





 本文提出一种名为ATNet的神经网络框架,该框架结合了顶点帧的空间特征和相邻帧的时间特征,显著提高了跨数据集的微表情识别性能。实验结果表明,在CDE和HDE两种验证方法下,ATNet相比现有技术取得了更佳的效果。
本文提出一种名为ATNet的神经网络框架,该框架结合了顶点帧的空间特征和相邻帧的时间特征,显著提高了跨数据集的微表情识别性能。实验结果表明,在CDE和HDE两种验证方法下,ATNet相比现有技术取得了更佳的效果。
A Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition
作者团队:Min Peng* Chongyang Wang* Tao Bi Tong Chen
发表:ACII 2019(International Conference on Affective Computing and Intelligent Interaction)
原文地址:A Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition
1.摘要
自深度学习方法的成功引入以来,微表情的自动识别得到了极大的提高。在研究微表情本质的同时,利用深度学习技术的实践已经从处理整个微表情视频发展到对顶点帧的识别。利用峰值框架可以去除冗余的时间信息,从而忽略了与微表情相关的时间证据。本文提出了基于顶点帧的空间信息和基于相邻帧的时间信息进行识别的方法。为此,提出了一种新的apextime网络(ATNet)。通过在三个基准上的大量实验,我们证明了在顶点帧周围添加从相邻帧中学习到的时间信息所取得的改进。特别是,具有这种时间信息的模型在跨数据集验证中更加健壮。
关键词:微表情,深度学习,神经网络,特征融合。
模型
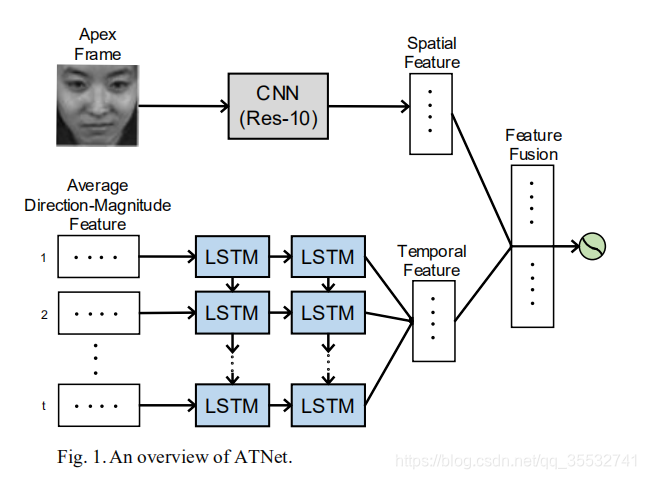
方法
平均方向幅度特征
首先是定位顶点帧,CASME2和SAMM的顶点帧已经给出,对于SMIC我们选取视频中间的那一帧作为顶点帧。顶点帧定位后,我们就可以提取它周围的时间信息。对于时间信息的提取基本采用光流算法。

实验
数据准备和模型实现
