









note
- 长文本训练的难点:
- 2024年初很多框架优化显存:megatron 的 pipeline_parallel 和 tensor_parallel 、deepspeed 的 zero 技术、offload,gradient checkpoint、混合精度等,但是治标不治本
- 如果优化不了 seq_len * seq_len 这个量级的参数量,那么 long-context llm 是必然没法训练的。然而 attention 层的 softmax 操作,又要求模型必须在一张 GPU 上见到完整的 sequence,这似乎是条死路
- GLM融合packing和sorted batching的优点,提出sorted packing训练方法:根据计算量来构建同一批次内的 Pack,确保同一批次中各个 Pack 数据的计算量相近,从而减少了气泡时间。此外,我们还引入了梯度累积技术,以避免排序带来的偏差
- 长短文本混合 SFT 的高效训练方法主要有两种:Packing 和 Sorted Batching。Sorted Batching 可能会引入某些先验知识,即同一批次内的数据长度趋于一致,这有可能导致不良的训练效果。相比之下,Packing 策略能够直接利用 Flash Attention 的 Varlen 实现,效率较高,因此被 Megatron-LM 等主流训练框架所采用
- 如果只用packing训练,训练时间的波动较为明显
- 加权loss:不同 Pack 包含的数据量不同,可能会导致 loss 计算的不均衡。因此,我们也采用了 Loss Reweighting 策略,对 loss 进行重新平衡
文章目录
一、数据准备和Tokenizer

tokenizer:

二、并行策略
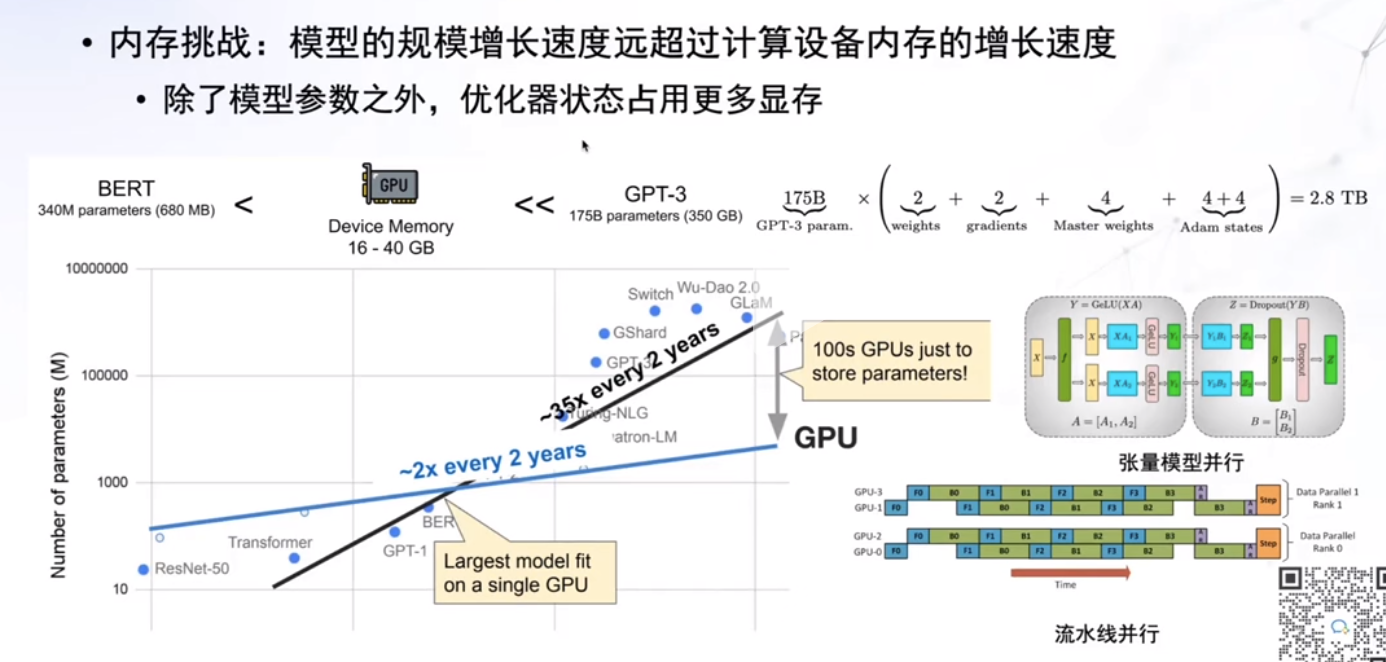
并行策略:
-
原始 3D 并行
- 数据并行 DP
- 进阶 Zero 数据并行
- 张量并行 TP
- 流水线并行 PP
- 数据并行 DP
-
序列并行 SP
-
上下文并行 CP
-
专家并行 EP
LLM的训练pipeline:
- 预训练
- 数据质量 Scaling
- 更好的数据质量,相同算力下更好的模型
- 数据数量 Scaling
- 更多的非重复数据,we need more tokens!
