







一、引言
大规模分布式训练的目标是协调多台机器简单高效地训练大模型。然而,在这个过程中,存在着内存需求与GPU内存限制之间的矛盾。
问题分析:假设训练模型所需的内存的Require_memory,GPU的单卡内存为Device_memory,在模型训练过程中的矛盾为Require_memory>>Device_memory。
要解决这两个矛盾,有两个解决方案:“节流”、“开源”。
“节流”的核心思想是在保持模型训练精度的同时减少内存消耗;而“开源”的主要思路是利用各种形式的分布式训练,将模型训练的任务分布到多个GPU上,主要包括数据并行(Data Parallel),分布式数据并行(DistributedDataParallel),模型并行、流水线并行、3D并行等。
其中,数据并行(Data Parallel)是最基础、最常用的一种形式。这篇文章将深入数据并行(Data Parallel,即常说的DP)的原理,并解析数据并行在Pytorch中的实现。
二、数据并行原理
2.1 原理深入
数据并行的原理:将一整个训练数据集分解成多个部分,被分解的每一部分数据分别用于训练模型;获得多个损失结果后,再通过对结果的汇总,获得最终损失。
其主要逻辑遵循Single Program Multiple Data的原则,即在数据并行的模型训练中,训练任务被切分到多个进程(GPU)上,即每个 GPU 复制一份模型,将一批样本分为多份输入各个模型并行计算。每个进程维护相同的模型参数和相同的计算任务,但是处理不同的数据(batch data)。通过这种方式,同一全局数据(global batch)下的数据和计算被切分到了不同的进程,从而减轻了单个设备上的计算和存储压力。
数据并行适用情景:适用于每张 GPU 都可以存储模型、单机多卡的情景。
2.2 数据并行的集群架构
数据并行一般采用参数服务器(Parameter Server)这一框架,适用于单机多卡的情况。参数服务器的整体架构如下:
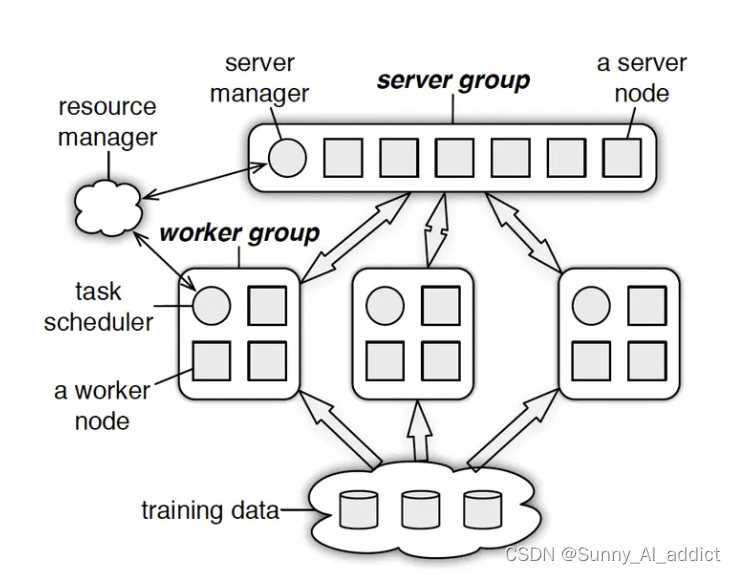
对于Parameter Server来说,计算节点被分成两种:worker和servers。
workers保留一部分的训练数据,并且执行计算。而servers则共同维持全局共享的模型参数。而worker只和server有通信,互相之间没有通信。
下图以伪码方式列出了Parameter Server并行梯度下降的主要步骤:

