









1.概念
1.1 时间上的并行技术/流水线技术
将一个任务划分为几个不同的阶段,每个阶段在不同部件上并行执行,这样就可以在同一时刻中执行多个任务。
1.2 空间上的并行技术
在同一个处理机内,设置多个执行相同任务的功能部件,并让这些部件并行执行。这样的处理机也叫超标量处理机。
1.3 指令流水线

这里将指令划分为了五个子阶段:
- 取指(IF):从IR/Cache中取出指令。
- 译码/读寄存器(ID):操作控制器对指令进行译码,同时从寄存器堆中取操作数。
- 执行/计算地址(EX):执行运算操作或计算地址。
- 访存(MEM):对存储器进行读写操作。
- 写回(WB):将指令结果写回寄存器堆。
1.3.1 设计原则
以最复杂指令的所用的功能段个数作为指令流水线段个数,以最复杂的操作所需的时间作为流水段长度。
1.3.2 特征
- 指令长度一致,有助于简化取指和译码操作。
- 指令格式规整,尽量保证源寄存器相同,便于在不取指的情况下便可取到操作数。
- 只采用Load/Store指令来访问存储器,可将访存操作单独抽离到一个周期中,有利于简化操作步骤。
- 数据和指令对齐存放,有助于减少访存次数。
注意,流水线技术并不能缩短单指令的执行时间,但对于整个程序来说,效率得到了大幅度的提升。
1.3.3 表示方法

2.基本实现
2.1 数据通路
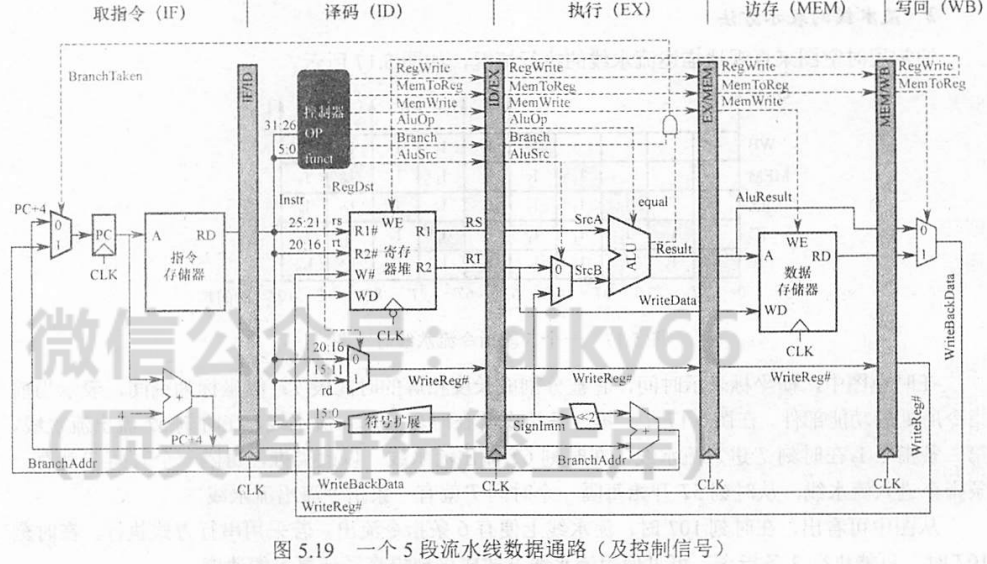
- 每个流水段后面都需要加一个流水线寄存器,用于锁存本段处理完成的数据和控制信号,以保证本段的执行结果能够被下一流水段使用。
- 各种寄存器和数据存储器均采用统一时钟控制,每发出一个CLK信号,就会有一条指令进入IF段。
- 不同流水寄存器锁存的数据不同:IF-ID流水寄存器锁存的是指令字和PC+4的值;ID-EX流水寄存器锁存的是操作数、PC+4的值、写寄存器编号等后段可能会用到的数据;EX-MEM流水寄存器所存的是执行结果、待写入存储器的数据、写寄存器编号等数据;MEM-WB流水寄存器锁存的是ALU运算结果、存储器读出的数据、写寄存器编号。
- 流水线寄存器锁存的信息包括:指令字、PC+“1”后的值、立即数、目的寄存器、ALU运算结果、标志信息等前段执行后得到的数据结果+控制信号。
2.2 控制信号