实验中用到了三个数据集,分别为CASME2,SAMM,SMIC。下表是对三个数据集的一个总结。
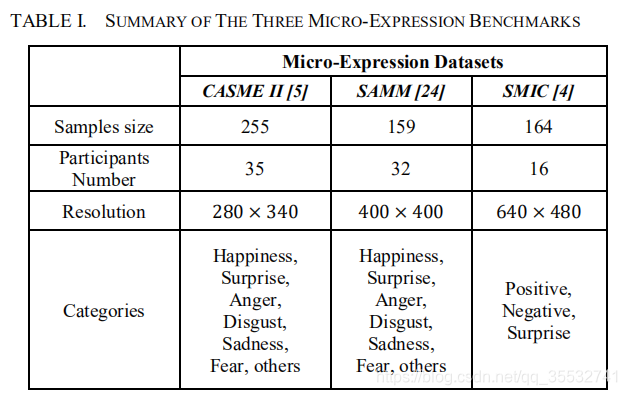
因为用到了三个微表情的数据集,而且SMIC只有三类的微表情标签,因此我们将其他两个数据集的微表情分为三类,即正类(happiness),负类(anger,disgust,sadness,fear)以及surprise。由于顶点帧的数据非常少,所以我们在ATNet的空间流训练中应用了数据增强的策略,策略如下:旋转(最大不超过5度),像素位移(最大值为10),0.5的选择概率。
另外,为了避免过小的微表情数据带来的过拟合问题,我们预先在五个表情数据集上做了预训练。
ATNet的实现框架是Caffe。ATNet时间流中的LSTM层的隐藏单元数量是512。连接层之后使用概率为0.5的drop-out层。最初的学习率为0.01,每10个epoch下降10倍,总共有50个epoch。动量设置为0.9,权重衰减为5e-6。为了比较,我们还应用了基于注意力机制的方法。
验证方法
这里我们详细地叙述一下微表情识别中常被用到的 evaluation method:CDE和HDE。它们来自于 Micro-Expression Grand Challenge (MEGC) 2018。
CDE,即Composite Database Evaluation,复合数据集评估。我们将所有用到的数据集联合,然后做Leave-One-Subject-Out的验证。举个例子,假设我们用到两个数据集CASME2和SAMM,分5类,根据客观分类的方法理论上可以分七类,但是此处我们剔除了第六类和第七类,所以,最后这两个数据集我们能够得到47个Subjects。
HDE,即Holdout-Database Evaluation。HDE中使用了更为严格的跨数据集验证方式,使用其中两个数据集作为训练集,剩下的一个作为测试集。
为了识别微表情的类别,我们应用UAR(Unweighted Average Recall)和UF1(Unweighted F1 Score)作为指标
