







selenium自动化架构
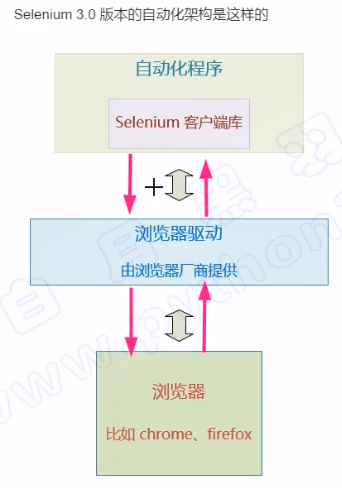
如何构建http消息发送给浏览器?
如何从http响应消息中提取呢?
selenium 客户端库--->支持多种语言:python、java
一、安装:
客户端库+浏览器驱动
1、安装客户端库 
2、安装浏览器驱动
建议:chrome
下载驱动地址,并根据版本号对应:http://chromedriver.storage.googleapis.com/index.html
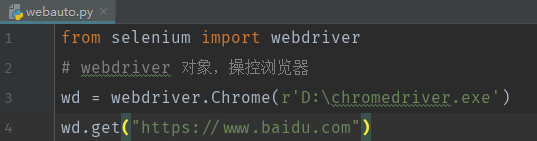
3、打开浏览器,打开网址
二、选择元素的基本方法
1、选择元素的特征:F12
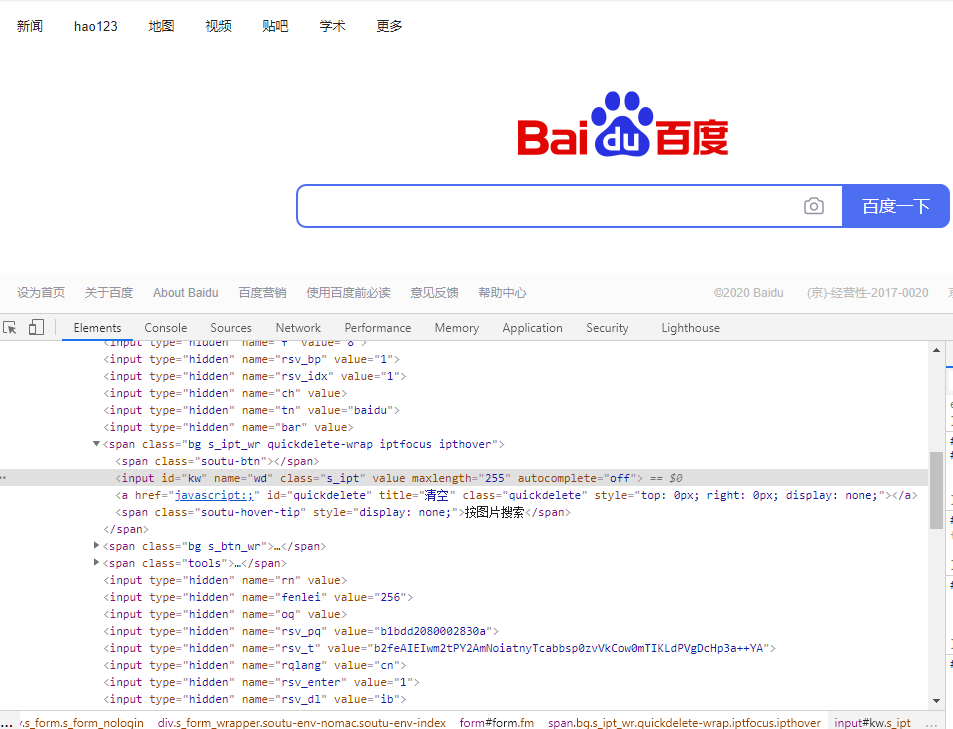
2、确定唯一性:
1)根据id确定元素(常用)

运行原理:浏览器,找到id为kw的元素后,将结果通过浏览器驱动返回给自动化程序,所以find_element_by_id方法会返回一个WebElement类型的对象,通过这个对象操控对应的界面元素(调用对象的send_keys、click方法等)
2)根据class属性、tag名选择元素
eg:对应html内容有如下的部分

根据class名确定元素
eg:如果我们要选择所有的动物,就可以使用方法 find_elements_by_class_name
注意 elements是获取所有的,element获取的是第一个
from selenium import webdriver
# webdriver 对象,操控浏览器
wd = webdriver.Chrome(r'D:\chromedriver.exe')
# wd.get("https://www.baidu.com")
wd.get('http://cdn1.python3.vip/files/selenium/sample1.html')
# 根据 class name 选择元素,返回的是 一个列表
# 里面 都是class 属性值为 animal的元素对应的 WebElement对象
elements = wd.find_elements_by_class_name('animal')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)运行结果:

根据tag名选择元素
eg:我们选择所有的tag名为div的元素
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象
elements = wd.find_elements_by_tag_name('div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)小结:find_element和find_elements区别:使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
3)通过WebElement对象选择元素
注意:WebDriver对象选择元素的范围是整个Web页面,而WebElement对象选择元素的范围是该元素的内部
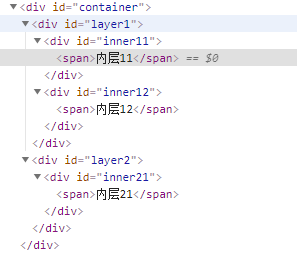
eg:有这样一段代码、获取元素id为container元素的内部,并打印网页元素文本
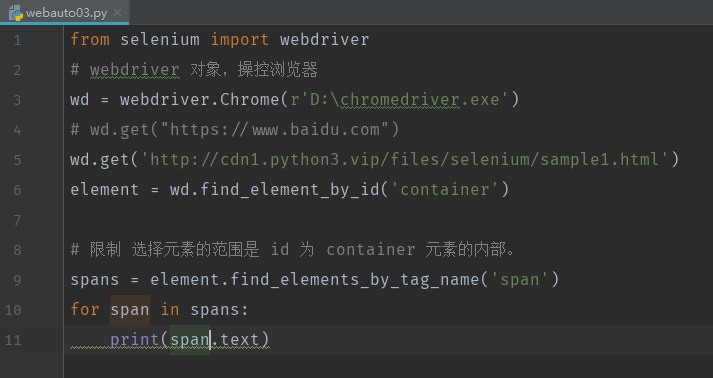
运行结果:
