







 本文介绍了如何使用TensorFlow实现变分自编码器(Variational Auto-Encoder, VAE)。VAE不再单纯学习样本个体,而是学习样本的分布规律,具备重构和生成新样本的能力。在编码阶段,网络输出样本分布的均值和方差,以及一个实际的点z。优化目标包括KL散度和重构误差。通过Adam优化器结合两种损失进行训练。网络结构展示和高斯分布取样验证了VAE的学习效果。"
78047204,7352397,C++实现线性表:顺序表的插入、删除与查找操作,"['C++编程', '数据结构', '算法', '顺序存储', '软件开发']
本文介绍了如何使用TensorFlow实现变分自编码器(Variational Auto-Encoder, VAE)。VAE不再单纯学习样本个体,而是学习样本的分布规律,具备重构和生成新样本的能力。在编码阶段,网络输出样本分布的均值和方差,以及一个实际的点z。优化目标包括KL散度和重构误差。通过Adam优化器结合两种损失进行训练。网络结构展示和高斯分布取样验证了VAE的学习效果。"
78047204,7352397,C++实现线性表:顺序表的插入、删除与查找操作,"['C++编程', '数据结构', '算法', '顺序存储', '软件开发']
原文链接: TensorFlow 变分自编码(Variational Auto-Encoder)
上一篇: TensorFlow 栈式自编码神经网络(Stacked Autoencoder,SA)
参考
http://www.cnblogs.com/zyly/p/9121029.html
https://spaces.ac.cn/archives/5253
https://blog.csdn.net/bbbeoy/article/details/78082257
https://mp.weixin.qq.com/s/9lNWkEEOk5vEkJ1f840zxA?
网络框架
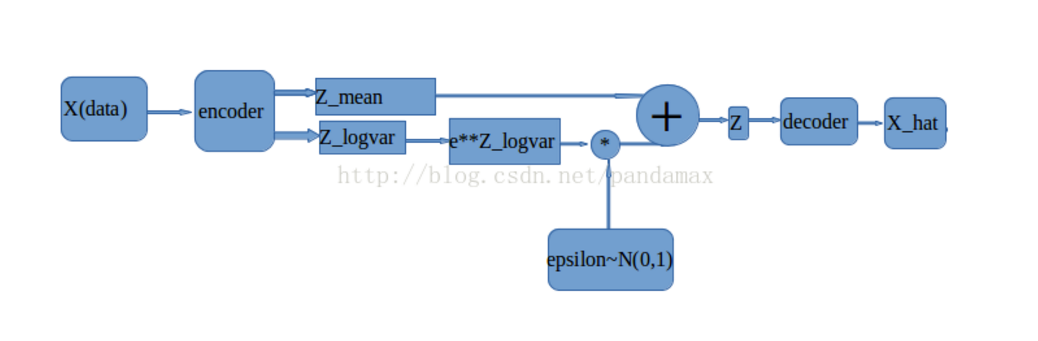
变分自编码不再是学习样0本的个体,而是学习样0本的规律,这样训练出来的自编码不单具有重构样0本的功能,还具有仿照样0本的功能。
变分自编码,其实就是在编码过程中改变了样0本的分布("变分"可以理解为改变分布)。前面所说的"学习样0本的规律",具体指的就是样0本的分布,假设我们知道样0本的分布函数,就可以从这个函数中随便的取一个样0本,然后进行网络解码层向前传导,这样就可以生成一个新的样0本。
代码中w的权重设置的很小,这是因为在计算KL散度时计算的是与标准高斯分布的距离,如果网络的初始生成的模型均值和方差都很大,那么与标准高斯分布的距离就会变得 非常大,这样会导致模型训练不出来,生成NAN的情况
这里节点的方差不是真正意义的方差,是取了log之后的,所以会有tf.sqrt(tf.exp(z_log_sigma_sq))的变换,是取得方差的值,在通过sqrt将其开方得到标准差。用符合标准正态分布的一个数乘以标准差加上均值,就使这个数成为符合(z_mean, sigma)数据分布集合里的一个点,(z_mean 是指网络生成的均值,sigma是指网络生成的z_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









