







14 Facial Age Estimation by Adaptive Label Distribution Learning Xin
缺乏足够和完整的训练数据是人脸年龄估计是中最突出的挑战之一.由于接近年龄的人脸在外观上具有相似性,因此在学习某一特定年龄时可以利用邻近年龄的人脸图像。因此,每个年龄段的训练图像都得到了提升,但实际上训练图像的总数并没有增加。这是通过给每张人脸图片分配一个标签分布而不是单值标签来实现的。标签分布应符合面部衰老的趋势,在不同年龄可能存在显著差异,例如,儿童时期和老年时期的面部特征通常比中年时期变化更快。本文提出了两种自适应标签分布学习(ALDL)算法,即is -ALDL和BFGS-ALDL,用于自动学习适应不同年龄的标签分布。
虽然已有很多算法得到了成功的应用于人脸年龄估计,这一问题仍然存在许多挑战。也许最突出的挑战之一是由于难以在一个大的时间跨度中收集数据,所以缺乏足够完整的训练数据集。幸运的是,年龄相近的人的脸看起来非常相似,因为衰老是一个缓慢而渐进的过程。这促使我们在为一个特定的年龄建模时,可以利用邻近年龄的面部图像。正如我们在之前的工作[10],[11]中所描述的,该思想可以通过为每个人脸图像分配一个标签分布(LD)而不是单个标签的实际年龄来实现。标签分布覆盖一定数量的相邻年龄,表示每个年龄对对应人脸图像的描述程度。因此,每个人脸图像不仅可以帮助学习它的实际年龄,而且可以帮助学习邻近的年龄。这样,在不增加训练图像总数的情况下,提高了每个年龄的训练图像。
问题的定义:
对于人脸图像x,定义其标签分布为一个向量,其中包含相邻年龄对该年龄的相应描述度。年龄y的描述度dy,x 属于【0,1】代表y描述x的程度。对于一个人脸图片x, 在标签分布中的所有年龄的描述度的总和累加是1,例如, 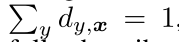
这意味着使用所有的年龄总能完全描述人脸图片。
人脸图像的标签分布年龄α应该满足以下两个性质。首先,α的描述度在标签分布中最高。其次,随着与α距离的增加,相邻年龄的描述程度减小。在满足上述两个性质的许多选项中,以实足年龄α为中心的离散高斯分布的标签分布可能是一个合适的分布,
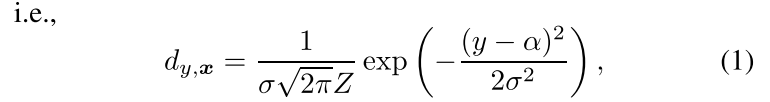
其中,σ是高斯分布的标准差,Z是一个标准化因子,可以保证
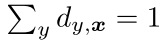
2.Semi-supervised Adaptive Label Distribution Learning for Facial Age Estimation
虽然随着大数据的兴起,人们更容易从互联网上收集到大规模的图像,例如年龄估计任务,但不幸的是,这些图像大多被标记得非常粗略,包含大量的年龄异常值。 他们不利于学习一个好的年龄估计器(Ni, Song, and Yan 2009)。一种可能的解决方案是设计一个鲁棒的年龄估计器,以容忍错误标记的图像。然而,它也被证明是不切实际的。具体来说,将从互联网上收集的人脸老化数据中学习到的年龄估计器应用到一些标准数据集,在MORPH (Ricanek Jr和Tesafaye 2006)和FG-NET (Cootes和Lanitis 2008)上,MAE分别为8.60年和9.49年。
要尽可能精确地估计年龄,更为容易的是能够充分利用现有的小的标记良好的数据。以此为目的,基于老化是一个缓慢渐进的过程,提出了一种利用相邻年龄的信息学习特定年龄的新方法(Geng, Yin, and Zhou 2013)。这是通过给每个人脸图像分配一个标签分布来实现的,而不是分配一个年龄值标签。标签分布覆盖一定数量的相邻年龄,表示每个年龄对对应人脸图像的描述程度。标签分布的形状在所有年龄段都是相同的。
根据以上描述,标签分布 与概率分布具有相同的性质。