- 控制信号的来源并不一致,大部分来源于ID段控制器译码后产生的控制信号。
- 前段的控制信号可来自于后段。
2.3 执行过程
取指(IF)
通过取指部件以PC作为指令地址从指令寄存器中取出指令字,PC+“1“,在CLK信号到来时,将指令字和PC变化后的值通过RD输出端送入IF-ID流水寄存器中,同时本条指令进入ID段,IF段开始取下一条指令。
译码/读寄存器(ID)
由控制器根据IF-ID流水寄存器生成后续各段所需的控制信号。
执行/计算地址(EX)
EX段功能由具体指令决定,不同指令经ID段译码后得到的控制信号不同。
访存(MEM)
MEM段的功能也由具体指令决定。
写回(WB)
WB段的功能也由具体指令决定。
2.流水线的冒险与处理
2.1 结构冒险/资源冲突
2.1.1 说明
硬件资源竞争造成的冲突,即同一时刻有多条指令争用同一资源而形成的冲突。
2.1.2 解决
- 前一条指令访存时,后一条指令延后一个时钟周期。
- 单独设置数据存储器和指令存储器,使取数和取指在不同的存储器中进行。
现在计算机通过引入Cache机制,其中L1Cache就划分为数据Cache和指令Cache,从而避免了结构冒险这一问题。
2.2 数据冒险
2.2.1 说明
多条指令重叠处理同一数据产生的冲突。
2.2.2 分类
写后读(Read After Write,RAW)
只有当前指令将数据写入寄存器中后,下条指令才能够从该寄存器中读取。否则,先读后写,读到的是旧数据。
读后写(Write After Read,WAR)
只有当前指令读取出数据后,下条指令才能往寄存器中写数据。否则,先写后读,读到的是新数据。
写后写(Write After Write,WAW)
只有当前指令写入数据到寄存器后,下条指令才能写入该寄存器。否则,下条指令先于当前指令写,会使得当前指令写之前该寄存器的值不是真正的值。
2.2.3 解决
- 将涉嫌数据相关的指令全部延后一个或多个时钟周期,直至数据冒险的情况消失。有 硬件堵塞(stall)和软件插入NOP指令 两种方法。


- 设置相关专用通路(数据旁路技术)。不再读取寄存器组,也不再等待前一条指令计算完成后将结果写回寄存器组,而是直接把前一条指令的ALU计算结果作为下条指令的数据输入。
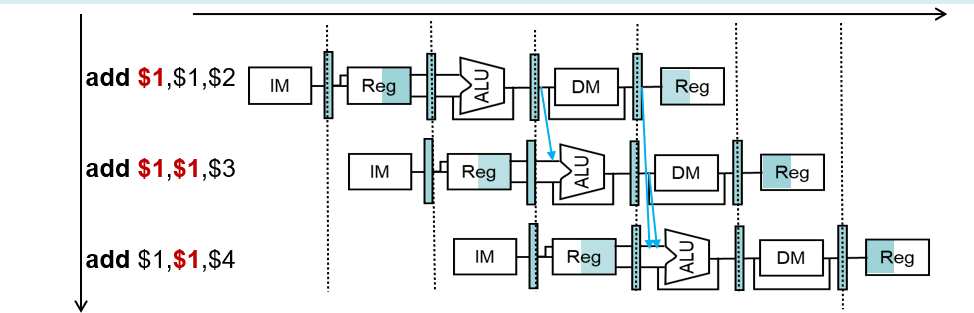
- 通过编译器对数据相关的指令进行编译优化,调整指令顺序以解决数据冒险问题。
2.3 控制冒险
2.3.1 说明
通常情况下,程序是顺序执行的,但是遇到转移类指令时,会通过改变PC值使得流水线断流。
2.3.2 解决
- 对转移类指令进行分支预测,尽早生成转移目标地址。分支预测分为简单(静态)预测与动态预测。
- 静态预测总是认定转移条件不满足,继续执行分支指令的后续指令。
- 动态预测则根据程序历史执行情况,进行动态预测调整,有较高的预测准确率。
- 预取转移成功与转移不成功两个方向上的目标指令。
- 加快和提前形成条件码。
- 提高转移方向上的猜准率。。。
3.流水线的性能指标
3.1 吞吐率
3.1.1 说明
单位时间内流水线所完成的任务数量或输出的结果数量。
3.1.2 公式
基本公式:
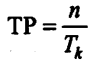
其中,n为任务数,Tk是处理完n个任务所需的时间。
任务连续的情况下,流水线的吞吐率公式:

