







使用C++实现的简单ANN(人工神经网络)
github地址
使用C++实现的最简单的人工神经网络,包含梯度下降的反向传播算法(BP)。内有部分注释,适合初学学习。至于为什么不用python?还是觉得从最底层(矩阵运算)写比较能加深印象和对算法的理解。(绝对不是因为我不会写python)
警告,此代码仅为初学学习之用,请勿用作任何工程项目!
一、跑起来
方式一
使用vscode+cmake插件或者Clion打开目录。然后直接编译运行。
方式二
1、确保安装cmake环境,没有请先装cmake。
2、在工程目录下键入:
mkdir build
cd build
cmake ..
make
3、运行build目录下的ANN程序
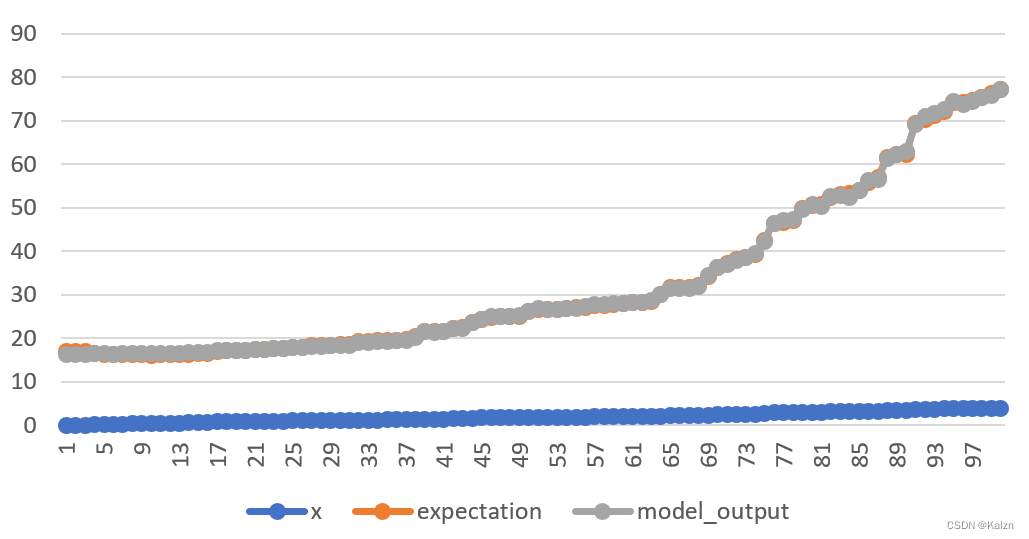
然后在data目录下生成文件output.csv,这是一个回归函数
f
(
x
)
=
5
(
x
2
−
x
+
3.5
)
f(x)=5(x^2-x+3.5)
f(x)=5(x2−x+3.5)的拟合。
拟合情况如下:
二、用起来
1、使用十分简便,首先新建ANN模型,设置误差函数cost及其对于输出层每一项的偏导,这里使用默认的平方差函数
ANNModel model;
model.cost = Sqrt_Cost_Func::sqrt_cost;
model.d_cost = Sqrt_Cost_Func::d_sqrt_cost;
1、设置学习率(一般0.0001~0.1)
model.learning_rate = 0.01;
2、开始添加层级,从输入层开始,直到输出层,这里请保证输入层的神经元个数与输入向量的维度相同。并设置这些层级的激活函数和其导数。
// 输入层 1个神经元
ANNLayer layer0(1);
layer0.activition = Linear_Func::linear; // 设置本层激活函数为线性函数f(x)=x
// 根据ANN结构,输入层的激活函数应设置为线性
layer0.d_activition = Linear_Func::linear;// 设置本层激活函数的导数
model.add_layer(layer0);
// 隐藏层 20个神经元
ANNLayer layer1(20);
layer1.activition = Signmod_Func::signmod; // 设置本层激活函数为sigmod
layer1.d_activition = Signmod_Func::d_signmod;
model.add_layer(layer1);
// 输出层1个神经院
ANNLayer layer2(1);
layer2.activition = Linear_Func::linear;
layer2.d_activition = Linear_Func::d_linear;
model.add_layer(layer2);
3、编译模型
Compiled_ANNModel compiled_model = model.compile();
4、训练模型,查看输出
Vector data, expectation;
Vector output = compiled_model.feed(data, expectation);
5、只输出,不训练
Vector output = compiled_model.get_output(data);
三、学起来
这里给出最终公式,公式的推导请见其他教程、参考书。
1、获得神经元的激活值,这里使用
a
j
(
l
)
a^{(l)}_j
aj(l)表示第
l
l
l层的第
j
j
j个神经元的激活值大小
a
j
(
l
)
=
A
(
l
)
(
z
j
(
l
)
)
a^{(l)}_j=A^{(l)}(z^{(l)}_j)
aj(l)=A(l)(zj(l))
其中
z
j
(
l
)
=
∑
k
=
0
n
(
l
−
1
)
−
1
w
j
,
k
(
l
)
a
k
(
l
−
1
)
+
b
j
(
l
)
z^{(l)}_j=\sum_{k=0}^{n^{(l-1)}-1}w_{j,k}^{(l)}a^{(l-1)}_{k}+b^{(l)}_j
