






EANet: Enhancing Alignment for Cross-Domain Person Re-identification阅读笔记

做了什么?

即PCB这种直接切块不行,如a中间那个直接有两块背景拿去做分类,当然不合理了(但其实PCB切的是特征图,不是原图,而原图下采样到特征图时已具有一定的感受野。因此切的块其实也还是有全局信息的)。于是作者希望能像b那样只对人切块。
那怎么实现呢?
把人抠出来吧,于是直接上COCO训练一个关键点模型,到reid数据集上预测,即为c的效果。
具体做法就是:

首先是其中的R1~R9,这在reid中很常见了,很多都考虑了多粒度/尺度(不同方法切特征图)。
部件分割约束(PS Constraint):
作者发现不同区域提取出来的特征(特别是相邻区域)具有很高的相似度。另外,把遮挡掉一半(上半部或下半部)的图片送进网络,基于part的模型(PCB、PAP)Conv5的特征在被遮挡区域仍有很大的响应。作者猜测是以下原因造成的:
(1)Conv5的感受野很大;
(2)每个part的id约束非常强,从每个part区域提取出来的特征必须具备足够多的信息才能满足id分类的约束。
因此,从一个part区域池化得到的特征很可能表示好几个part的特征。区域划分得越小,则每个区域的id约束越是加重了这个问题。
存在这个问题的模型,虽然也能提取到多个判别性很强的特征,但是作者觉得让conv5失去了定位能力的特征,造成(1)对于part对齐的性能还是有折扣,(2)不同区域得到的特征之间冗余度较高。
为了让模型从一个区域池化得到的特征尽量以这个区域为重点,降低部件之间的冗余度,那就不妨把part直接分割出来吧,于是提出在Conv5的特征图上施加部件分割的约束。直觉解释是,如果从Conv5每个空间位置的特征可以区分出来其属于哪个part类别,那么说明这些特征是具有部件区分性的。因此,还必然做一个part分类的步骤,简单地在Conv5的特征上加一个部件分割的小模块(Part Segmentation Head)来达到这个目的,分类的损失(交叉熵)即计算为
L
k
p
s
L_k^{ps}
Lkps,然后得到:
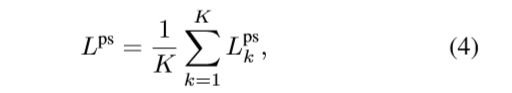

PS模块由一个stride=2的3x3反卷积层(上采样)和一个1x1的卷积层(预测分类)组成。为了得到部件分割的监督信号,我们在COCO上训练了一个部件分割模型,然后在ReID数据库上进行预测,得到部件伪标签,如下图所示(基于关键点就可以分割出各个part):

因此,PS分支其实就是由训练好的分割模型来打标签,不需要reid的标签,无论是源域和目标域都可以加。

对ID分支,就是和PCB类似的过程,不过还是由些许差别,
首先是ID损失的计算从PCB的:
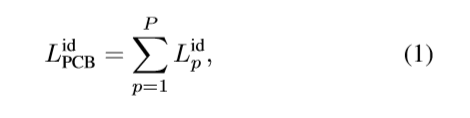
变成了:
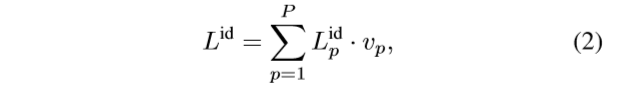
其中只有
v
p
v_p
vp需要解释一下,其余都是PCB一样的。那
v
p
v_p
vp是什么呢?其只能从0,1两个值里选择。那怎么选择?
回到图1,不难看到,图1b中其实有的是6个part,有的是5个part,而5个part的原因是脚部的part在行人检测时丢了,因此即为不可见,对于这些不可见的part,设置 v p v_p vp为0,其余的可见则设为1。
注意:图1是为了和PCB对比才设置成6个part的,但其实作者最好的结果时图2中的9个part(还包含了多粒度信息)。而可见不可见,在关键点定位+抠部件的时候(其实相当于分割或行人解析的作用了),根据置信图就可以知道了。但其实根据可见层度让 v p v_p vp在[0,1]区间上取值应该是一个更好的选择。
那测试时咋办呢?直接给出距离计算:
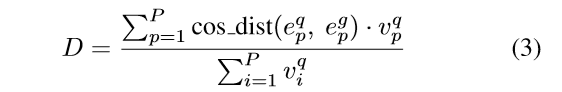
其中p表示part的index,P是总part数。而cos_dist表示计算余弦距离,而q表示query,g表示gallery。
对于query,如果这张query图像的某个part不可见,那这和part的v设置为0,不参与计算;而如果对于一张gallery图像的某个part不可见但在query上可见,则让这些gallery图像的这个part的e的结果为0.
优化目标
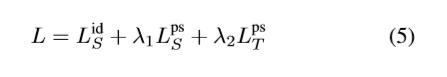
实验
这篇文章的实验部分相当充足,

PAP-6P表示和PCB一样设置6个part,PAP表示9个part。PAP-S-PS表示在PAP+源域上的PS,PAP-ST-PS表示在PAP+源域和目标域上的PS, PAP-S-PS-SA表示PS损失的计算不是按式4(每个part内部逐像素计算损失算,然后加起来做内部平均作为这个part的损失,然后各个part损失相加,对part数再取平均,即作者提到的避免不同part不一样大,导致大的part起主导作用的现象),而是整张图像中的像素的损失相加,再除以整个图像的像素数,作为最终损失,最好结果显示没有作者的那个好(但没有好太多)。




SPGAN做的就是风格迁移,DomainAdaptiveReID做的时CFT。



实验很足。

















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









