipc 0.038142 # IPC: instructions per cycle (thread level) ((Count/Cycle))

















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









