







波士顿矩阵
很多公司中都有着不同的产品或者是业务线,但是对于繁琐的业务来说通常我们希望根据业务的好坏进行合理的资源分配,对于这种“好坏”的判断,波士顿矩阵出现了。
一、概念
波士顿矩阵又称市场(销售)增长率-相对市场份额矩阵,先来解释一下二者的概念。
- 市场增长率
计算方式: 比 较 期 市 场 销 售 量 ( 额 ) − 前 期 市 场 销 售 量 ( 额 ) 前 期 市 场 销 售 量 ( 额 ) ∗ 100 \frac{比较期市场销售量(额)-前期市场销售量(额)}{前期市场销售量(额)}*100% 前期市场销售量(额)比较期市场销售量(额)−前期市场销售量(额)∗100
举例(对某商品): 今 年 3 月 份 销 售 500 件 − 今 年 2 月 份 销 售 300 件 今 年 2 月 份 销 售 300 件 ∗ 100 \frac{今年3月份销售500件-今年2月份销售300件}{今年2月份销售300件}*100% 今年2月份销售300件今年3月份销售500件−今年2月份销售300件∗100
- 市场份额(市场占有率)
概念:市场份额指某企业某一产品的销售量(额)在市场同类产品中所占比重。通常有如下三种市场份额的计算方法:
- 总体市场份额:某企业销售量(额)在整个行业中所占比重;
- 目标市场份额:某企业销售量(额)在其目标市场,即其所服务的市场中所占比重;
- 相对市场份额:指某企业销售量(额)与市场上最大竞争者销售量(额)之比,若高于1,表明其为这一市场的领导者。
在构建波士顿矩阵的时候,对于市场份额我们可以使用相对市场份额或者总体市场份额。
根据市场增长率和相对市场份额由低到高进行组合,我们可以得到如下的波士顿矩阵:
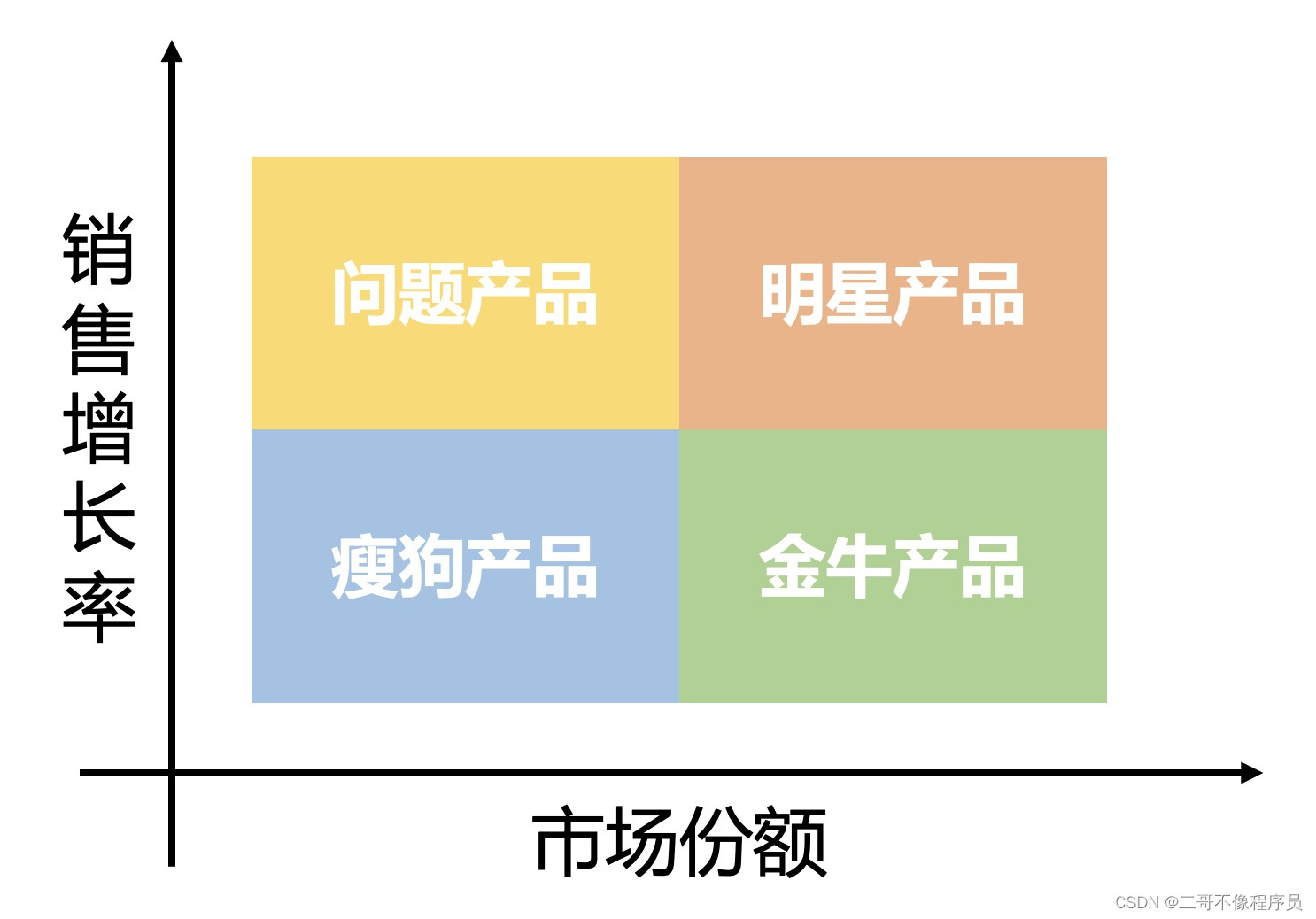
对于四种产品的描述如下:
- 瘦狗产品:相对市场份额低,市场增长机会也没有,拖累公司发展的产品。
- 问题产品:问题产品的问题在于未来,该类型产品有很多不确定性,可能会成为其余三种产品中的任意一种。