- 训练量 Scaling
- LLAMA:1.4T -> 2T -> 15T
- 数据质量 Scaling
- 对齐
- SFT 很重要,RLxF 更加重要
- 当是效果最好的模型时,RLxF 等方式比 SFT 更能提升模型效果

三、长文本训练流程
1. 训练pipeline

在继续预训练(Continue Pre-Training)、监督微调(SFT)和基于人类反馈的强化学习(RLHF)阶段,我们进行了小心地混合训练,来保持模型在短文本上的通用能力。
- 在继续预训练方面,经过海量 token 的预训练之后,Base Model 具备了卓越的信息捕获和推理能力。为了将这种能力泛化到长文本上,我们需要用少量长文本的 token 对 Base Model 进行继续预训练。这一步对于激发模型处理长文本的能力至关重要。
- 扩充到128k:4B个token的原始分布的预训练语料、上采样3B个超过8k的数据、3B个超过32k的数据
- 扩充到1M:原文长度超过1M的原文本很少,所以将文本进行聚类,将同类数据适当拼接。数据:3.5B个token的原始分布的预训练语料、分别1.5B个超过8k、32k、128k语料、2B个人工长文本语料。
- 注意:每个长度区间的token数量保持一致
- 在 SFT 阶段,我们同样为长文本专门搜集了相应的 SFT 数据,并将这些数据与通用 SFT 数据进行了恰当的混合,以实现训练,确保模型在提升长文本处理能力的同时,保持其通用性。
- 仅标注128K长度以内的数据
- 在 RLHF 阶段,我们采用 DPO 来尽可能降低训练 Infra 所面临的挑战。在此阶段,我们主要需要解决的问题是如何构建长文本 DPO 数据。
- 我们沿用与短文本相同的 Reward 模型来对长文本的答案进行评分。为了防止超出 Reward 模型的上下文限制,我们仅保留了问题和答案,而舍弃了文档等长输入。
- 尝试GLM4-128K 等语言模型作为长文本的 Reward 模型,但效果不好
- 痛点:长文本的reward模型训练数据的标注困难
2. continue pre-training
两阶段:首先,在第一阶段,我们将上下文长度扩展至128K;随后,在第二阶段,再将上下文长度扩展至1M。
