







一、论文核心
在特征金字塔(FPN)中加入自适应结构特征融合模块,使其自适应地学习每个尺度特征图的融合空间权重
二、网络结构
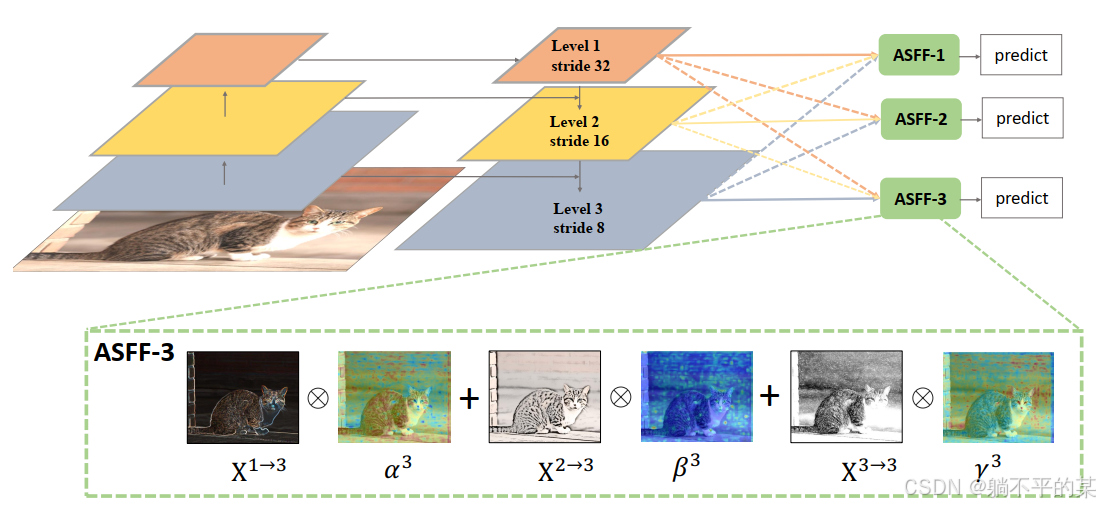
其代码实现如下:
def add_conv(in_ch, out_ch, ksize, stride, leaky=True):
"""
Add a conv2d / batchnorm / leaky ReLU block.
Args:
in_ch (int): number of input channels of the convolution layer.
out_ch (int): number of output channels of the convolution layer.
ksize (int): kernel size of the convolution layer.
stride (int): stride of the convolution layer.
Returns:
stage (Sequential) : Sequential layers composing a convolution block.
"""
stage = nn.Sequential()
pad = (ksize - 1) // 2
stage.add_module('conv', nn.Conv2d(in_channels=in_ch,
out_channels=out_ch, kernel_size=ksize, stride=stride,
padding=pad, bias=False))
stage.add_module('batch_norm', nn.BatchNorm2d(out_ch))
if leaky:
stage.add_module('leaky', nn.LeakyReLU(0.1))
else:
stage.add_module('relu6', nn.ReLU6(inplace=True))
return stage
class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
self.dim = [512, 256, 256]
self.inter_dim = self.dim[self.level]
if level==0:
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 1024, 3, 1)
elif level==1:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==2:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_resized =F.interpolate(x_level_1, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out三、参考内容
ASFF:Learning Spatial Fusion for Single-Shot Object Detection

















 7821
7821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