U F 1 = 1 c ∑ c = 1 C 2 ∗ T P c 2 ∗ T P c + F P c + F N c \ UF1 =\frac 1c\sum_{c=1}^C \frac {2*TP_c}{2*TP_c+FP_c+FN_c} UF1=c1c=1∑C2∗TPc+FPc+FNc2∗TPc
U A R = 1 c ∑ c = 1 C A C C c \ UAR =\frac 1c\sum_{c=1}^C ACC_c UAR=c1c=1∑CACCc
A C C c = T P c c \ ACC_c =\frac {TP_c}{c} ACCc=cTPc
C表示的是类别的个数, T P c \ TP_c TPc, F P c \ FP_c FPc, F N c \ FN_c FNc分别代表了C分类下所有折叠的真正类,假正类和假负类的个数。 N c \ N_c Nc是类别C的样本个数
实验结果与讨论
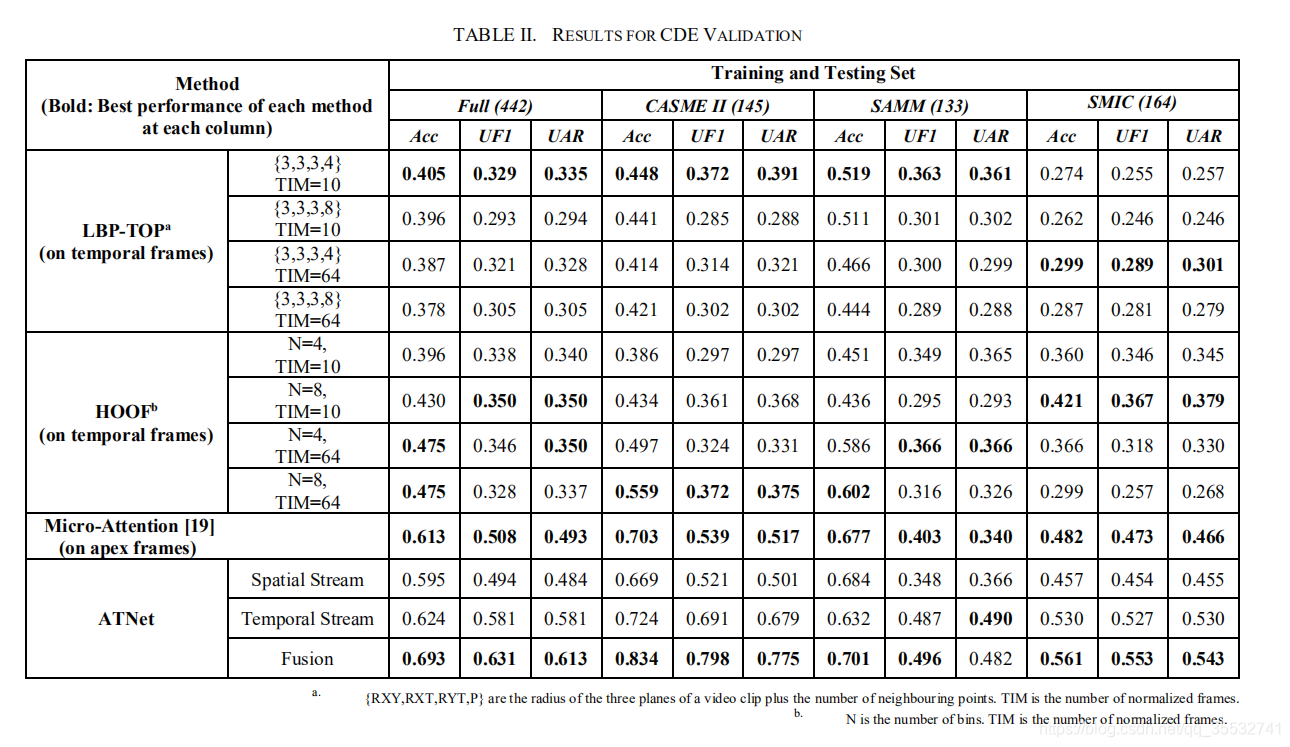
CDE致力于测试不同主题(subject)下模型的泛化能力。
表格中比较了四种方法。在相同的归一化帧下,HOOF比LBP-TOP的结果更好,这是因为光流的特征比局部统计模式更能强调出面部的微小运动。另一方面,我们也发现在TIM=64时,HOOF方法取得了最好的效果,这可能时因为光流特征的计算依赖于帧序列。
结论
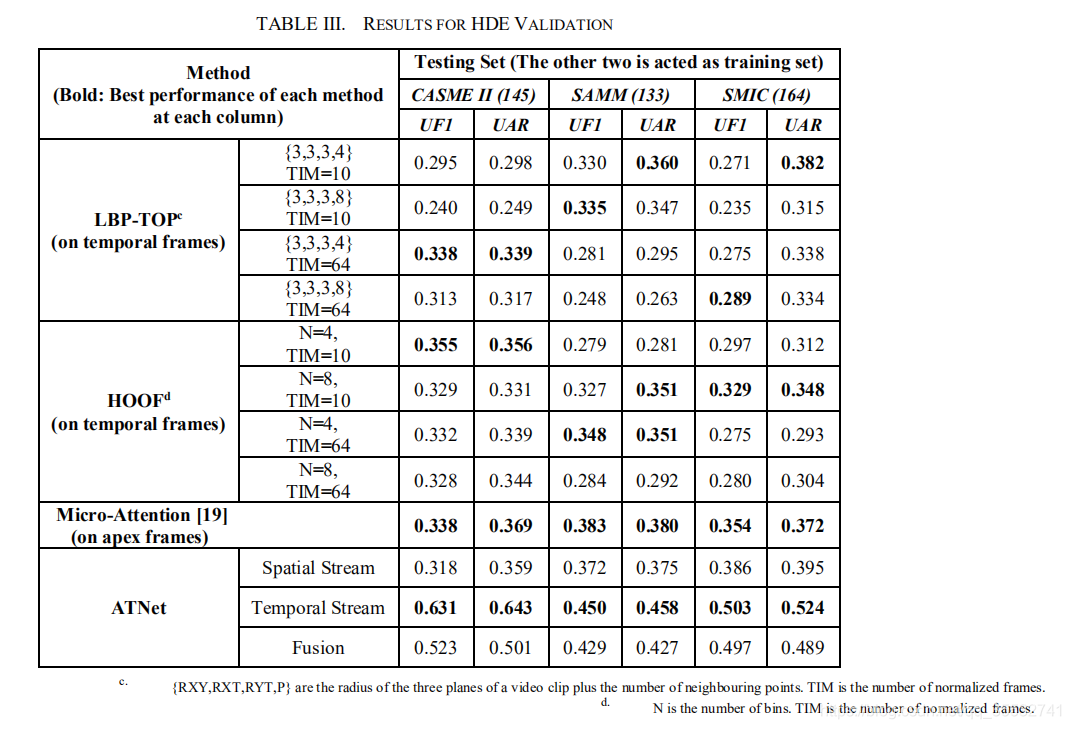
对于跨数据集的微表情识别,本文提出了一种新颖的神经网络框架,即ATNet,这个框架联合了从顶点帧种学到的空间特征和从顶点相邻帧种学到的时间特征。在两个跨数据集验证的方法下(CDE,HDE),相比于其他state-of-the-art的方法,ATNet可以得到更好的结果。从实验中我们可以得出,顶点帧的特征学习比相邻帧的时间特征学习更难以迁移。在HDE实验中,顶点帧的特征甚至阻碍了模型的性能。在未来的工作中, 一个值得关注的焦点是为微表情的识别设计更好的时间动态特征,此外,另一个有趣的方向是在一个视频片段中自动地识别顶点帧。

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









