






摘要
This week, a classic article about the seq2seq structure was read,This network structure better solves the problem of sequence mapping,The authors improved the performance of LSTM by inputting word inversion of input sentences。Moreover, the propagation formula for the LSTM is derived, and I implement how to derive the wave function by the difference.
本周,一篇关于seq2seq结构的经典文章被阅读了,这种网络结构更好的解决了序列映射的问题,作者通过把输入句子的单词逆序输入提高了LSTM的性能。此外,LSTM的传播公式被推导了,以及我实现了如何用差分推导波函数。
LSTM
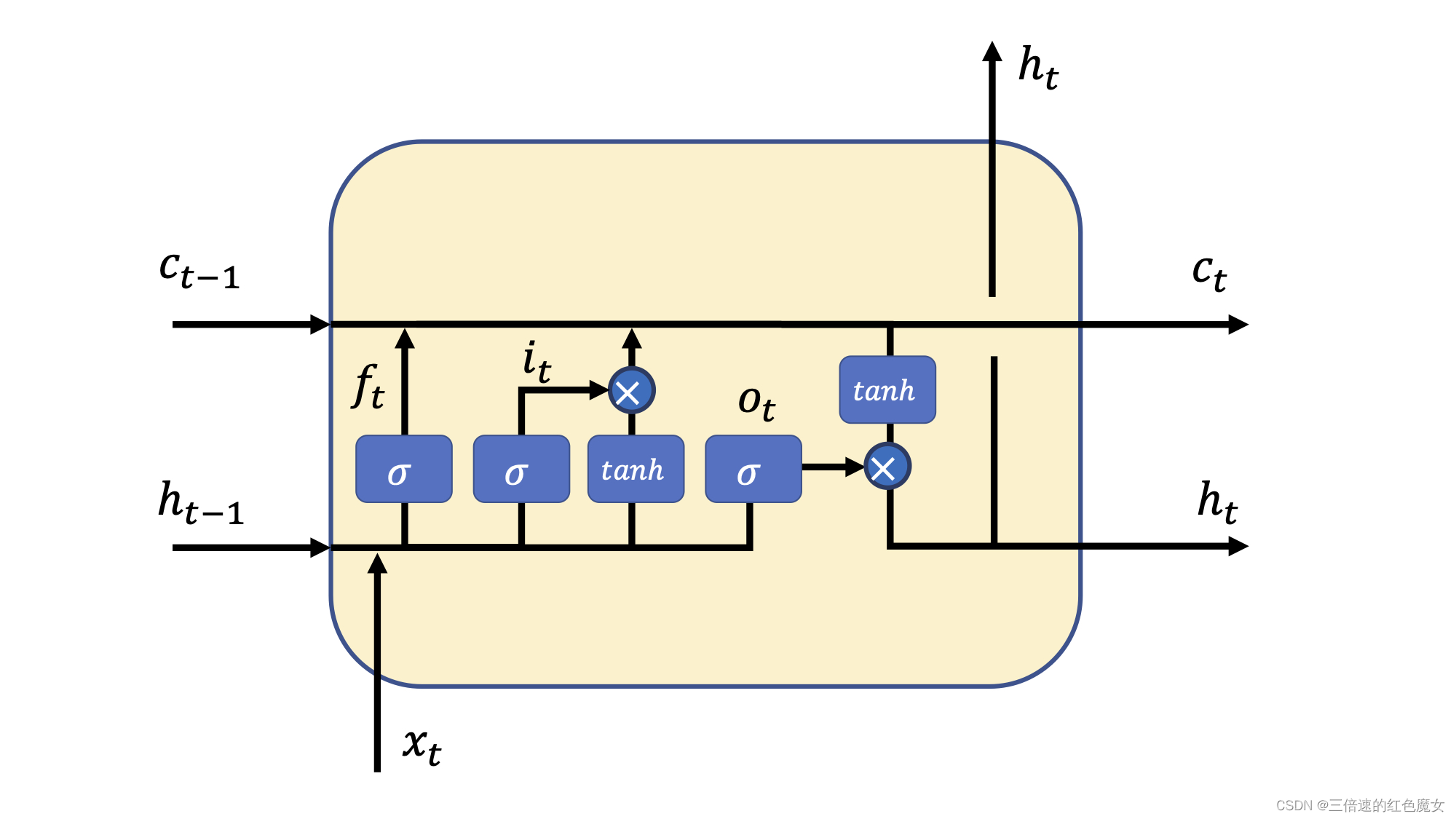
lstm通过三个门做三次决定。Cell状态经历了(1)按位乘(2)加,两种操作。“按位乘”操作,也就是遗忘门操作,是用于丢弃信息;而“加”操作,也就是输入门对应的操作则是用于添加新的信息。
forget gate : 与上一个单元模块传过来的cell状态运算,并决定要保留和遗忘哪些信息。