其中,k为流水线段数,Δt为时钟周期。

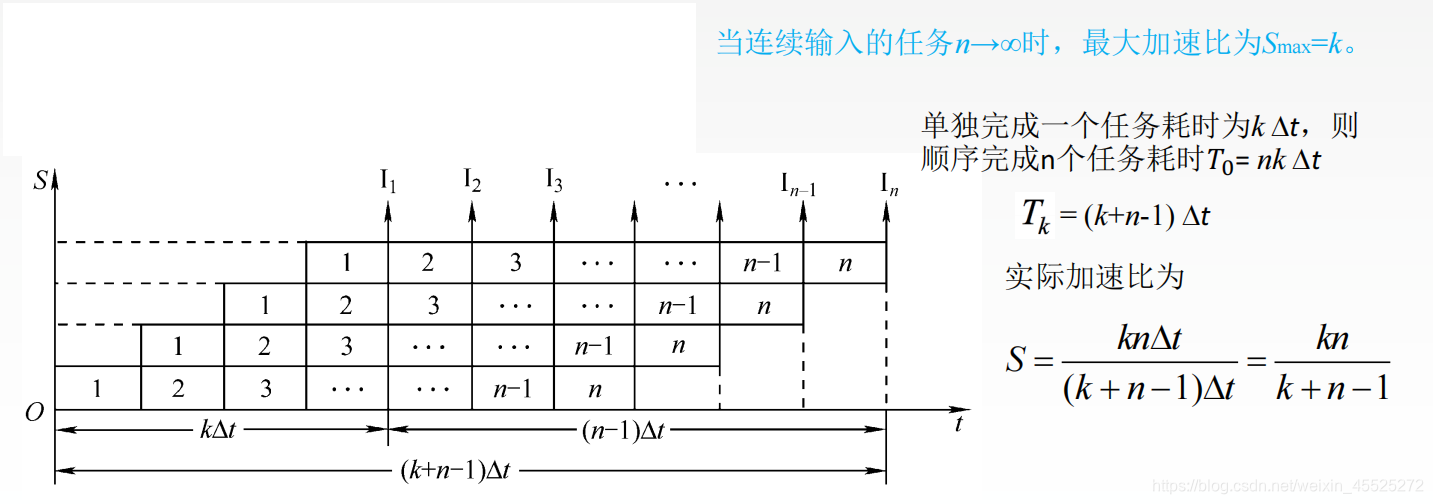
3.2 加速比
3.2.1 说明
不使用流水线与使用流水线所用的时间之比。
3.2.2 公式
基本公式:
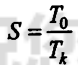
其中,T0为不使用流水线的时间,Tk为使用流水线的时间。
任务连续的情况下,流水线的加速比公式:
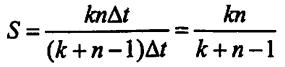
其中,k为流水线段数。
3.高级流水线技术
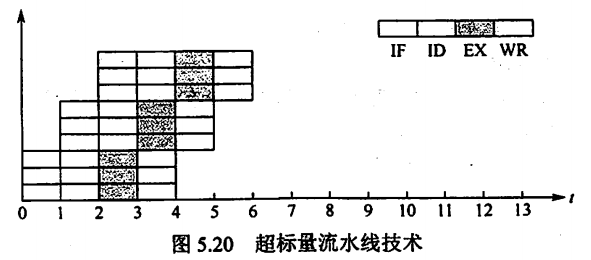
3.1 超标量流水线技术
- 通过配置多个同功能的部件,使得在每个时钟周期内可以并行执行多条独立指令。
- 该技术下,CPI < 1。
3.2 超长指令字技术/静态多发射技术
- 需要配置多个处理部件,通过编译程序挖出不同指令间潜在的并行性,从而将这些指令组合成一条具有多个操作码字段的超长指令字(可达几百位)。
- 该技术下,CPI < 1。
- 该技术成本更高,控制更复杂。

3.3 超流水线技术
- 将流水线的功能段进一步划分,功能段划分得越多,时钟周期就越短,指令吞吐率也就越高。但是划分得太多的话,流水线寄存器的开销也就越大,因此并不是划分得越细越好。
- 该技术下,CPI = 1。

Ps
单周期CPU下,指令周期 = 时钟周期,因此 CPI = 1。
多周期CPU下,指令的执行过程被划分为多个阶段执行,每个阶段耗费一个时钟周期,因此,CPI > 1。
基本流水线中,每个时钟周期执行一条指令,因此,CPI = 1。
















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











