






原文链接: q learning sarsa 二维寻宝
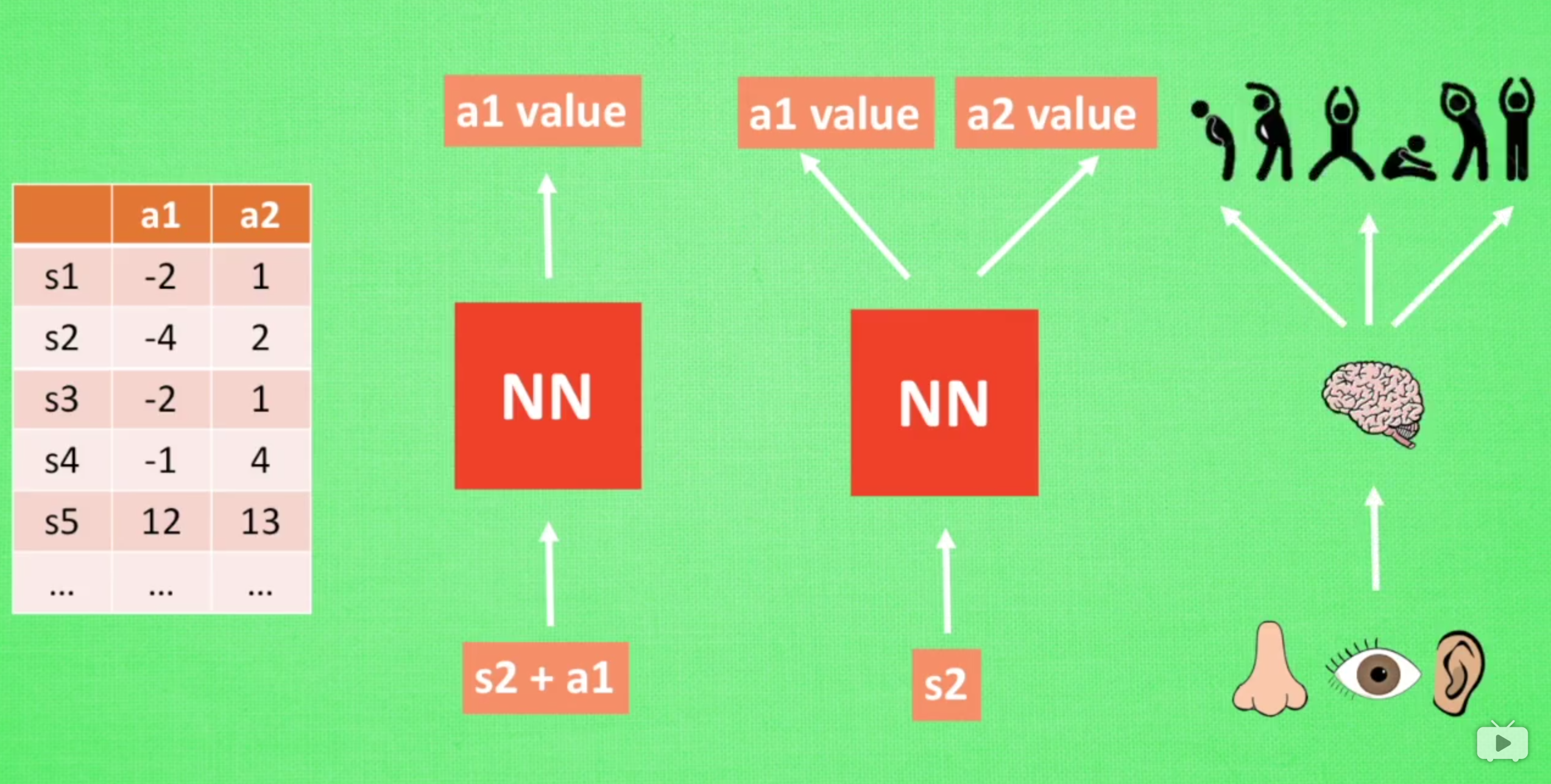
使用q learning 算法 实现二维寻宝游戏
sarsa(lambda) 算法其中lambda表示过往经历的重要性
如果 lambda = 0, Sarsa-lambda 就是 Sarsa, 只更新获取到 reward 前经历的最后一步.