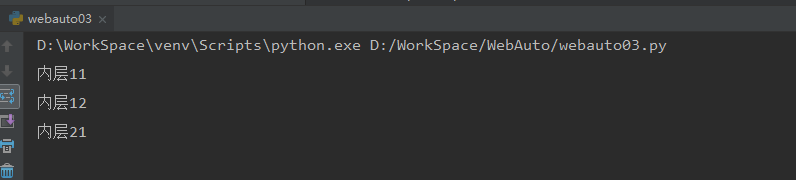
4)等待页面元素出现:当代码执行速度比服务器响应速度快,服务器还没来得及返回搜索结果,我们就继续运行程序,容易出现异常:NoSuchElementException
两种方法:sleep and implicitly_wait
eg1:
from selenium import webdriver
wd = webdriver.Chrome(r'D:\chromedriver.exe')
wd.get('https://www.baidu.com')
element = wd.find_element_by_id('kw')
element.send_keys('黑羽魔巫宗\n')
# 等待 2 秒
from time import sleep
sleep(2)
# 2 秒 过后,再去搜索
element = wd.find_element_by_id('1')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
eg2:
from selenium import webdriver
wd = webdriver.Chrome(r'D:\chromedriver.exe')
wd.implicitly_wait(10)
wd.get('https://www.baidu.com')
element = wd.find_element_by_id('kw')
element.send_keys('黑羽魔巫宗\n')
element = wd.find_element_by_id('1')
print (element.text)
利弊分析: 第一种方法,无法准确确定休眠时间,时间设置过长容易造成时间浪费,时间设置过短达不到效果,第二种方法的解决原理是:当发现找不到元素时,并不立即返回找不到元素的错误,而是周期性重新寻找该元素,直到元素找到,或者超过指定最大等待时长,就会抛出异常
三、操控元素的基本方法
1、点击元素
element.click()
2、输入框
element.send_keys()
3、清除内容
element.clear()
4、获取元素信息
print(element.text)
5、获取元素属性
element.get_attribute('class')
6、获取整个元素对应的html
element.get_attribute('outerHTML')
7、获取某个元素内部的HTML文本内容
element.get_attribute('innerHTML')
8、获取输入框里面的文字
element.get_attribute('value')
9、获取元素文本内容
element.get_attribute('innerText')
element.get_attribute('textContent')
四、CSS元素定位
1、CSS Selector 语法选择元素
1)find_element_by_css_selector(CSS Selector参数)
2)find_elements_by_css_selector(CSS Selector参数)
2、根据tag名、id、class选择元素
1)根据tag名
elements = wd.find_elements_by_css_selector('div')
等价于
elements = wd.find_elements_by_tag_name('div')
2)根据id,选择语法是