- 明星产品:明星产品通常是有前景的新业务,用于抛头露面,开始时期需要大量的投入,是公司的未来(变成成熟的金牛产品)
- 金牛产品:公司中的稳定收入来源,销售增长率低证明其稳定,属于已经进入成熟期的产品。
对于上述四种产品,金牛产品是最好的,接下来是明星、问题、瘦狗。
二、策略
对于四种产品的对应策略如下:
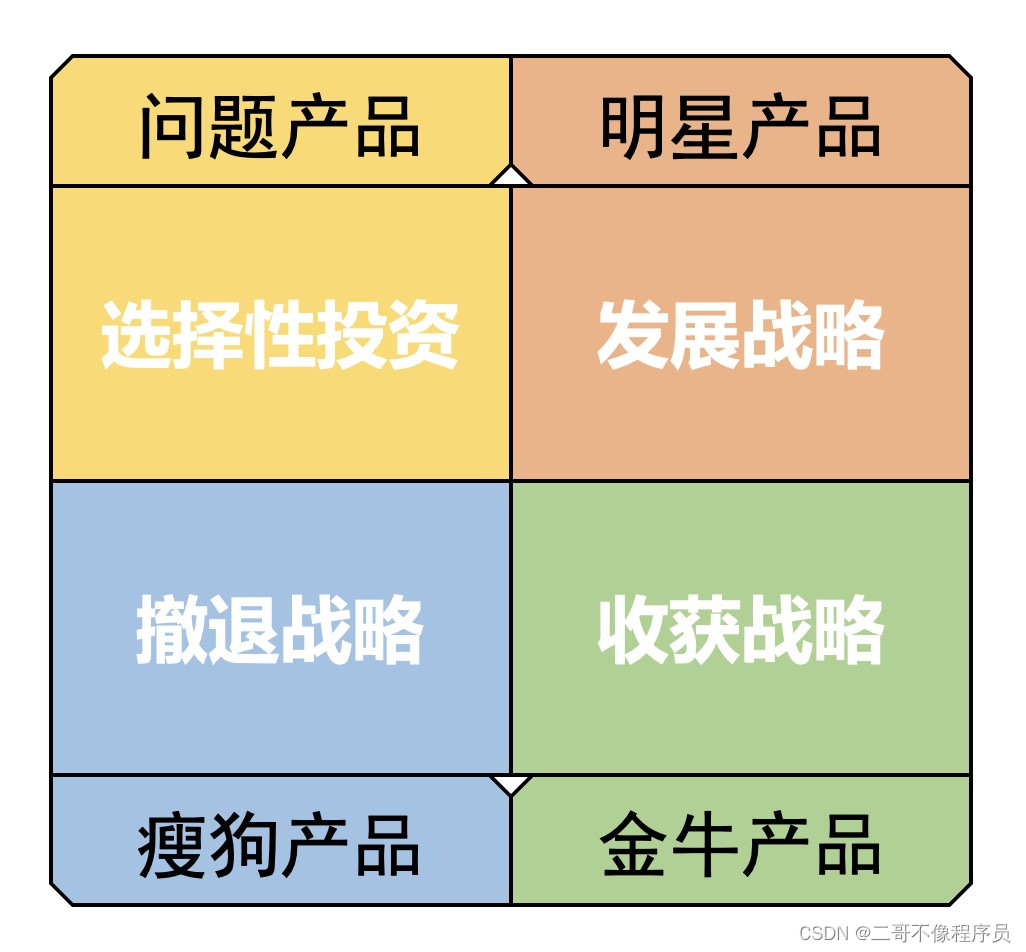
- 瘦狗产品(撤退战略)):该类型产品没有前景,通常采用放弃策略将资源释放给其他产品,或者先采取“割韭菜”战略再放弃。
- 问题产品(选择性投资战略):谨慎投资,规划中心放在如何拓宽市场上,对于该类产品也可以先“割韭菜”然后放弃。
- 明星产品(发展战略):该类产品是未来之星,应该加大投资支持该产品的发展,以长远的利益作为目标,给予其最好的条件。
- 金牛产品(收获战略):减少(压缩)投资,维持市场份额,充分发挥其获取“现金”的能力,争取在短时间内获取更多的利益,处境不佳时进行“割韭菜”。
三、Python实现
注:私信或者公众号后台回复“波士顿”获取示例数据和代码
我们有如下的数据表格:
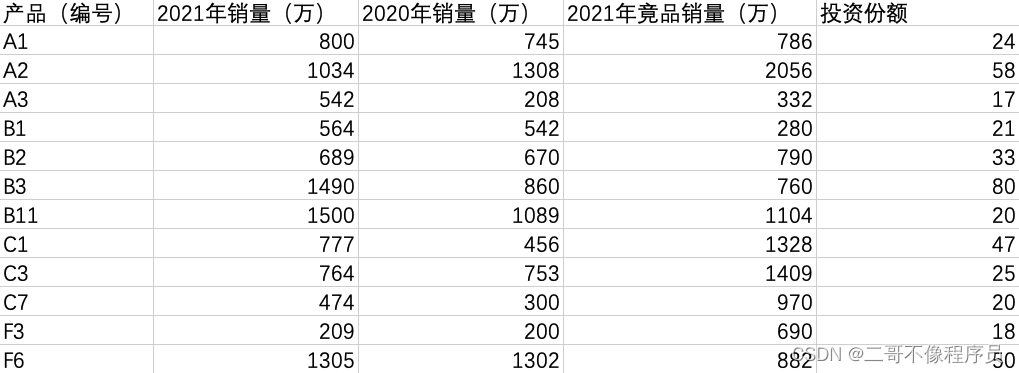
通常我们需要根据数据表去计算市场增长率和相对市场份额,按照上面所提到的公式进行计算即可。
完整Python实现如下:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # win
plt.rcParams["font.family"] = 'Arial Unicode MS' # mac
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_excel('销售数据表.xlsx')
# data.head()
# 计算市场增长率
data['市场增长率'] = (data['2021年销量(万)'] - data['2020年销量(万)']) / data['2021年销量(万)']