一文读懂「Parameter Server」的分布式机器学习训练原理
2.3 数据并行过程
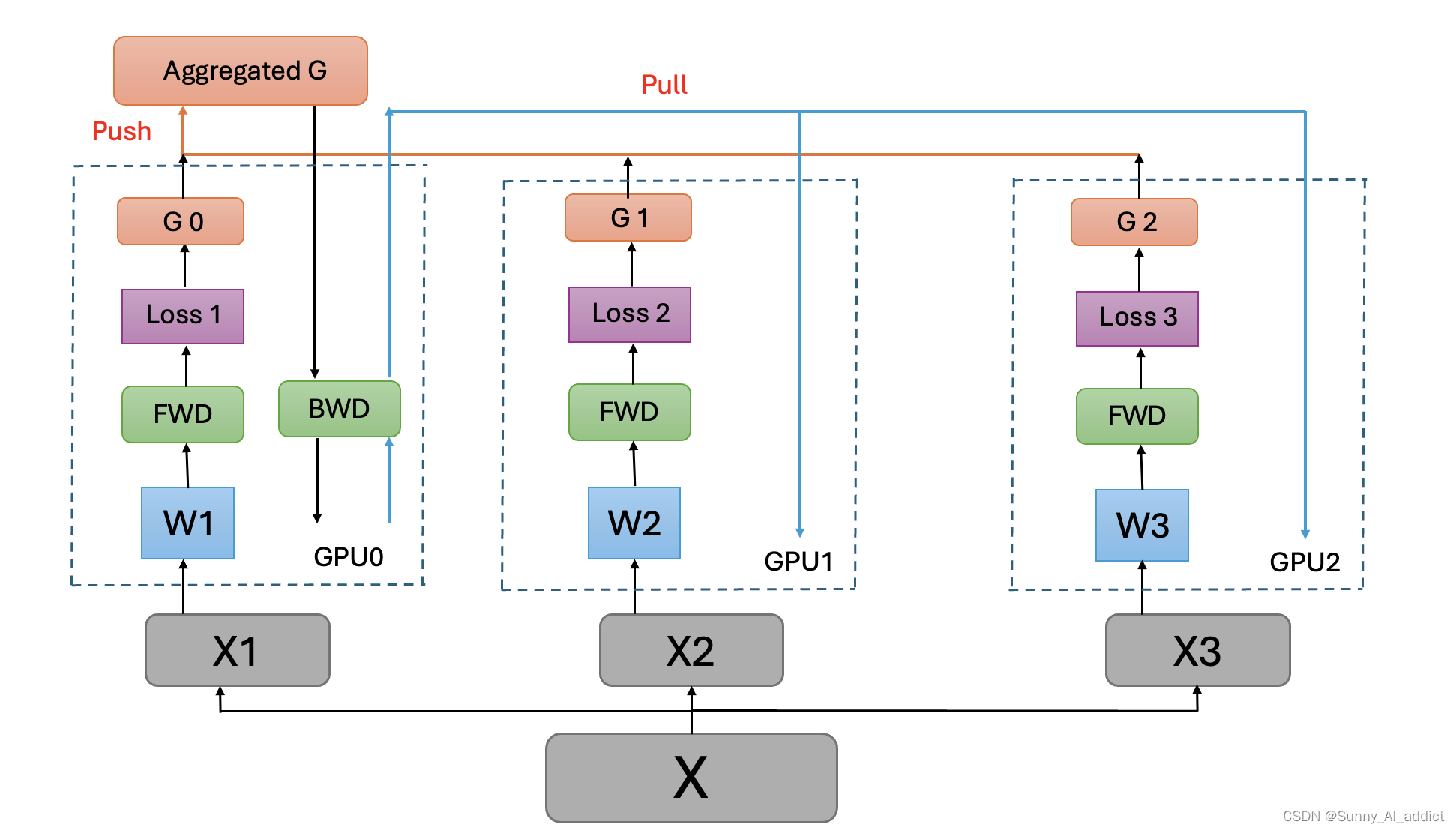
在数据并行中,所有设备都负责计算和训练网络,除此之外, GPU[0] (并非 GPU 真实标号而是输入参数 device_ids 首位) 还要负责整合梯度,更新参数。
主要有三个过程:
- 过程一:各卡分别计算损失和梯度
- 过程二(Push):所有梯度整合到 GPU[0]
- 过程三(Pull):GPU[0] 进行参数更新,其他卡拉取 GPU[0] 的参数进行更新
所有卡都并行运(图中黑色),将梯度收集到 GPU[0](图中橙色)和 GPT[0] 分享模型参数给其他 GPU(图中蓝色)三个主要过程。
2.4 通讯瓶颈与梯度异步更新
数据并行的原理理解起来不难,但在实际使用过程中有两个主要问题:
- 存储开销大:每块GPU上都存了一份完整的模型,造成冗余。
- 同步阻断式:每个worker都需要等待其他所有woker的梯度都计算完后,master节点(即GPU[0])汇总梯度,计算好新的模型参数后,才能开始下一轮的梯度计算。
- 通讯开销大:master节点(即GPU[0])需要和每一个Worker进行梯度传输,master节点的带宽也会成为整个系统的计算效率瓶颈。
举个栗子,假设master节点是组装流水线的小组长,各个worker是流水线上的各个工人;数据并行任务就好比小组长将所有组装的任务平均分配给各个工人,工人完成自己的任务后上交给小组长,小组长清点完之后再下发下一步的任务。
然而在这个过程中,每个wroker的工作效率是不同的,所以完成任务然后发送给小组长的时间点也是不同的,对于工作效率高的worker,等其他worker完成的时间,是空闲时间;同时,小组长要等到最后一个工人的任务完成后才能清点完成再派发任务,这段时间对于所有的worker来说,是空闲的时间。
流水线老板怎么会愿意流水线上有那么多的空闲呢:“打工系统里不允许有串行存在的任务!”,于是梯度异步更新这一管理层略诞生了。
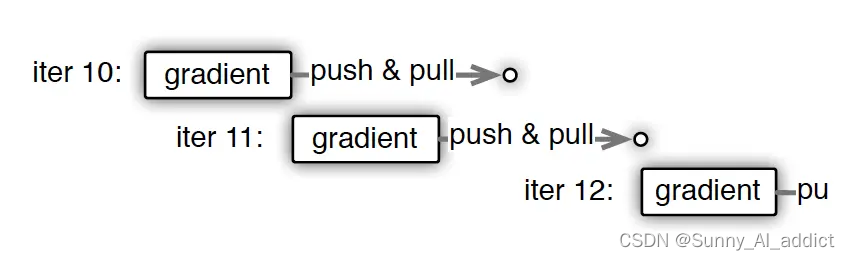
上图刻画了在梯度异步更新的场景下,某个Worker的计算顺序为:
- 在第10轮计算中,该Worker正常计算梯度,并向master节点发送push&pull梯度请求。