element = wd.find_element_by_css_selector('#searchtext')
3)根据class名,语法是.class
elements = wd.find_elements_by_css_selector('.animal')
3、选择子元素和后代
eg:
<div id='container'>
<div id='layer1'>
<div id='inner11'>
<span>内层11</span>
</div>
<div id='inner12'>
<span>内层12</span>
</div>
</div>
<div id='layer2'>
<div id='inner21'>
<span>内层21</span>
</div>
</div>
</div>
解析:1)id=container直接包含id为layer1和layer2,后者是前者的直接子元素
2) id 为 container 的div元素来说, id 为 inner11 、inner12 、inner22 的元素 和 两个 span类型的元素 都不是 它的直接子元素, 因为中间隔了 几层。虽然不是直接子元素, 但是 它们还是在 container 的内部, 可以称之为它 的 后代元素
语法:
1)如果元素2是元素1的直接子元素,语法:元素1>元素2
2)如果元素2是元素1的后代元素,语法:元素1 元素2
4、根据属性选择
1)选择 属性href值为 http://www.miitbeian.gov.cn 的元素
element = wd.find_element_by_css_selector('[href="http://www.miitbeian.gov.cn"]')
2)限制标签名:比如 div[class='SKnet'] 表示 选择所有 标签名为div,且class属性值为SKnet的元素。其中单引号、双引号均可以
3)包含:要选择a节点,里面的href属性包含了 miitbeian 字符串
a[href*="miitbeian"]
4)选择以某个字符串开头
a[href^="http"]
5)选择以某个字符串结尾
a[href$="gov.cn"]
6)多个属性限制:div[class=misc][ctype=gun]
5、验证唯一性
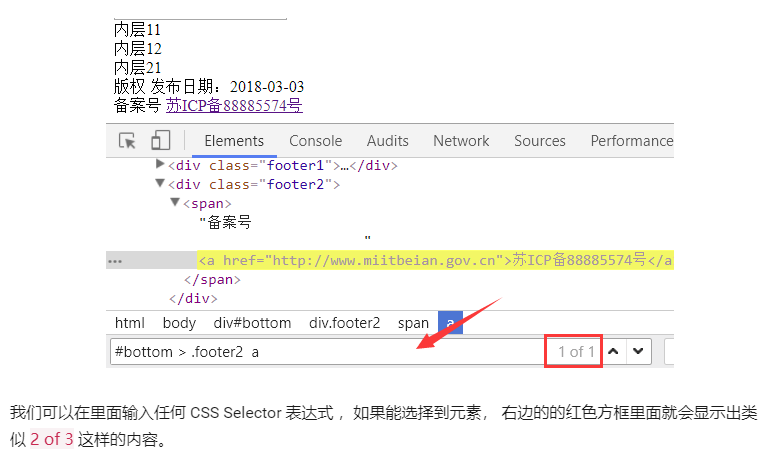
其中第几个元素of总共选择几个元素
6、选择语法联合使用
eg: 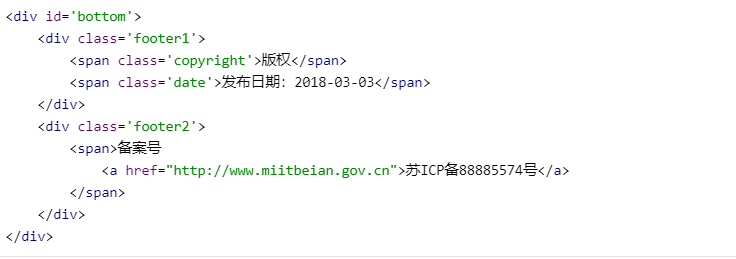
选择<span class='copyright'>版权</span>
div.footer1 > span.copyright
7、组选择
eg:同时选择所有class为plant和class为animal的元素
.plant , .animal
8、按次序选择节点
1)我们可以指定选择的元素 是父元素的第几个子节点,使用 nth-child
2)选择的是父元素的 倒数第几个子节点 ,使用 nth-last-child
p:nth-last-child(1)
3)选择父元素第几个某类型的子节点:nth-of-type
4)选择父元素的 倒数第几个某类型 的子节点,使用 nth-last-of-type
5)如果要选择的是父元素的 某类型偶数节点,使用 nth-of-type(even)
6)如果要选择的是父元素的 某类型奇数节点,使用 nth-of-type(odd)
7)如果要选择是 选择 h3 后面所有的兄弟节点 span,可以这样写 h3 ~ span