主要发现
- 信息捕获与推理能力在预训练阶段获得
- 短距离依赖 泛化到 长距离依赖相对容易,无需过多 token 训练
数据组成
- 预训练数据
- 原始分布的预训练的数据
- 预训练数据增强
- 8k, 32k 等分阶段进行数据上采样
- 预训练数据聚类合并
痛点:在continue pretrain的第二步扩展到1M时,发现超过1M的数据很少,所以需要人造长文本数据(通过聚类,将同类的数据拼接)

continue pretraining训练:
- 调整rope位置编码的base,提高在处理长文本时的位置编码分辨率
- 类似于 Llama 3的预训练阶段,我们实施了带有 Attention 分隔的 Packing 训练策略。以第一阶段 128K 上下文窗口为例,每个训练样本可能由多个不同长度的独立文本组成,这些文本在 Attention 计算过程中互不干扰(采用基于Flash Attention的 Varlen 实现)。这种 Attention 分隔对于激活模型处理长文本的能力至关重要。与直接应用 128K 全注意力相比,它有效避免了建立许多无效的长距离依赖关系。
3. Long SFT数据构造
通过短窗口语言模型(SCM)来构建更长的SFT数据:
- 基于短文本模型构造 Long SFT 数据
- Single chunk self-instruct
- 偏抽取式问题
- 难以保持/激活长距离推理依赖能力
- Multi-chunk self-instruct
- 更能激活长距离推理能力
- 多级摘要
- 具体解释:在给定的文本中,根据摘要总结类任务模板选择一个,将文本分割成多个短于SCM上下文窗口的片段,并要求SCM模型为每个片段生成摘要。最后,将摘要汇总,并根据任务模板的提示生成答案。最终的SFT数据由原始文本、问题和答案拼接组成。
- 长距离多点依赖能力
- Single chunk self-instruct
- 基于长文本模型构造 Long SFT 数据:如self-instruct方式构造数据
- 长文本类型的多样性
- 问题类型的多样性