zj(l)=k=0∑n(l−1)−1wj,k(l)ak(l−1)+bj(l)
其中
A
(
l
)
A^{(l)}
A(l)为第
l
l
l层的激活函数,
w
j
,
k
(
l
)
w_{j,k}^{(l)}
wj,k(l)为从
l
−
1
l-1
l−1层第
k
k
k个神经元链接到第
l
l
l层第
j
j
j个神经元的边权(注意
w
w
w下标的顺序!),另外
b
j
(
l
)
b^{(l)}_j
bj(l)是第
l
l
l层第
j
j
j个神经元的偏置阈值。
n
(
l
)
n^{(l)}
n(l)为第
l
l
l层的神经元个数。
2、反向传播公式(以平方差误差函数为例)
σ C σ w j , k ( l ) = a k ( l − 1 ) A ′ ( l ) ( z j ( l ) ) σ C σ a j ( l ) \frac{\sigma C}{\sigma w_{j,k}^{(l)}} = a^{(l-1)}_{k}A^{'(l)}(z^{(l)}_j)\frac{\sigma C}{\sigma a^{(l)}_{j}} σwj,k(l)σC=ak(l−1)A′(l)(zj(l))σaj(l)σC
其中
σ C σ a j ( l ) = { ∑ j = 0 n ( l + 1 ) − 1 w j , k ( l + 1 ) A ′ ( l + 1 ) ( z j ( l + 1 ) ) σ C σ a j ( l + 1 ) l ≠ L 2 ( a j ( l ) − y j ) l = L \frac{\sigma C}{\sigma a^{(l)}_{j}} =\left\{ \begin{aligned} \sum_{j=0}^{n^{(l+1)}-1} w_{j,k}^{(l+1)}A^{'(l+1)}(z^{(l+1)}_j)\frac{\sigma C}{\sigma a^{(l+1)}_{j}} \quad l \neq L\\ 2(a^{(l)}_j-y_j) \quad l = L\\ \end{aligned} \right . σaj(l)σC=⎩ ⎨ ⎧j=0∑n(l+1)−1wj,k(l+1)A′(l+1)(zj(l+1))σaj(l+1)σCl=L2(aj(l)−yj)l=L
最终有
Δ w j , k ( l ) = − η σ C σ w j , k ( l ) \Delta w_{j,k}^{(l)}=-\eta \frac{\sigma C}{\sigma w_{j,k}^{(l)}} Δwj,k(l)=−ησwj,k(l)σC
Δ b j ( l ) = − η A ′ ( l ) ( z j ( l ) ) σ C σ a j ( l ) \Delta b_{j}^{(l)}= -\eta A^{'(l)}(z^{(l)}_j)\frac{\sigma C}{\sigma a^{(l)}_{j}} Δbj(l)=−ηA′(l)(zj(l))σaj(l)σC
最后对 w w w、 b b b进行更新如下
w
j
,
k
(
l
)
:
=
w
j
,
k
(
l
)
+
Δ
w
j
,
k
(
l
)
w_{j,k}^{(l)} := w_{j,k}^{(l)} + \Delta w_{j,k}^{(l)}
wj,k(l):=wj,k(l)+Δwj,k(l)
b
j
,
k
(
l
)
:
=
b
j
(
l
)
+
Δ
b
j
(
l
)
b_{j,k}^{(l)} := b_{j}^{(l)} + \Delta b_{j}^{(l)}
bj,k(l):=bj(l)+Δbj(l)
其中, A ′ ( l ) ( x ) A^{'(l)}(x) A′(l)(x)为第 l l l层激活函数的导数。 C C C为误差函数, y j y_j yj为预期输出向量的 j j j分量。 η \eta η为学习率。
具体实现的解释请,见代码注释。














 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