五、frame窗口切换
1、嵌入iframe里的元素定位需要切换到可操作范围内,使用swtich_to,其中frame_reference是frame元素的name或者id
wd.switch_to.frame(frame_reference)
2、切出iframe
wd.switch_to.default_content()
3、切换到新的窗口
for handle in wd.window_handles:
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if 'Bing' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break4、进入新窗口操作后需回到原窗口,可以事先保留老窗口的句柄
# mainWindow变量保存当前窗口的句柄
mainWindow = wd.current_window_handle5、切换到新窗口操作后,返回原来窗口
#通过前面保存的老窗口的句柄,自己切换到老窗口
wd.switch_to.window(mainWindow)六、选择框
1、radio
# 获取当前选中的元素
element = wd.find_element_by_css_selector(
'#s_radio input[checked=checked]')
print('当前选中的是: ' + element.get_attribute('value'))
# 点选 小雷老师
wd.find_element_by_css_selector(
'#s_radio input[value="小雷老师"]').click()2、checkbox框
# 先把 已经选中的选项全部点击一下
elements = wd.find_elements_by_css_selector(
'#s_checkbox input[checked="checked"]')
for element in elements:
element.click()
# 再点击 小雷老师
wd.find_element_by_css_selector(
"#s_checkbox input[value='小雷老师']").click()3、select单选框
# 导入Select类
from selenium.webdriver.support.ui import Select
# 创建Select对象
select = Select(wd.find_element_by_id("ss_single"))
# 通过 Select 对象选中小雷老师
select.select_by_visible_text("小雷老师")4、select多选框
# 导入Select类
from selenium.webdriver.support.ui import Select
# 创建Select对象
select = Select(wd.find_element_by_id("ss_multi"))
# 清除所有 已经选中 的选项
select.deselect_all()
# 选择小雷老师 和 小凯老师
select.select_by_visible_text("小雷老师")
select.select_by_visible_text("小凯老师")















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