如果 lambda = 1, Sarsa-lambda 更新的是 获取到 reward 前所有经历的步.

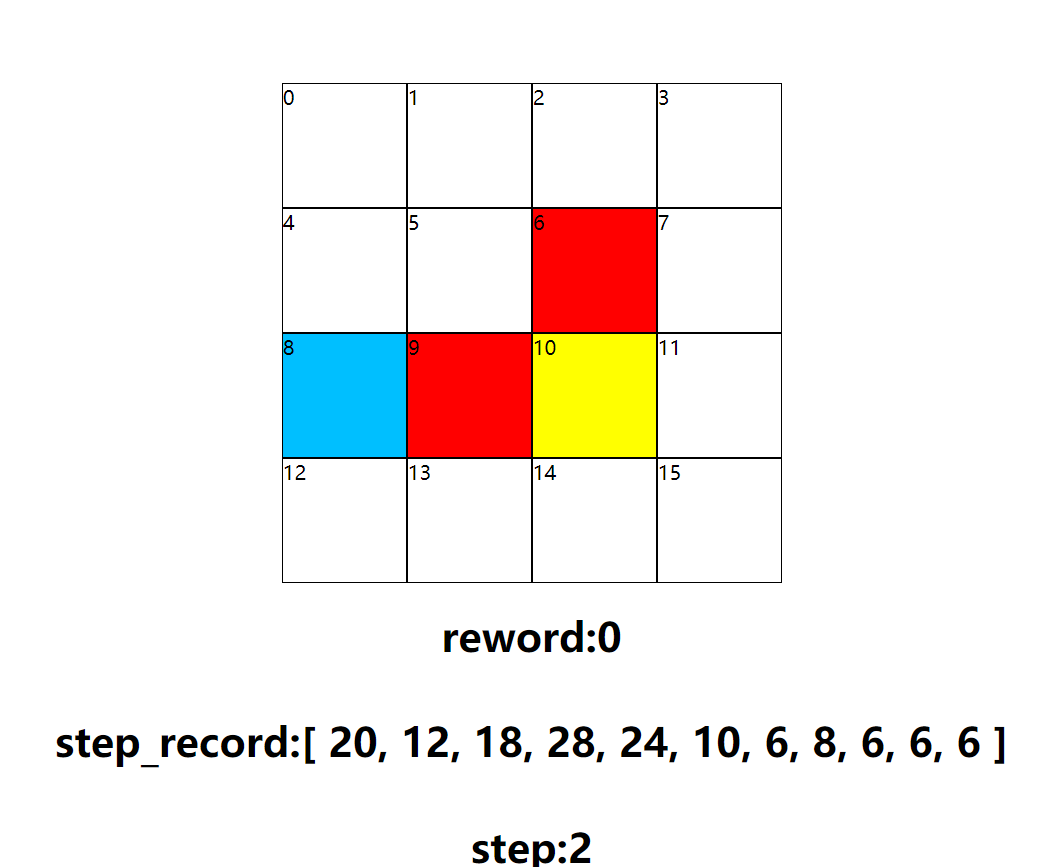
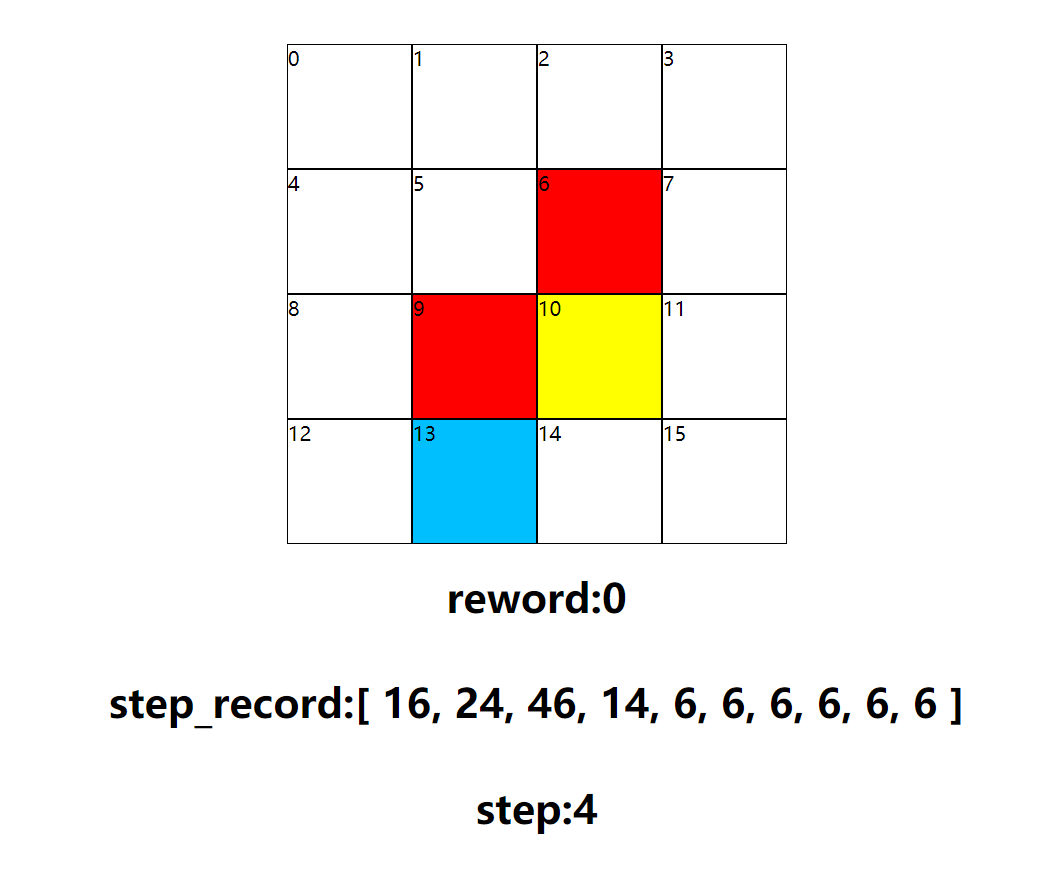
游戏过程

几次结果图可以看到基本是有效的找到了所需路径
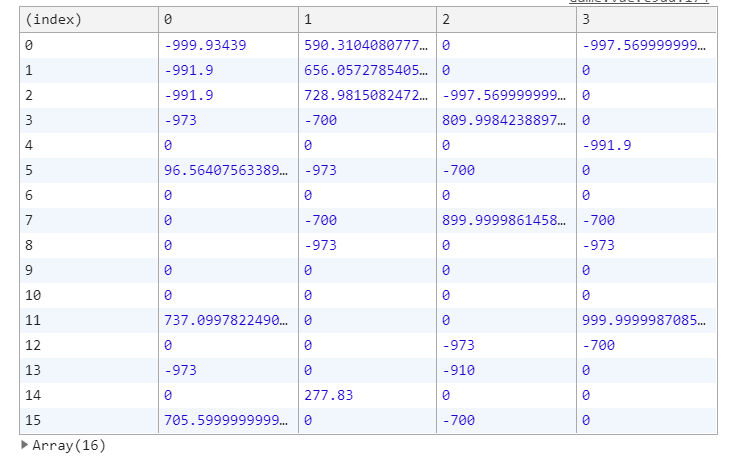
q表
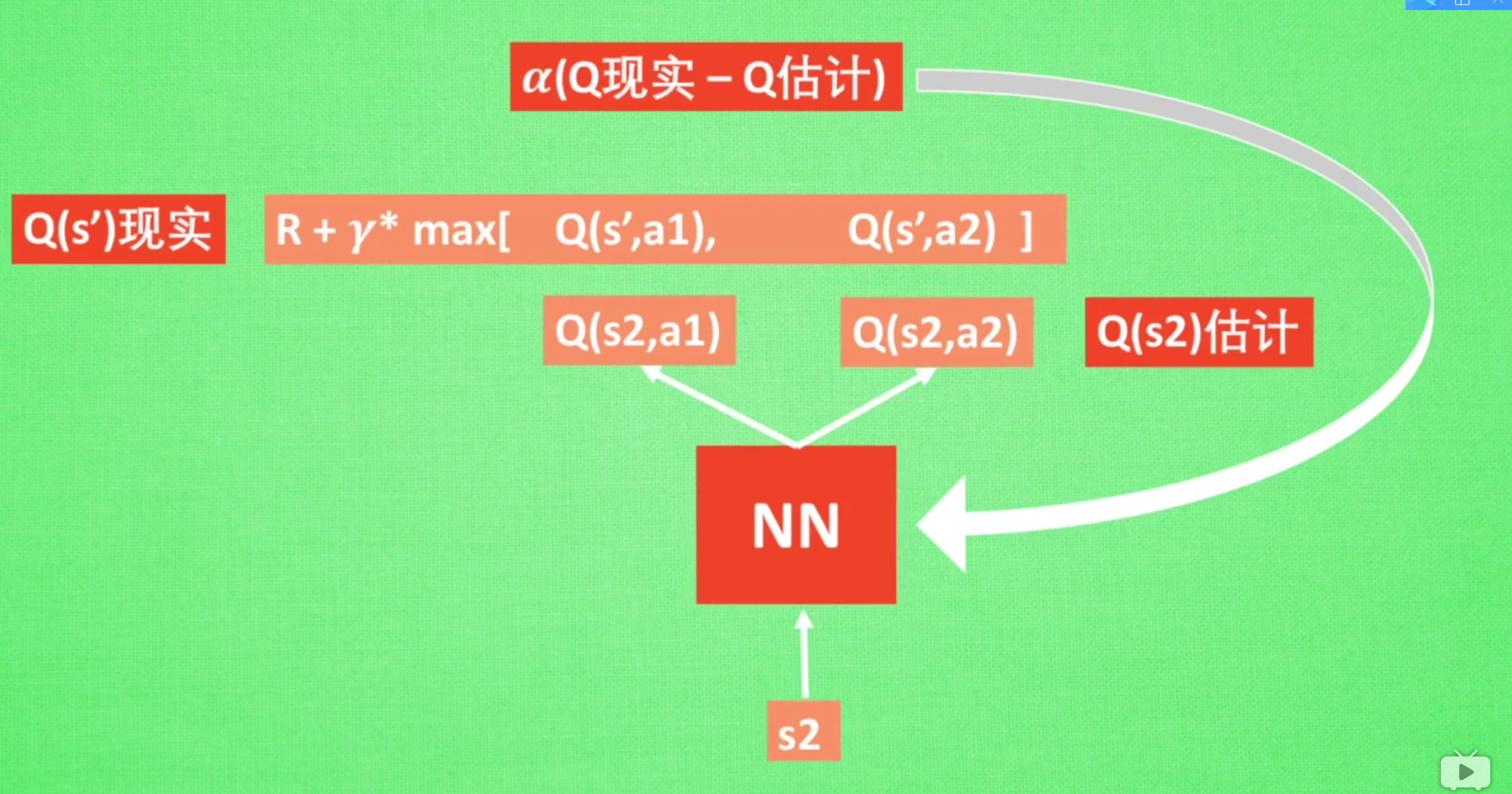
sarsa 算法
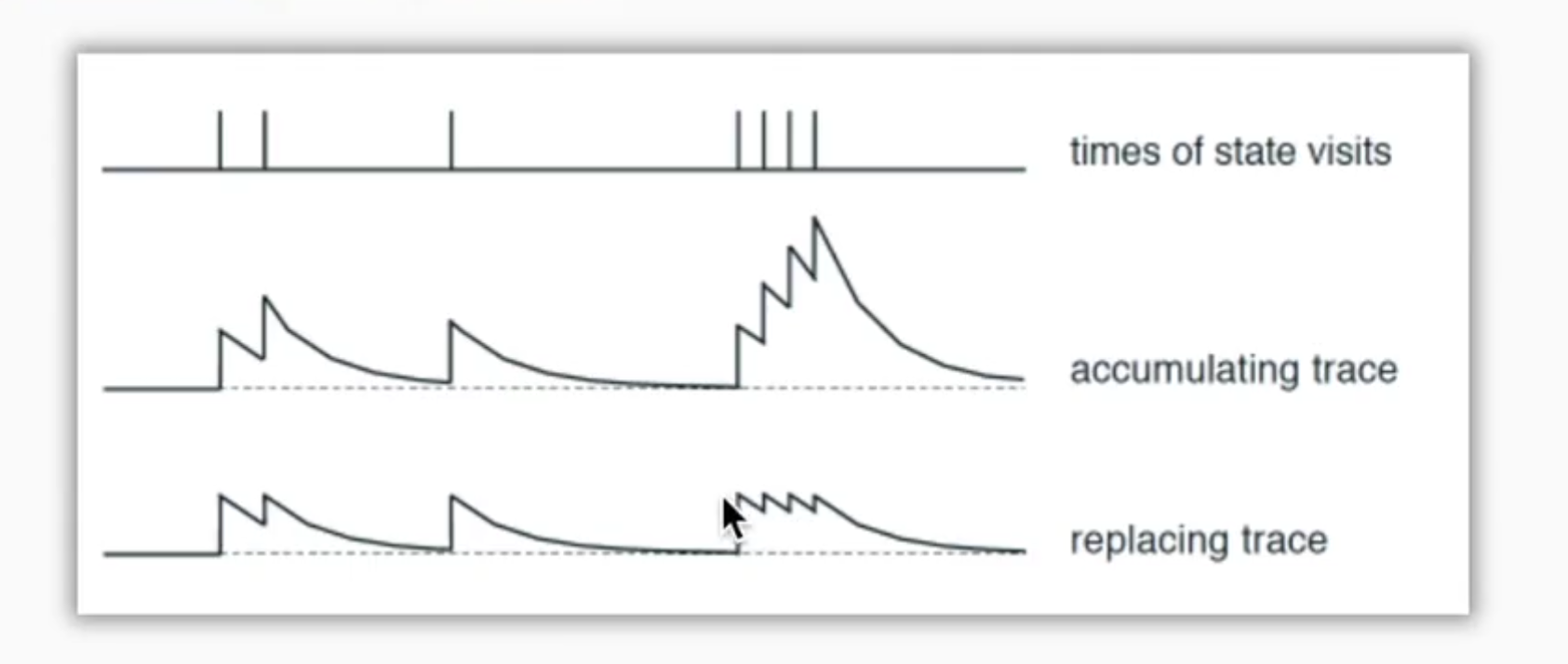
这张图表示的是经历的衰减,一般选取第三种,不累加的替代
因为在开始时会有很多无用步骤,所以如果累加的话,那些无用步骤所占的就多了
# Method 1:
# self.eligibility_trace.loc[s, a] += 1
# Method 2:
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
# Q update
self.q_table += self.lr * error * self.eligibility_trace
# decay eligibility trace after update
self.eligibility_trace *= self.gamma*self.lambda_
<template>
<div class="main">
<div class="game">
<div v-for="row,index_row in mat">
<div v-for="cell,index_col in row" :class="getClass(cell)">
{{index_col*row.length+index_row}}
</div>