- 但是,该Worker并不会实际等到把聚合梯度拿回来,更新完参数W后再做计算。而是直接拿旧的W,吃新的数据,继续第11轮的计算。这样就保证在通讯的时间里,Worker也在马不停蹄做计算,提升计算通讯比。
- 当然,异步也不能太过份。只计算梯度,不更新权重,那模型就无法收敛。图中刻画的是延迟为1的异步更新,也就是在开始第12轮对的计算时,必须保证W已经用第10、11轮的梯度做完2次更新了。
当然,任何的技术方案都是取舍,异步梯度更新的方式虽然大幅加快了训练速度,但带来的是模型一致性的丧失,也就是说并行训练的结果与原来的单点串行训练的结果是不一致的,这样的不一致会对模型收敛的速度造成一定影响。所以最终选取同步更新还是异步更新取决于不同模型对于一致性的敏感程度。这类似于一个模型超参数选取的问题,需要针对具体问题进行具体的验证。
除此之外,在同步和异步之间,还可以通过一些“最大延迟”等参数来限制异步的程度。比如可以限定在三轮迭代之内,模型参数必须更新一次,那么如果某worker节点计算了三轮梯度,该节点还未完成一次从server节点pull最新模型参数的过程,那么该worker节点就必须停下等待pull操作的完成。这是同步和异步之间的折衷方法。
四、数据并行的简单Pytorch实现
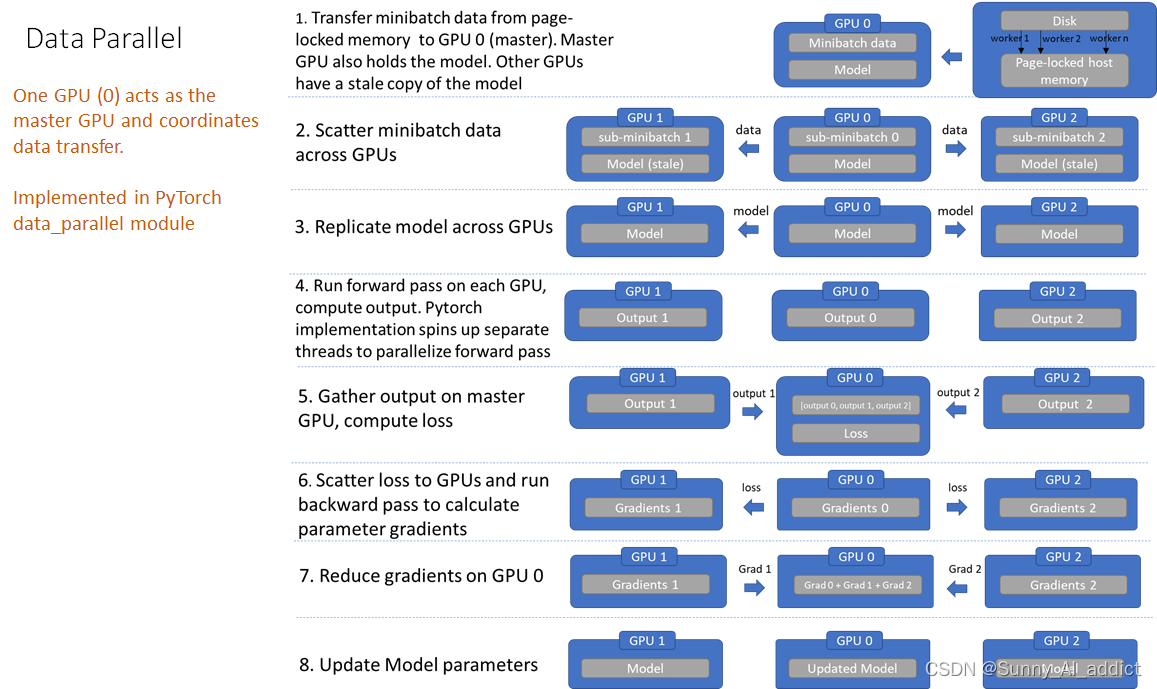
通过 PyTorch 使用多个 GPU 来实现数据并行非常简单,可以将模型放在主GPU(GPU[0] )上,
通过使用 DataParallel 来使模型并行运行,可以很容易的在多 GPU 上运行操作:
-
给本程序设置可见GPU。
- 对应代码就是使用 args.gpu_id="2,7" 和 os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_id 来配置 gpu 序号,其实目的就是设置 os.environ['CUDA_VISIBLE_DEVICES'] = "2,7",这样 device_ids[0]对应的就是物理上第2号卡,device_ids[1]对应的就是物理上第7号卡。
- 也可以在运行时临时指定,比如:CUDA_VISIBLE_DEVICES='2,7' Python train.py。
-
把模型参数和缓冲区放在device_ids[0]上,在运行DataParallel模块前,并行化模块必须在device_ids [0]上具有其参数和缓冲区。
- 代码就是 model=model.cuda() 。
-
