






Mask-guided Contrastive Attention Model for Person Re-Identification
作者:Chunfeng Song, Yan Huang,Wanli Ouyang等人 2018CVPR
1. Motivation
背景、视点和pose等都会影响reid,而直接分割出binary-mask以移除背景的效果,因为这种方式太hard了,影响了结构信息和图像的平滑性,而且分割效果不好时还会留下很多背景,效果更差。因此,在特征级上移除背景是一个更好的选择。作者选择输入RGB-Mask的图像,设计了mask-guided contrastive attention model (MGCAM)网络分别从特征级学习body区域和背景区域的信息,还提出了一个改进的triplet损失,将从图像学习的特征和从body区域学习的特征pull到一起,而将从图像学习的特征和从背景区域学习的特征push开。这是第一次将binary mask引入reid任务(不是第一次)和区域级对比学习。
2. 介绍
移除背景、视点和pose等因素对reid的影响,可以用:
- part区域检测、pose和关键点检测
- 分割:能像素级移除背景,更鲁棒;mask中包含body shape信息,可被视为步态特征
但图像级分割出现了motivation中提到的问题,因此作者使用了MGCAM网络,在对比学习下中,网络在binary-body-mask的指导下(保持body shape信息),学习对比attention map,对比attention map用来学习body-aware特征和background-aware特征,用region-level triplet loss进行监督
- 网络从原RGB图像学习外貌信息,从mask学习形态信息;
- 即使mask完全错了,也可以从RGB中学习到信息(类似于跳过连接的作用)
贡献:
- 在binary mask指导下进行对比attention学习,进而学习body-aware和background-aware特征学习,减少了背景的影响
- region-level triplet loss监督,强制模型学习背景不变性特征
- RGB + mask组成4通道的输入图像,以增强特征学习。优势:减少背景影响;包含id不变性特征如body shape信息



3. 方法
整个网络如图2所示:

包含两个组件:
- the contrastive attention sub-net
- the region-level triplet loss for contrastive feature learning
前者用于学习body-aware特征 Φ + \Phi^+ Φ+和background-aware特征 Φ − \Phi^- Φ−,分别用于指导body支路和bkdg支路
3.1. 整体框架
输入时RGB-Mask的4通道输入,用不了3通道上预训练的ResNet-50网络(权重尺寸不匹配,但其实是可以使用的,权重仅仅是第一层不匹配,只需要自己从头学习第一层,后面的层还是可以用预训练的参数微调的)。作者使用了最近提出的multi-scale context aware network (MSCAN), MSCAN的作者是从头开始训练的,在2017年达到了很先进的水平,也就是图2中的MSCAN模块,具体如下图所示:
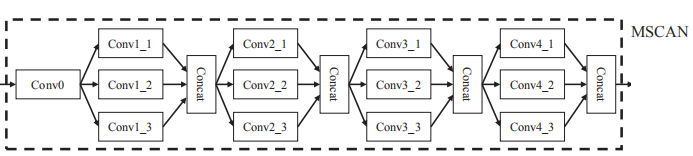
MSCAN传送门:MSCAN

学习得到的f 的size为964016,记为
f
s
t
a
g
e
−
2
f_{stage-2}
fstage−2,三个分支各计算出128-d的行人特征,但仅full分支的结果用作最终的行人特征进行测试。
3.2. Mask-guided Contrastive Attention Sub-net

用
f
s
t
a
g
e
−
2
f_{stage-2}
fstage−2经过一个卷积层学习
Φ
+
\Phi^+
Φ+,即计算得到body-aware的attention map,如下所示:
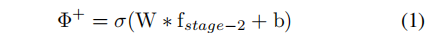
其中,W和b是卷积层的权重和bias,
σ
(
∗
)
\sigma(*)
σ(∗)是sigmoid函数,同时添加约束:

其中(i, j)是特征图上的位置。通过公式2可计算出background-aware的attention map。然后用
Φ
+
\Phi^+
Φ+和
Φ
−
\Phi^-
Φ−分别指导body分支和bkgd分支,如下所示:
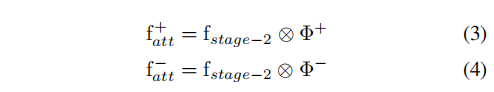
其中,

表示空间加权操作。但
Φ
+
\Phi^+
Φ+和
Φ
−
\Phi^-
Φ−如何分别学习到body区域和背景区域?
用Mean Squared Error (MSE) loss进行监督,如下:

其中M是在百度行人分割数据集上训练的FCN网络对reid数据集分割结果(还需要resize为40*16?),而RGB-M输入处就是直接的分割结果。
3.3. Region-Level Triplet Loss for Contrastive Feature Learning
分别得到
f
f
u
l
l
=
f
f_{full}=f
ffull=f,
f
a
t
t
+
f_{att}^+
fatt+,
f
a
t
t
−
f_{att}^-
fatt−后经过两个MSCAN后分别得到128d的特征向量,记为
h
f
u
l
l
=
f
h_{full}=f
hfull=f,
h
b
o
d
y
h_{body}
hbody,
h
b
k
g
d
h_{bkgd}
hbkgd,分别作为anchor,positive,negative学习三元组损失如下:
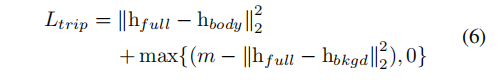
m是margin超参,按经验设置为10。最小化上式的损失让full-stream分支的特征和body-stream分支的特征close,但和bkgd-stream分支的特征far away。
3.4. 目标函数
此外,对于每张图像还单独学习id交叉熵分类损失
L
i
d
L_{id}
Lid。如图3所示:

对于p和q两个人,分别学习得到full-stream特征h§和h(q),Siamese损失为:
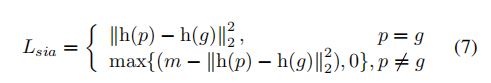
m设置为10。和ZZD的【A Discriminatively Learned CNN Embedding for Person Re-identification】一样。
总损失为:
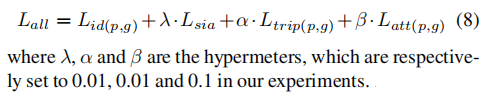
当然也可以不使用Siamese网络进行训练,结果在实验部分进行了评估。
3.5. 特征提取
full分支的128d特征作为最终行人特征进行测试。这个特征有三个好处:MGCAN网络学习的背景不变性特征;从mask学习的body shape信息;联合id损失和Siamese损失学习鉴别性特征。
4. 实验
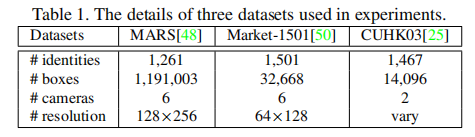
4.1. 数据集

4.2. 实验细节

4.3. 效果评估

说明:
- Mask有效----29.34%的rank@1
- Masked RGB太hard了(直接移除背景)代理负面影响—第一组
- RGB-M输入带来性能提升—第一组和第三组。原因:mask包含body shape信息;mask还能指导原RGB图像学习。
MSCAN是之前别人的结果。





















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