</div>
</div>
<h1>reword:{{reword}}</h1>
<h1>step_record:{{step_record}}</h1>
<h1>step:{{step}}</h1>
</div>
</template>
<script>
let classes = ['box', 'start', 'end', 'danger', 'reword']
// 不同种类格子对应的价值
let values = [0, 0, 1000, -1000, 500]
// 方向
let dirs = [
[-1, 0], [0, 1], [1, 0], [0, -1],
]
let width = 4
let height = 4
/**
* 0 普通可通过
* 1 开始
* 2 终点
* 3 危险
* 4 奖励
*/
function getInitMat() {
let init_mat = [
[1, 0, 0, 0],
[0, 0, 3, 0],
[0, 3, 4, 0],
[0, 0, 0, 0],
]
return init_mat
}
let alpha = .7 // 学习率
let gamma = .9 // 未来奖励衰减值
let epsilon = .1 // 随机动作占比
let train_time_inv = 100 // 动作间隔时间
let qtable = Array.from(Array(width * height)).map(() => Array(width).fill(0))
function get_feedback(x, y, action, mat) {
let s = x * width + height
let nx = x + dirs[action][0]
let ny = y + dirs[action][1]
let reword = 0
if (nx < 0 || ny < 0 || nx >= height || ny >= width
|| mat[nx][ny] == 3
) {
// 越界 或 危险
reword = -1000
} else if (mat[nx][ny] == 4) {
reword = 1000
}
return [nx, ny, reword]
}
// 随机返回数组中的值
function random_choice(arr) {
let r = parseInt(arr.length * Math.random())
return arr[r]
}
function choice_action(x, y) {
let all_actions = qtable[x * width + y]
let d = 0
let maxv = 0
if (Math.random() < epsilon || all_actions.every(item => !item)) {
d = parseInt(Math.random() * 4)
} else {
let maxv = Math.max(...all_actions)
let arr = all_actions.reduce(
(pre, cur, index) => {
if (cur === maxv) {
pre.push(index)
}
return pre
},
[]
)
// 如果有多个action值相同,随机选取一个action
d = random_choice(arr)
}
return d
}
export default {
data() {
return {
mat: getInitMat(),
// 当前位置
x: 0,
y: 0,
// 积累的奖励值
reword: 0,
step: 0,
// 控制训练
inv: {},
testInv: {},
step_record: []