input gate:隐藏状态和输入x直接按位乘,是在决定按需提取输入的信息,间接和上一个cell状态加和时,是在更新信息。
onput gate:与当前cell状态进行运算,则是决定了哪些信息将被输出。
公式推导
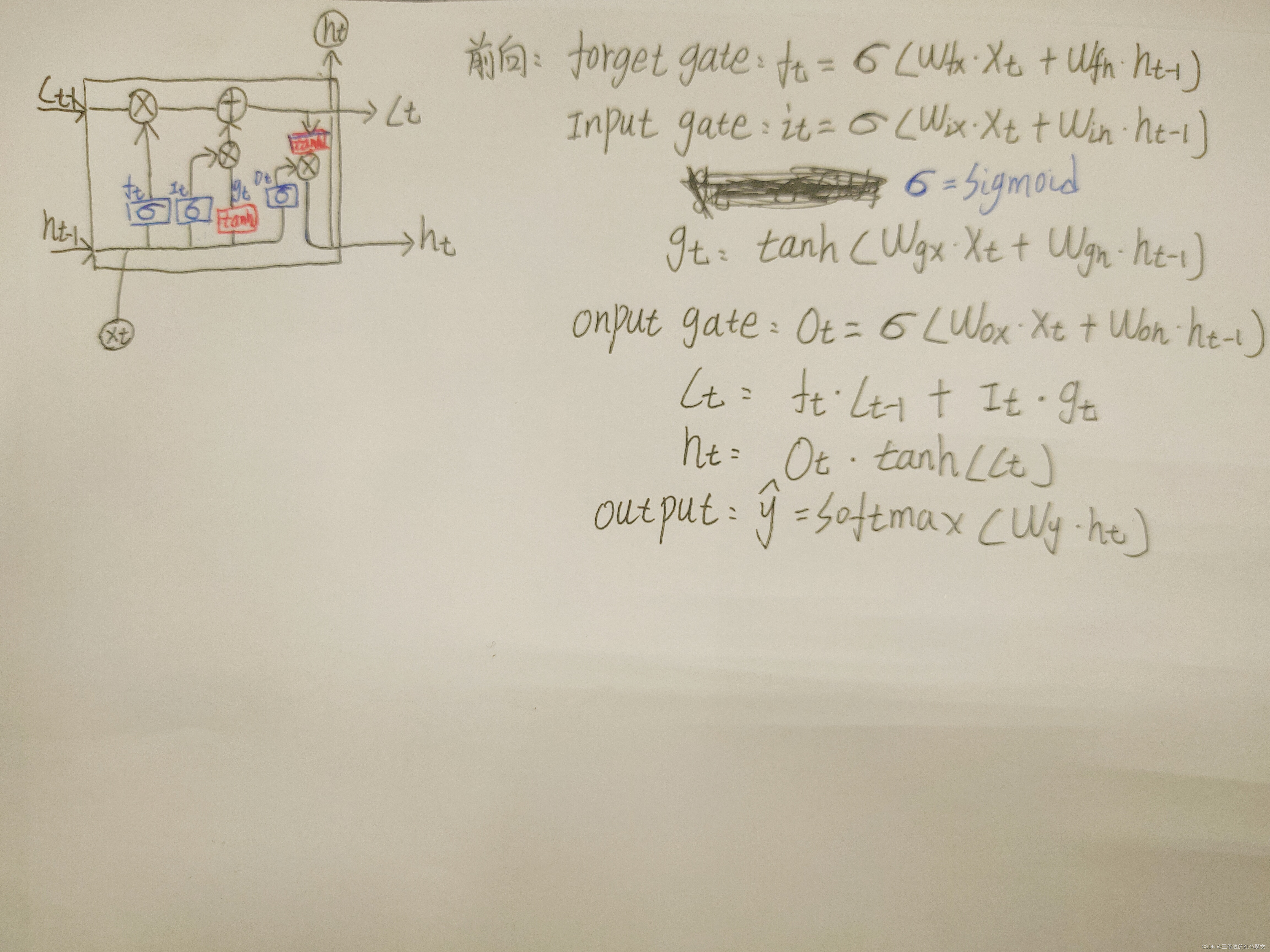
对softmax+交叉熵求导

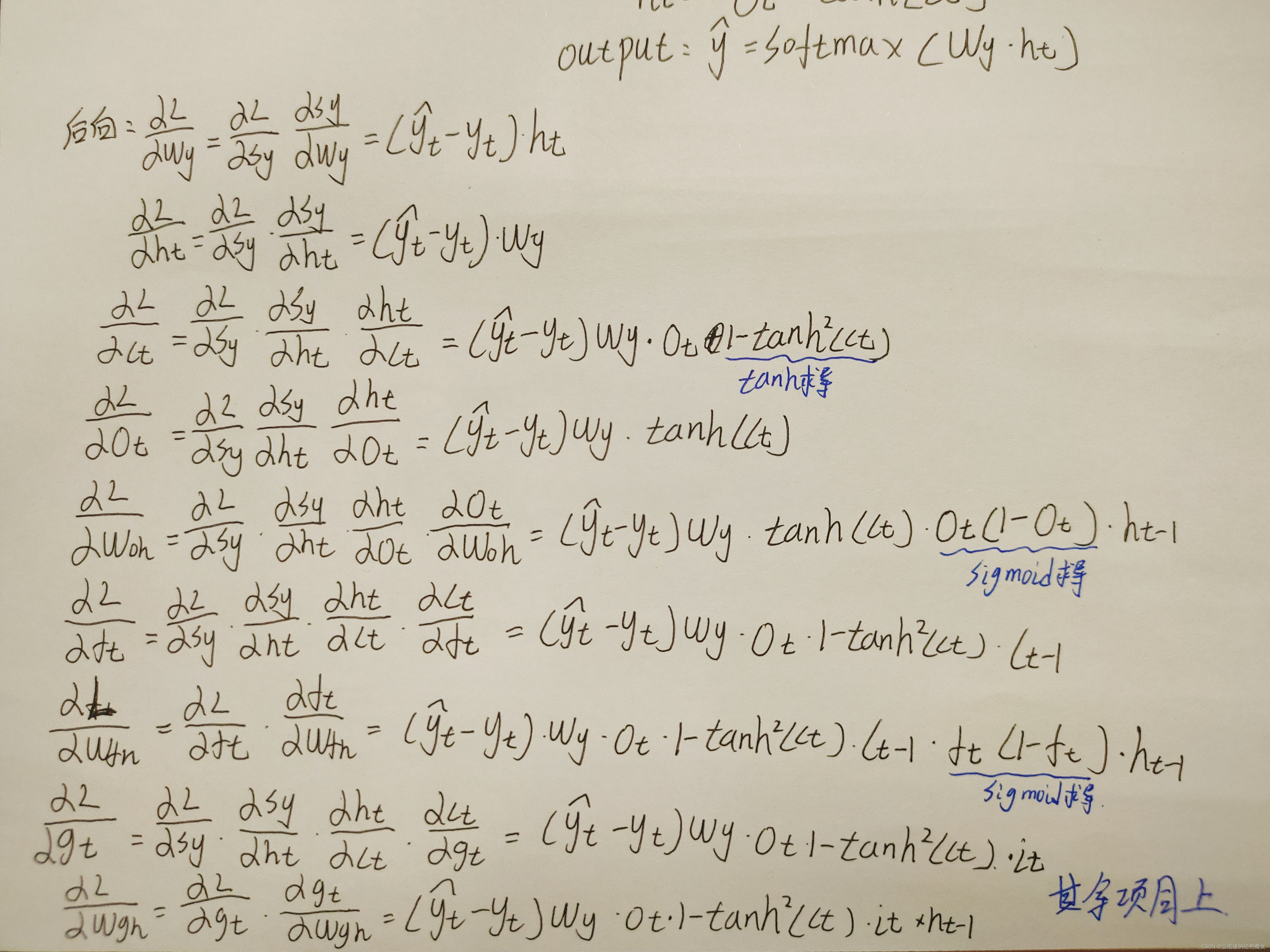
文献阅读
文章名:《Sequence to Sequence Learning with Neural Networks》
作者:Ilya Sutskever,Oriol Vinyals,Quoc V. Le.