# 计算相对市场份额
data['相对市场份额'] = data['2021年销量(万)'] / data['2021年竟品销量(万)']
# 构建颜色列表
color_list = [
'#00F5FF', '#FFDAB9', '#E6E6FA', '#54FF9F', '#7B68EE', '#B0C4DE',
'#40E0D0', '#CDC673', '#FFC125', '#FF1493', '#FFE4E1', '#00BFFF'
]
# 获取数值的最大最小值(用于对气泡进行绘制)
min_x, max_x = min(data["相对市场份额"]), max(data["相对市场份额"])
min_y, max_y = min(data["市场增长率"]), max(data["市场增长率"])
# 绘图
plt.figure(figsize=(10, 10), dpi=200)
# 根据相对份额和市场增长率绘制气泡,投资份额代表气泡大小
for i in range(data.shape[0]):
plt.scatter(x=data["相对市场份额"][i],
y=data["市场增长率"][i],
c=color_list[i],
s=data["投资份额"][i] * 100,
alpha=0.65)
# 向气泡中添加文字
for x, y, sku in zip(data["相对市场份额"], data["市场增长率"], data["产品(编号)"]):
plt.text(x, y, sku, ha='center', va='center', fontsize=12)
# 添加业务名称
plt.text((min_x + 0.9) / 2, (min_y - 0.2) / 2,
"瘦狗业务",
ha='center',
va='center',
fontsize=40,
color='tomato',
alpha=0.6)
plt.text((min_x + 0.9) / 2, (max_y + 0.5) / 2,
"问题业务",
ha='center',