验证方法:使用标注的128K长度以内的SFT数据训练了一个16K上下文窗口的模型,作为SCM模型,自动生成了新的128K长度的SFT数据。在长文本评测集上,使用新的128K长度SFT数据训练得到的模型与使用标注的128K长度SFT数据训练得到的模型性能相近,说明上面方法有效。
参考论文:longalign
4. SFT训练方式
- Naive batching:
- 速度极慢,bubble time较大
- Sort Batching
- 加入了先验,同 Batch 内长度相近,效果有时候更好
- 梯度累积能够部分缓解先验的影响
- Packing 策略:能够直接利用 Flash Attention 的 Varlen 实现,效率较高,因此被 Megatron-LM 等主流训练框架所采用
- glm使用sorted packing
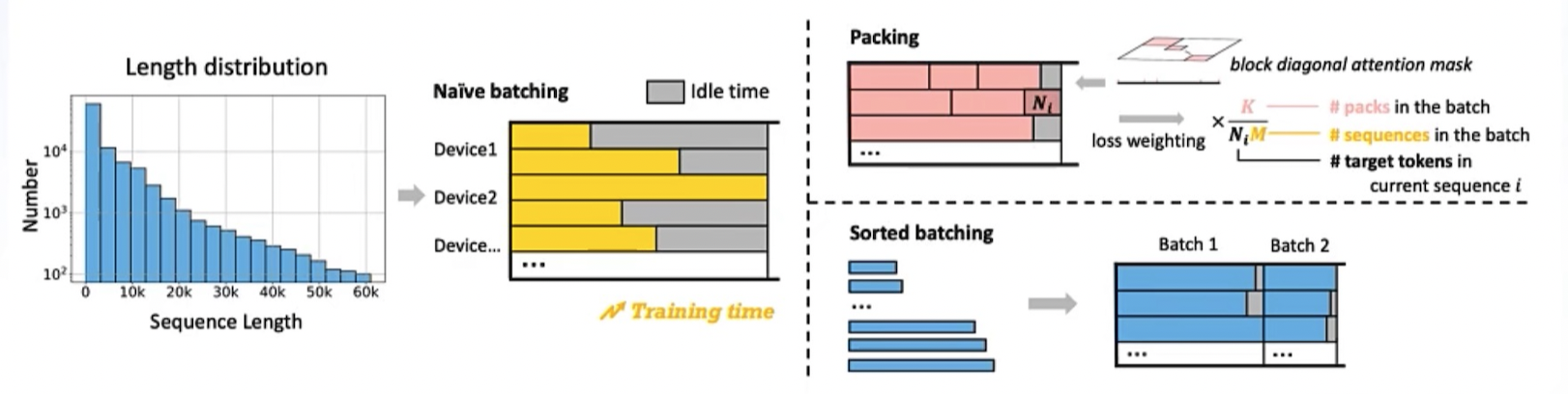
参考:https://github.com/THUDM/LongAlign
5. 训练框架简介
- 大模型长文本训练主要挑战:
- Activation显存显著增大
- 已有的3D并行
- 张量并行TP:通信量过大,不适合超过8
- 流水线并行PP:保证效率需要加microbatch,对activation显存减少无帮助
- 数据并行DP:无帮助
- Activation Checkpointing
- Forward 时可能就已经 OoM,Checkpointing无帮助
新的并行方式:
- Transformer全部的计算中只有Attention不是token独立的
- 序列并行:只对 Attention 部分并行,其余模块类 DP
主要的两种实现:
- Ring Attention (Context Parallel in Magatron-LM)
- DeepSpeed Ulysses
两种实现方式的对比:
-
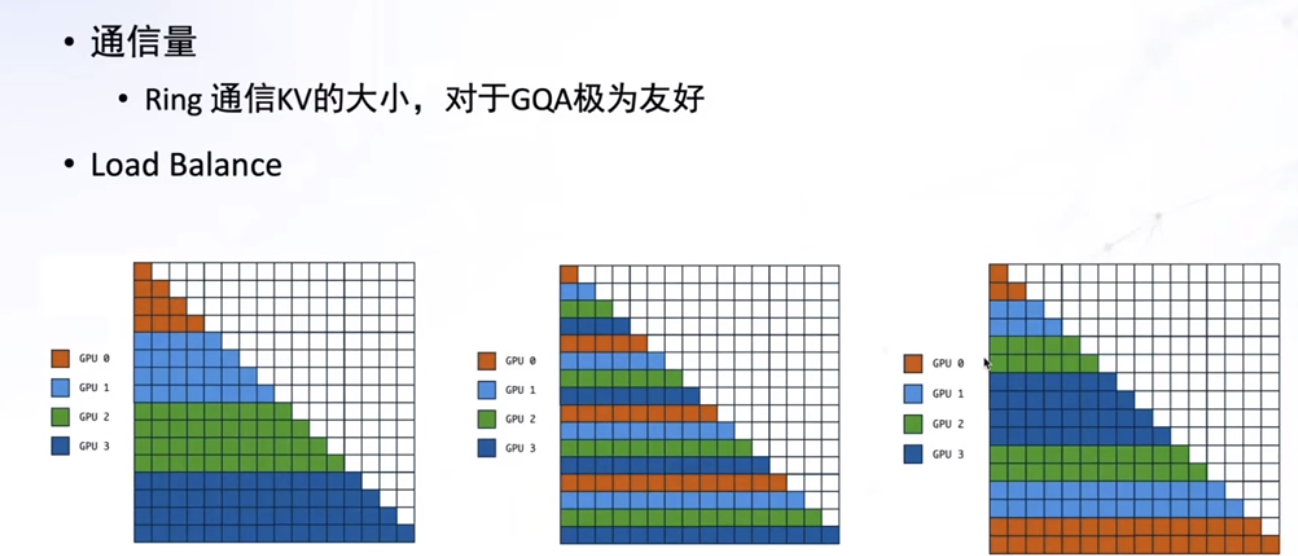
Context Parallel / Ring Attention
- 通信量仅为Group内的KV,通信量较小,所需通信次数较多
- 需要计算和通信的较好掩盖
- 并行度的扩展性比较足,无显著限制
- 对SparseAttention和各类Attention的改动不友好
-
DeepSpeed Ulysses