摘要:深度神经网络(DNNs)是一种功能强大的模型,它在困难的学习任务中取得了优异的性能。尽管dnn在大型有标记训练集上,工作得很好,但它们不适用于将序列映射到序列的任务。在这篇文章中,作者提出了一种通用的端到端序列学习方法,来学习这种映射关系。作者的方法是使用多层长短期记忆(LSTM)将输入序列映射到一个固定维数的向量,然后使用另一个多层的LSTM把该向量解码为目标序列。LSTM还学习了合理的短语和句子表征,它们对词序敏感,而对主动和被动语态不敏感。作者发现,把作为输入的句子(源句)逆序输入可以显著提高LSTM的性能,因为这样做引入了源句和目标句之间的许多短期依赖关系,使得优化问题更容易。
研究背景:尽管深度神经网络的功能很强大,但它只能被应用于输入和输出可以用固定维度的向量进行编码的问题,这对于一些不能提前预知被表示的序列长度的任务来说是一个限制。例如:语音识别和机器翻译等任务。
研究内容:该论文提出了一个端到端的方法(end-to-end)用于处理序列到序列的任务,使用的模型结构基于LSTM,先使用一个LSM读取输入序列(逆序输入,比如abc,实际输入cba,LSTM的一个有用的特性是,不受限于句子的长度,能够将不同长度的句子映射到一个固定维度的向量。),一次一个时间步长,以此来获得大的固定维度的向量表示。 