va='center',
fontsize=40,
color='tomato',
alpha=0.6)
plt.text((max_x + 1.5) / 2, (max_y + 0.5) / 2,
"明星业务",
ha='center',
va='center',
fontsize=40,
color='tomato',
alpha=0.6)
plt.text((max_x + 1.5) / 2, (min_y - 0.2) / 2,
"金牛业务",
ha='center',
va='center',
fontsize=40,
color='tomato',
alpha=0.6)
# 绘制坐标
plt.xlim(xmin=min_x - 0.3, xmax=max_x + 0.3)
plt.ylim(ymin=min_y - 0.3, ymax=max_y + 0.3)
# 绘制分割线
plt.axhline(y=(max_y + min_y) / 2, ls="-", color="black", linewidth=2)
plt.axvline(x=(max_x + min_x) / 2, ls="-", color="black", linewidth=2)
# 绘制X,Y轴标签
plt.xlabel("低<————— 相对市场份额(%) —————>高", fontsize=17)
plt.ylabel("低<—————— 市场增长率(%) ——————>高", fontsize=17)
plt.title("公司各项业务-波士顿矩阵", fontsize=23, color='#8B0000')
plt.show()
得到的结果如下:
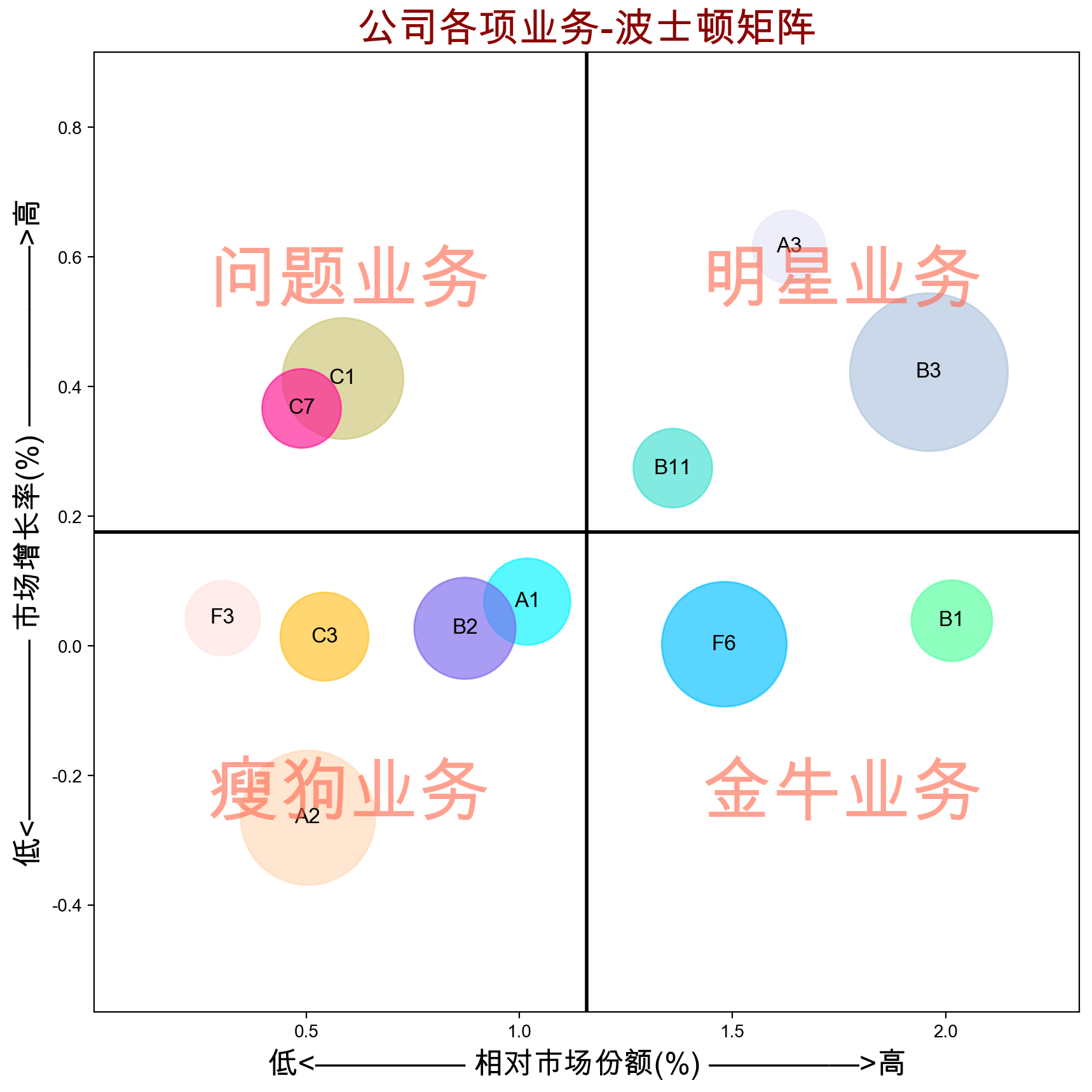
得到结果后,我们按照前面提到的策略对应到具体业务上即可。


















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