- 通信量相对较大,通信次数较少
- 并行度相对受限,一般不超过GQA的Group数量
- 所有并行副本需要全部模型参数,和ZeRO-DP适配
- 对各类SparseAttention及Varlen都很友好
6. 模型的评测
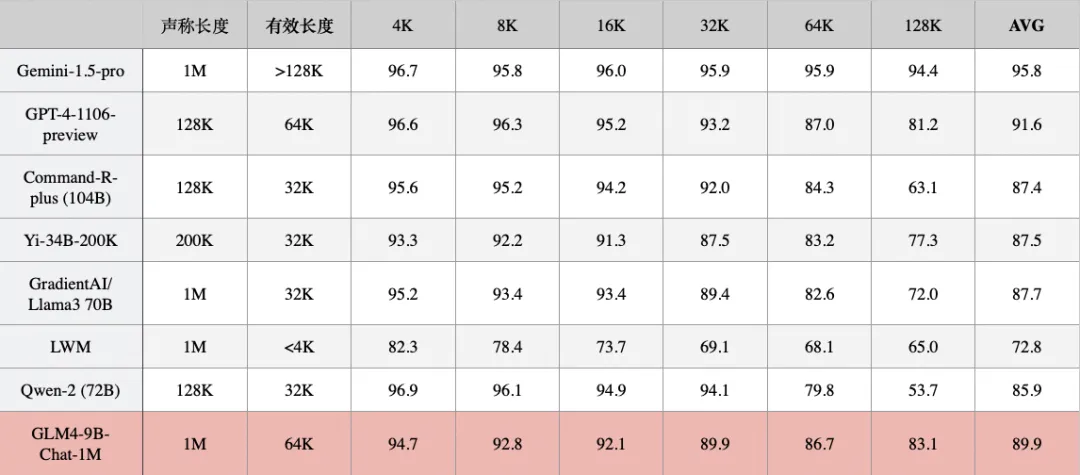
- LongBench, L-Eval, BAMBOO 和 ZeroSCROLLS等评测集:LongBench是128k的评测集(更偏实际场景)、InfiniteBench是100k-200k长度的评测集(有12类任务)、Ruler评估模型的真实上下文长度(如上表)、大海捞针(在长文本中随机插入一个和文本内容无关的sentence,看目标模型能否提取出这个隐藏的sentence)
- 优势
- 基于Datasets或人工标注数据构建,准确性有保障
- 能够自动评测,评测指标相对客观
- 评测样例多,评测方差较小
- 劣势
- 与实际使用场景(文档解读等)Gap较大
- 部分评测指标区分度较小,准确率低
- 优势
- LongBench-Chat
7. 三角的权衡

如何突破:

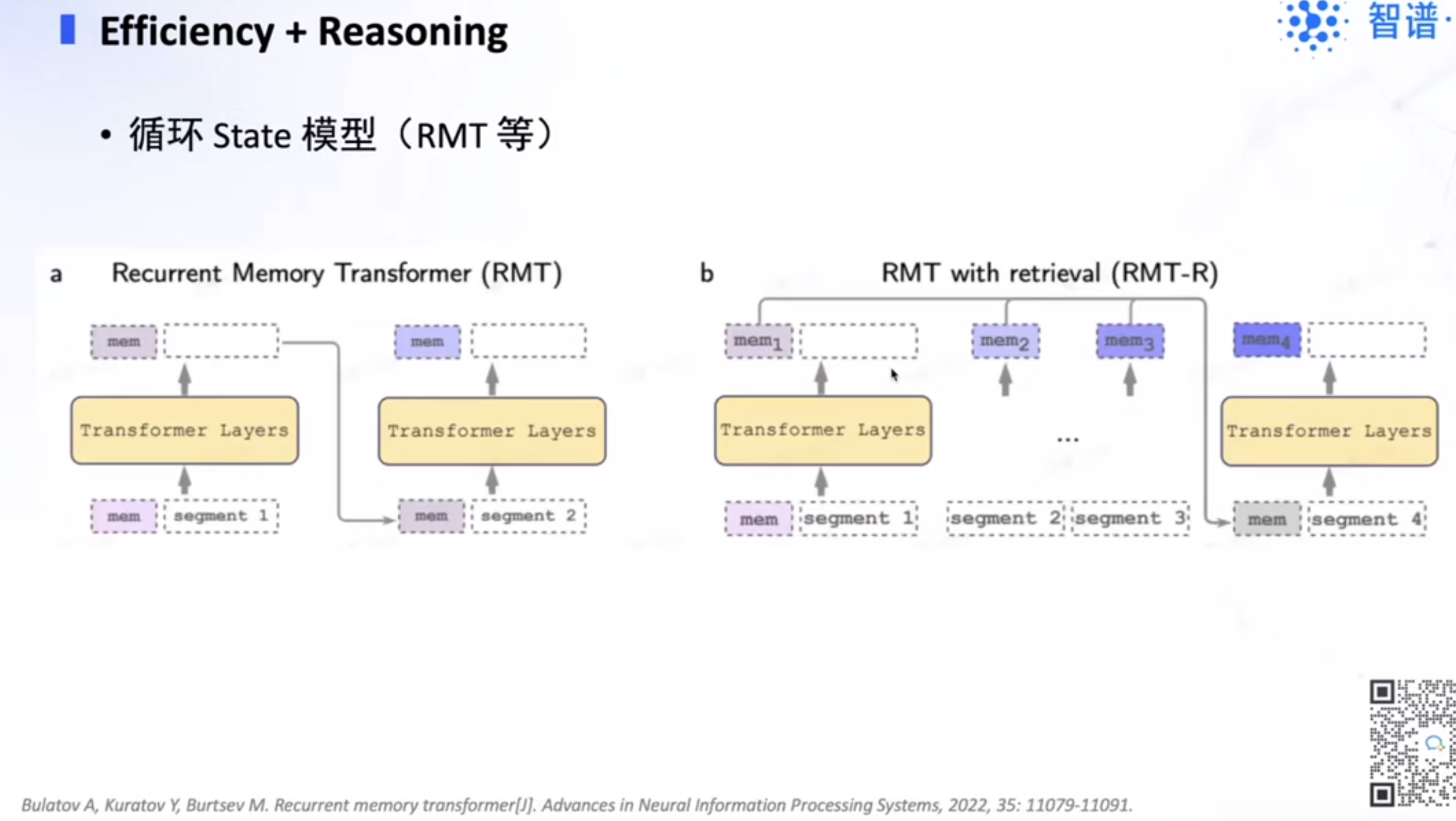
四、长文本训练infra
背景:3D并行策略不足,序列并行被提出,动机为,序列并行仅在 Attention 部分进行并行处理,而在其他模块中,则将一个长序列视为多条数据,类似于数据并行 DP 进行处理。
注:Ring Attention 在 Megatron-LM 中得到了优化实现,并被命名为 Context Parallel。
长文本训练中infra的痛点:中间变量 Activation 的显存占用显著增加
两种实现方式的对比:
-
Context Parallel / Ring Attention
- 通信量仅为Group内的KV,通信量较小,所需通信次数较多
- 需要计算和通信的较好掩盖
- 并行度的扩展性比较足,无显著限制
- 对SparseAttention和各类Attention的改动不友好
-
DeepSpeed Ulysses
- 通信量相对较大,通信次数较少
- 并行度相对受限,一般不超过GQA的Group数量