其次使用另一个LSTM(本质上是个语言模型,初始状态是输入序列被编码得到的向量)来解码该向量,并得到输出序列。LSTM能够学习长时间具有依赖关系的任务,因此正适用于序列到序列任务。
模型介绍:实际模型有三个值得注意的方面。
(1)作者使用了两种不同的lstm:一个用于输入序列,另一个用于输出序列,因为这样做可以以可忽略的计算代价增加数字模型参数,并使同时在对多个语言上训练LSTM很自然。
(2)作者发现深层LSTMs明显优于浅层LSTM,所以我们选择了一个四层的LSTM。
(3)作者将输入句子的单词逆序输入,这种简单的数据转换极大地提高了该模型的性能。
实验结果:
(1)模型对句子中词的先后顺序较为敏感,但是对其语态并不敏感。

图清楚地表明,John和Mary的顺序颠倒以后,并没有很好的聚合到一起,倒是admires和is in love with能聚合到一起,表示对单词的顺序敏感,而对语态相当不敏感
(2)LSTM在长句子上表现得很好,如下图所示。
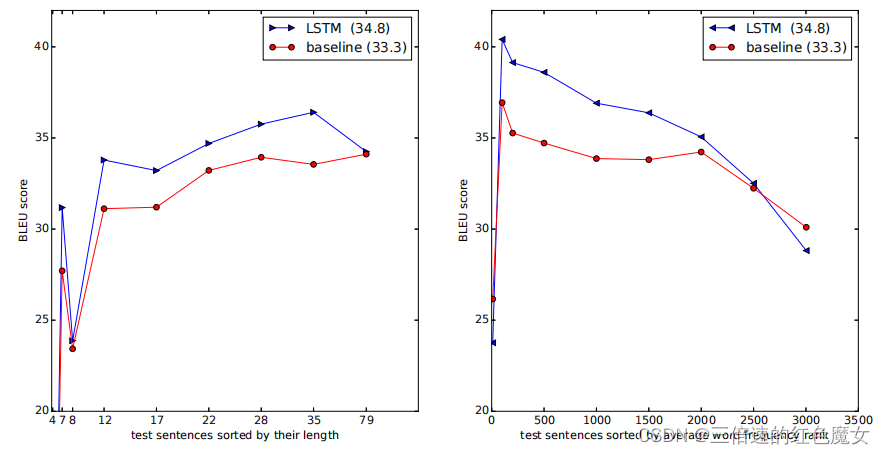
左边的图显示了作者的系统随着句子长度增加表现出的性能,其中x轴对应于按其长度排序的测试句子,并由实际序列长度标记。小于35个单词的句子没有退化,最长的句子只有轻微的退化。
右图呈现的就是对那些比较生僻的句子(句子中单词在词表中的排序的平均值靠后),模型的泛化能力,可以看到模型下降的趋势还是比较明显的。
研究贡献
(1).作者提出的这套seq2seq的框架,为后续的序列映射任务奠定了基础。
(2).作者将输入句子的单词逆序输入,这种简单的数据转换极大地提高了模型的性能。
一维无限深势阱中粒子波函数的差分推导
浅浅的研究了量子力学的波函数推导,本来不打算写了,推都推了,希望能为一些从事该方向的读者提供一点点帮助,如果觉得推导的过程有问题或者不够严谨,希望能给我提一些意见,感谢!
介绍几个要用到的公式:
一维薛定谔方程

约化普朗克常数


令初值为 m=h/2Π,定义域为[0,1], 在定义域内时,v=0,则波函数的边界条件为
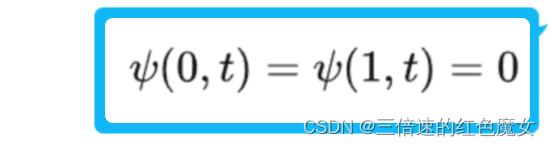
下面开始推导