构建DP模型。DP 的好处是使用起来非常方便,只需要将原来单卡的 module 用 DP 改成多卡。
- 代码就是 model=torch.nn.DaraParallel(model)。
- 实际上 DP 是一个Pytorch的nn.Module,所以模型和优化器都需要使用.module来得到实际的模型和优化器。
-
把数据载入到主GPU。
- data,label= data.cuda(),label.cuda()
-
进行前向传播。
- DP 会把模型module 在每个device上复制一份。
- DP 会把输入数据再切分为多个小块,把这些小块数据分发到不同的GPU之中进行计算,每个模型只需要处理自己分配到的数据。
-
进行后向传播。
- DP 会把每个GPU 计算出来的梯度累加到GPU 0之中进行汇总。
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
K = torch.cuda.device_count() # number of GPUs
model = Model(input_size, output_size) # 1. 模型初始化,不变
model_DP = nn.DataParallel(model, device_ids=list(range(K)) # 启用DataParallel,新增
opt = Optimizer(arg_opt, model.parameters()) # 2. 优化器初始化,不变
y = model_DP(x) # 3. 模型计算,改用DataParallel之后的模型
loss = loss_f(y, target) # 4. 损失函数计算,不变
loss.backward() # 5. 反向传播,不变
opt.step() # 6. 优化器更新参数,不变主要的改动就是两部分:初始化DataParallel(这一步非常简单,只是记录一些初始化参数)、使用DataParallel后的模型model_DP替换model进行计算(实际的数据并行计算)。
这里有个小trick,只有前向传播在K张卡之间并行,损失函数计算(loss_f)以及反向传播的启动(.backward())、优化器更新都只进行了一次,都不需要更改。
这里有个小trick,在使用nn.DataParallel(model) 操作之后,形成的模型对象实际上被封装在了DataParallel这个模块里,在保存模型的权重时,需要将模型对象预先提取出来。
E.g.