- 所有并行副本需要全部模型参数,和ZeRO-DP适配
- 对各类SparseAttention及Varlen都很友好
DeepSpeed-Ulysses和Ring-Attention的通信原理示意图:
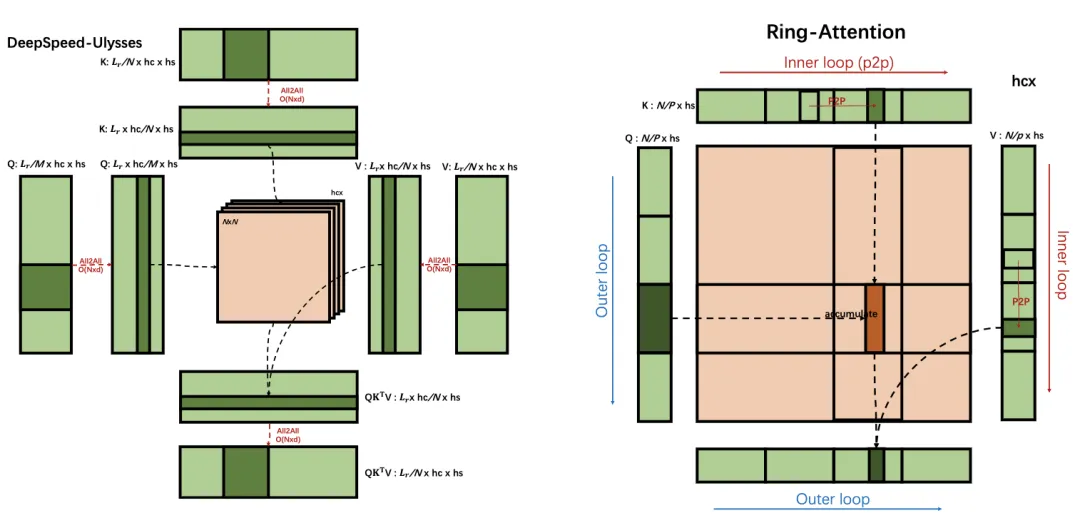
1. Context Parallel / Ring Attention
论文Ring Attention with Blockwise Transformers for Near-Infinite Context (大号的flash attention)
优势:并行度的扩展性较好
劣势: 对Attention 变种不友好,eg.Sparse Attention

- 13B 模型和 7B 模型相比较, 参数只增加了 1 倍, 也就是说我们只要把 pipeline_parallel 的倍数调大一倍, 以前怎么训, 现在就还怎么训, 无非就是 data_parallel 的数量减半了而已(由于有优化器、梯度等额外存储在,显存压力并不是提升一倍这么简单,这里不做过多展开);
- 4 K 的文本和 40 K 的文本, attention 矩阵的大小, 可是相差了 ( 40 ∗ 1024 ) 2 ( 4 ∗ 1024 ) 2 = 100 \frac{(40 * 1024)^2}{(4 * 1024)^2}=100 (4∗1024)2(40∗1024)2=100 倍, 更别说大部分公司可能都在用 400 K 这个量级的长度。
这也就是说,如果优化不了 seq_len * seq_len 这个量级的参数量,那么 long-context IIm 是必然没法训练的。然而 attention 层的 softmax 操作,又要求模型必须在一张 GPU 上见到完整的 sequence, 这似乎是条死路。
(1)sequence_parallel
sequence_parallel (sp) 就是在 sequence 维度上对 tensor 进行切分,放到不同的卡上运算:
batch * seq_len * head_num * head_dim —> batch * ( seq_len / / sp_size ) * head_num * head_dim