}
},
name: "Game",
methods: {
getClass(n) {
return 'box ' + classes[n]
},
reset() {
this.x = this.y = 0
this.mat = getInitMat()
this.reword = 0
this.step = 0
},
// 开始训练
start() {
let d = choice_action(this.x, this.y)
let [nx, ny, reword] = get_feedback(this.x, this.y, d, this.mat)
console.log('x,y,d,nx,ny,reword ', this.x, this.y, d, nx, ny, reword)
let s = this.x * width + this.y
let ns = nx * width + ny
let q_predict = qtable[s][d]
let q_target
if (nx >= 0 && ny >= 0 && nx < height && ny < width
) {
q_target = reword + gamma * Math.max(...qtable[ns])
} else {
// 越界或出错
q_target = reword
}
qtable[s][d] += alpha * (q_target - q_predict)
console.table(qtable)
this.step++
if (nx < 0 || ny < 0 || nx >= height || ny >= width
|| this.mat[nx][ny] === 3
) {
this.reset()
return
} else if (this.mat[nx][ny] == 4) {
this.step_record.push(this.step)
this.reset()
return
}
this.setMat(this.x, this.y, 0)
this.setMat(nx, ny, 1)
this.x = nx
this.y = ny
},
setMat(x, y, v) {
this.$set(this.mat[x], y, v)
},
train() {
this.inv = setInterval(
() => this.start(),
train_time_inv,
)
},
},
mounted() {
this.train()
}
}
</script>
<style scoped>
.main {
width: 100%;
height: 100%;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
}
.box {
box-sizing: border-box;
border: 1px solid black;
width: 100px;
height: 100px;
}
.start {
background: deepskyblue;
}
.end {
background: blue;
}
.danger {
background: red;
}
.reword {
background: yellow;
}
.game {
display: flex;
/*flex-direction: column;*/
}
.mat {
display: flex;
/*flex-direction: column;*/
}
.qmat {
display: flex;
}
</style>















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