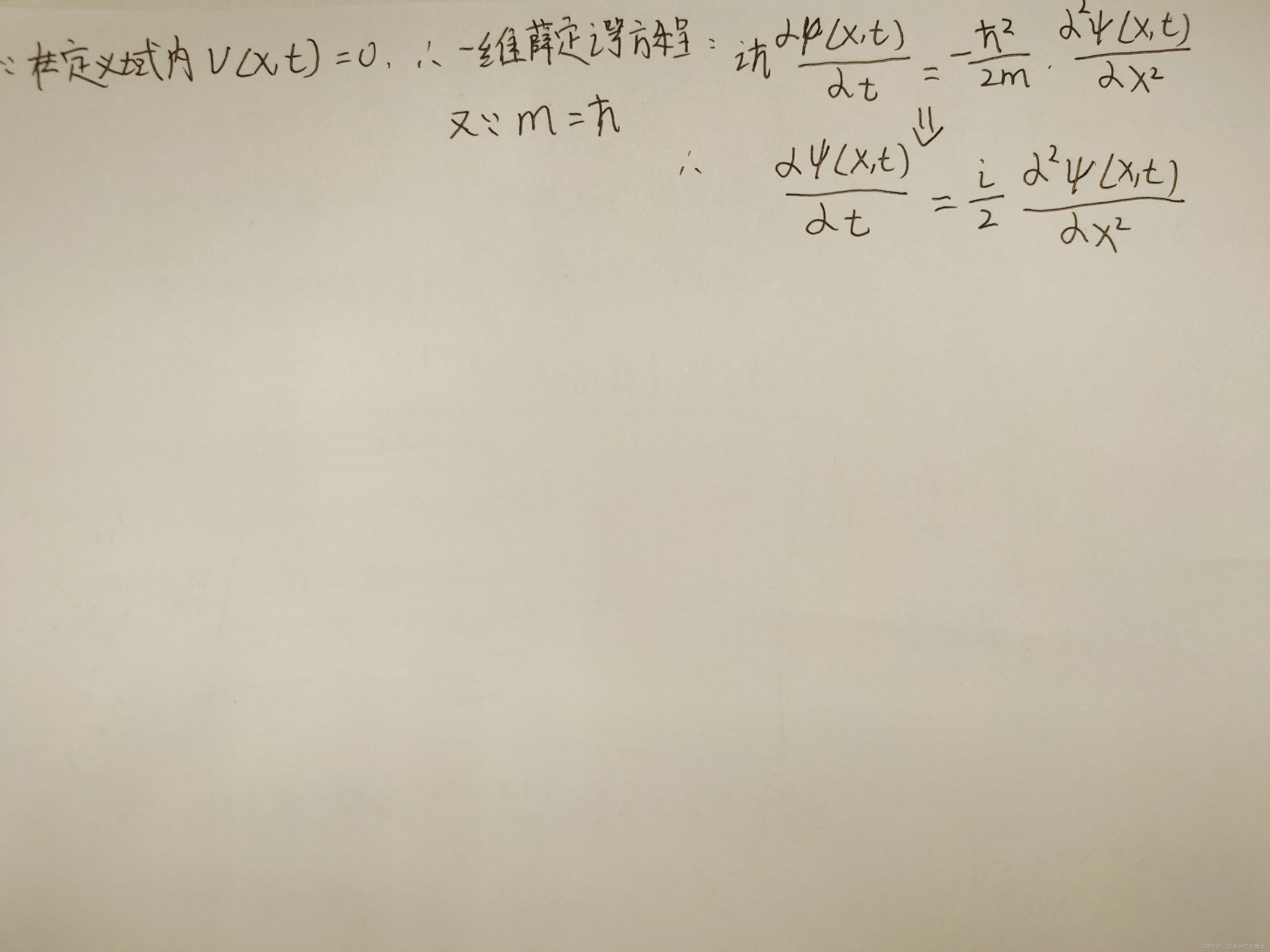
对空间进行离散,即把式子右边用差分形式展开
对时间进行离散,即把式子右边用差分形式展开

到这里还不能得到最后的结果,因为该式子把误差项去掉了,此种求解方法的时间差分只有一阶精度。为了提高精度,这里使用三阶龙格库塔方法,对真正的斜率进行多项式逼近。
先介绍这里用到的三阶龙格库塔的公式
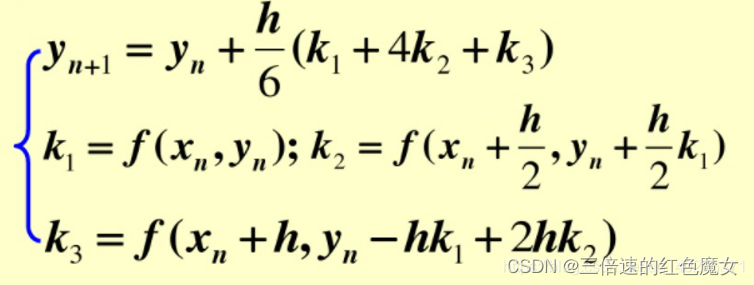
计算如下:

下图表示了该式子的迭代关系,即若已知前一时刻各点的值及空间边界处的值,即可得到下一时刻某点的值。依次类推,可以得到各个时刻的波函数在各个节点处的值。
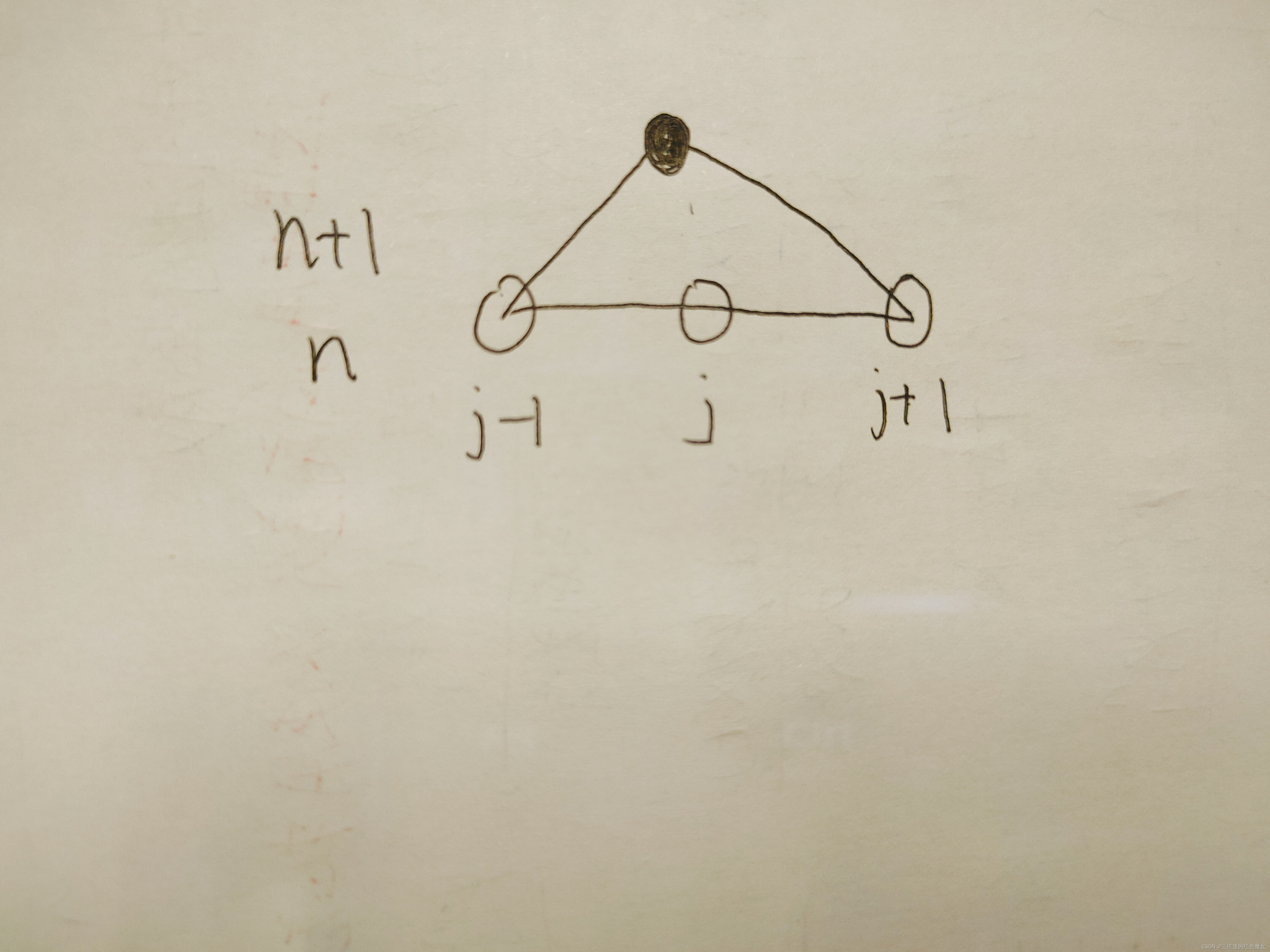
(n代表时间,j代表空间)
总结
本周主要学习了RNN结构的变体以及波函数的差分推导,下周将会研究如何用RNN结构实现波函数以及学习RNN相关的变体结构。















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