这个思路不仅简单,而且在 llama 模型的三件套 ( Attention、 MLP、RMSNorm) 中,后两个模块本身就是只对 tensor 的最后一个维度进行操作,天然支持 sp 并行。
# valid MLP sequence_parallel
import torch.nn as nn
import torch
class MLP(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.act_fn = nn.SiLU()
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
mlp = MLP(10, 20)
x = torch.randn(3, 4, 10)
x1, x2 = x.split(2, dim=1)
assert torch.equal(mlp(x), torch.cat((mlp(x1), mlp(x2)), dim=1))
# valid RMS_norm sequence_parallel
class RMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states
norm = RMSNorm(10)
x = torch.randn(3, 4, 10)
x1, x2 = x.split(2, dim=1)
assert torch.equal(norm(x), torch.cat((norm(x1),norm(x2)), dim=1))
参考:
ring attention + flash attention:超长上下文之路
2. DeepSpeed Ulysses
优势:对Attention 的实现不敏感,适合各种attention方法
劣势:序列并行度不能超过头数
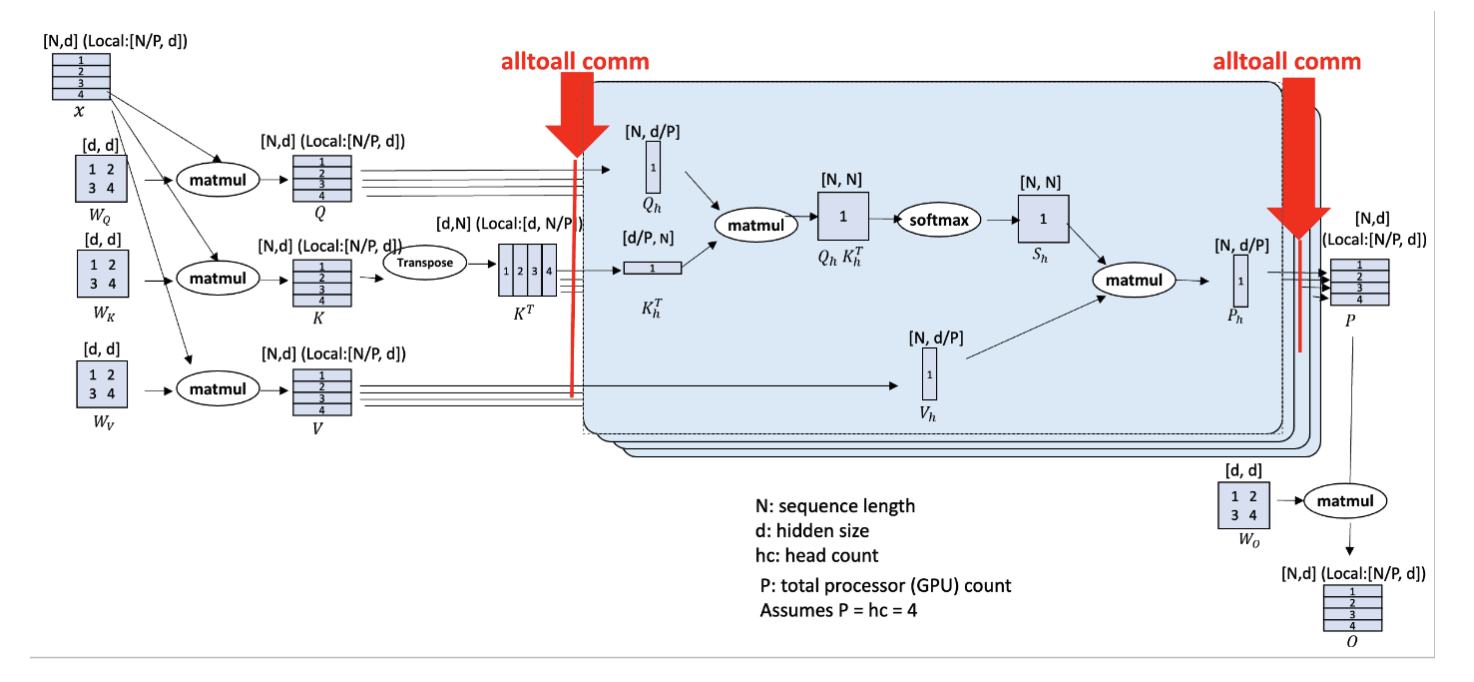
论文DEEPSPEED ULYSSES: SYSTEM OPTIMIZATIONS FOR ENABLING TRAINING OF EXTREME LONG SEQUENCE TRANSFORMER MODELS