3.Deep Label Distribution Learning With Label Ambiguity
其次,很难收集到完整和充分的数据。例如,很难建立一个覆盖1到85岁人群的年龄数据集,并确保在这个范围内的每个年龄都有足够的相关图像。
标签模糊性是指ground-truth标签之间的不确定性。一方面,标签歧义在某些应用中是不可避免的。我们通常用“25岁左右”这样的方式来预测另一个人的年龄,这意味着我们不仅用25岁,而且用邻近的年龄来描述他的脸。
签识别方法主要有两种:单标签识别(SLR)和多标签识别(MLR)。单反相机假设一个图像或像素有一个标签,而MLR假设一个图像或像素可以被分配多个标签。SLR和MLR的目标都是回答哪些标签可以用来描述图像或像素的问题,但它们不能描述与之相关的标签歧义。如果能够合理利用标签歧义,将有助于提高识别性能。 为了利用标签相关性(在某些应用中可能被认为是标签模糊性的结果),Geng等人提出了一种标签分布学习(LDL)方法来估计年龄。
通过深度标签分布学习,与每个类标签相关的训练实例显著增加,而实际上并不增加总训练实例的数量。
DLDL不仅比现有的分类和回归方法具有更强的鲁棒性,而且有效地缓解了对大量训练图像的需求,例如ground- truth标签为25的训练人脸图像也可以用于预测24岁或25岁的人脸的年龄。

对输出概率的描述


数学化

4.DEX
本文中,作者就是将人的年龄划分为0-100共101个类别,通过对年龄进行分类,并获得每个预测年龄的可能性,再乘以各标签年龄,最终得到年龄。因此作者称这种方法为:We pose the age regression problem as a deep classification problem followed by a softmax expected value refinement
In our case, it is a one dimensional regression problem with the age being sampled from a continuous signal ([0,100]).我们可以为回归年龄改善分类构成通过极大的增加类别的数量并因此更好地逼近signal并通过联合神经元的输出恢复signal。增加类的数量需要每个类有足够的训练样本,增加了过度拟合训练年龄分布的机会,以及由于样本的缺乏或不平衡而没有适当训练的类的机会。经过一些初步的实验,我们决定对101个年龄层的班级进行研究。为了提高预测的准确性,如图2所示,我们计算一个softmax期望值E,如下所示:
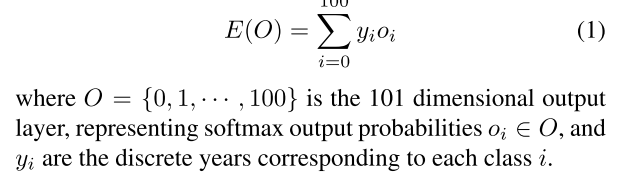
方法怎么讲通过深度分类和期望值细化,提出了一种新的回归公式
我们将年龄回归问题作为深度分类问题,然后对softmax期望值进行细化,并显示了比起对CNN直接回归训练的改善和提升。
年龄估计是一个回归问题,因为年龄是一个连续的值范围。我们进一步使用cnn的回归训练和训练cnn进行分类,其中年龄值四舍五入为101年标签[0,1,…,100]。通过将年龄回归作为深度分类问题,然后对softmax期望值进行细化,我们比直接回归训练cnn有了显著改进。
When training for classification, the output layer is adapted to 101 output neurons corresponding to natural numbers from 0 to 100, the year discretization used for age class la- bels.
预训练
用ImageNet[12]进行图像分类预训练。通过这种方式,我们从能根据图片辨识物体类别的表征中获益。我们的实验表明,这种表示法不能很好地估计年龄。在训练图像上对带有明显年龄标注的CNN进行微调是受益于CNN的表征能力的必要步骤。
图片的处理
The resulting image is then squeezed to 256×256 pixels and used as an input to a deep convolutional network
trick:
1.extend the face size and take 40% of its width to the left and right and 40% of its height above and below. Adding this context helps the prediction accuracy.















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