# take the module
model=model.module
五、手撕数据并行源码
源代码地址:
https://github.com/pytorch/pytorch/blob/main/torch/nn/parallel/data_parallel.py
5.1 __init__
我们通过 DataParallel 的初始化函数来看看 DataParallel 的结构:
- __init__三个输入参数的定义:
1. module : 训练的模型
2. device_ids :训练的CUDA device(默认所有CUDA)
3. output_device :保存输出结果的devic(默认是在device_ids[0],即第一块卡)
class DataParallel(Module, Generic[T]):
def __init__(
self,
module: T,
device_ids: Optional[Sequence[Union[int, torch.device]]] = None,
output_device: Optional[Union[int, torch.device]] = None,
dim: int = 0,
) -> None:
super().__init__()
torch._C._log_api_usage_once("torch.nn.parallel.DataParallel")
# 得到可用的GPU
device_type = _get_available_device_type()
if device_type is None:
self.module = module
self.device_ids = []
return
# 没有输入的情况下,使用所有可见的GPU
if device_ids is None:
device_ids = _get_all_device_indices()
if device_ids is None:
raise RuntimeError("no available devices were found")
# 设置默认的output_device
if output_device is None:
output_device = device_ids[0]
self.dim = dim
self.module = module
self.device_ids = [_get_device_index(x, True) for x in device_ids]
self.output_device = _get_device_index(output_device, True)
self.src_device_obj = torch.device(device_type, self.device_ids[0])
# 检查负载均衡
if device_type == "cuda":
_check_balance(self.device_ids)
# 单卡就直接使用
if len(self.device_ids) == 1:
self.module.to(self.src_device_obj)5.2 检查负载均衡
虽然输入数据是均等划分并且并行分配,但是Gredient每次都会在GPU[0]聚合相加计算,所以GPU[0]的内存负载和使用率会大于其他显卡。
_check_balance 函数会检查负载是否平衡, 如果内存或者GPU core使用 > 75% 会有警告。
def _check_balance(device_ids: Sequence[Union[int, torch.device]]) -> None:
imbalance_warn = """
There is an imbalance between your GPUs. You may want to exclude GPU {} which
has less than 75% of the memory or cores of GPU {}. You can do so by setting
the device_ids argument to DataParallel, or by setting the CUDA_VISIBLE_DEVICES
environment variable."""
device_ids = [_get_device_index(x, True) for x in device_ids]
dev_props = _get_devices_properties(device_ids)
def warn_imbalance(get_prop):
values = [get_prop(props) for props in dev_props]
min_pos, min_val = min(enumerate(values), key=operator.itemgetter(1))
max_pos, max_val = max(enumerate(values), key=operator.itemgetter(1))
if min_val / max_val < 0.75:
warnings.warn(imbalance_warn.format(device_ids[min_pos], device_ids[max_pos]))
return True
return False
if warn_imbalance(lambda props: props.total_memory):
return
if warn_imbalance(lambda props: props.multi_processor_count):
return5.3 Forward()
DataParallel并行计算只存在在前向传播过程之中。
forward函数之中,就不用作这一步,而是从分发模型和数据开始,需要注意的是:每次前向传播的时候都会分发模型。具体分为几个步骤。
- 验证:遍历module的parameters和buffers,看看是否都在GPU[0]之上,如果不在,报错。
- 分发((Scatter)输入数据:将输入数据根据其第一个维度(一般是 batch 大小)划分多份,传送到多个 GPU;
- 复制(Replicate)模型:将模型分别拷贝到多个 GPU;
- 并行应用(parallel_apply):在多个模型之上并行进行前向传播。因为 GPU device_ids[0] 和 base parallelized module 共享存储,所以在device[0] 上的 in-place 更新也会被保留下来,其他的GPU则不会。
- 收集(Gather):收集从多个 GPU 上传送回来的数据;
def forward(self, *inputs: Any, **kwargs: Any) -> Any:
with torch.autograd.profiler.record_function("DataParallel.forward"):
if not self.device_ids:
return self.module(*inputs, **kwargs)
# 验证:遍历module的parameters和buffers,看看是否都在GPU[0]之上,如果不在,报错
for t in chain(self.module.parameters(), self.module.buffers()):
if t.device != self.src_device_obj:
raise RuntimeError("module must have its parameters and buffers "
f"on device {self.src_device_obj} (device_ids[0]) but found one of "
f"them on device: {t.device}")
# 现在GPU[0]上有了模型,开始训练:
# 分发输入数据:将输入数据根据其第一个维度(一般是 batch 大小)划分多份,传送到多个 GPU;
inputs, module_kwargs = self.scatter(inputs, kwargs, self.device_ids)
# for forward function without any inputs, empty list and dict will be created
# so the module can be executed on one device which is the first one in device_ids
if not inputs and not module_kwargs:
inputs = ((),)
module_kwargs = ({},)
if len(self.device_ids) == 1:
return self.module(*inputs[0], **module_kwargs[0])
# 复制模型到其他GPU
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
# 并行训练应用
outputs = self.parallel_apply(replicas, inputs, module_kwargs)
# 把前向传播的结果收集到master
return self.gather(outputs, self.output_device)参考:
https://www.cnblogs.com/rossiXYZ/p/15526431.html
https://www.cnblogs.com/rossiXYZ/p/15538332.html
https://zhuanlan.zhihu.com/p/53491660
https://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html
https://zhuanlan.zhihu.com/p/611568694
https://zhuanlan.zhihu.com/p/675217571
PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析 - 知乎 (zhihu.com)

















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









