







在深度学习中通常会定义一个loss_function,一旦有loss_function,就可以定义优化函数,去找到最小损失。在这个过程中损失函数一般被称为优化函数的目标函数。训练误差就是训练过程中的误差是基于训练数据集得到的误差得到的损失,得到模型之后再去看他的泛化能力。为了得到靠谱的模型就会使用优化算法减少误差。
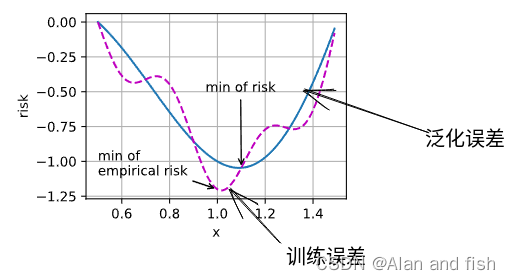
为了说明优化目标的差异,定义了2个方法,就是经验风险和风险,就类似于训练集的平均损失和整个训练集的预期损失。
-
解析解:就是通过一个函数得到的精确的解
-
数值解:使用数值方法得到的一个近似的解
在deeplearn中由于模型的复杂,一般都得不到准确的解析解,一般都是用数值解代替解析解。 -
局部最优解:相当于数学中的极大值和极小值
-
全局最优解:但当于数组中的最小值

-
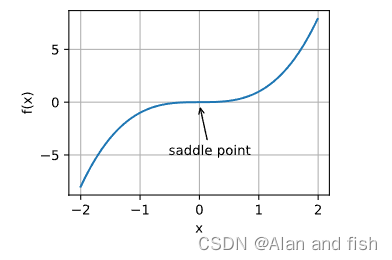
鞍点:是梯度消失的一个重要原因,例如图中在求导的时候,这个点的导数都为0,但是既不是局部最优解,也不是全局最优解。但是优化随着梯度消失就会结束了。
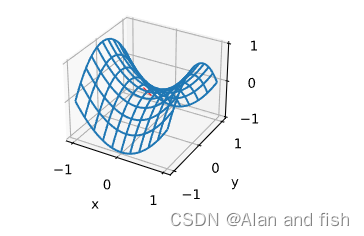
更高维度的鞍点,对应的就是一个面,如下图所示,这个面构成的图形就类似于一个马鞍。
-
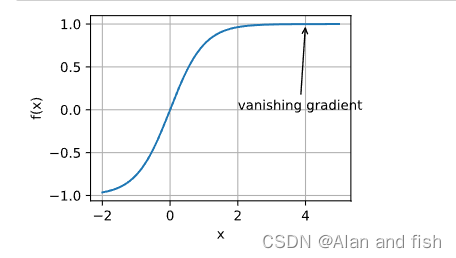
梯度消失:某一个区间的导数接近于0,没有办法继续优化,这就称为梯度消失。















 1962
1962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