- 通信量 & 通信时间
- t = (N * head_num + 2N * group_num) * 128 / PB
- N: 序列长度
- P: 并行度
- Ball to all带宽
- Context Parallel
- t = 2 * 1 * 128 * N / B1
- (head_num + 2 * group_num) / P 一般大于 2
- 缺点
- 对于GQA,并行度大于Group数量时,All-to-all不够,还需要All Reduce额外通信
- 由于不切分参数,需要较大的PP或者Zero3,和TP兼容不够
- 优点
- 不深入改Attention,适配flash attn、Varlen、Sparse Attention等
3. 变长序列并行
为了与主流的 Megatron-LM 训练框架兼容,GLM4-9B-Chat-1M 在训练中采用了 Context Parallel,即 Ring Attention 的序列并行方式。
模型在多数阶段都需要采用 Packing 的变长训练,而这一点在 Ring Attention 中并非原生支持。为了实现变长训练,我们使用了以下三种解决策略。
(1)循环变长
- 对于包含多个序列的 Pack 数据,我们可以将每个序列单独拆分,并循环应用 Ring Attention 来计算每个序列的 Attention 结果。最后,将输出结果按顺序拼接即可。当 Pack 中的序列数量较少时(例如,128K 的 Pack 中包含 4 个 32K 的序列),这种方法的效率较高,因为无需引入额外计算,循环的时间开销相对较小,且每个子序列都能充分利用 GPU 的并行计算能力。
- 当 Pack 中的序列数量较多时(例如,128K 的 Pack 中包含 128 个 1K 的序列),这种方法效率会显著下降。由于每个子序列较短,无法充分利用 GPU 的并行计算能力,循环引入的开销变得不容忽视。
(2)原生变长
- 原生变长序列并行是指对 Ring Attention 进行相应修改,使其能够原生支持变长序列的 Ring Attention 计算。与循环变长相比,这种方法在效率上有了显著提升,无论是 Pack 中包含的子序列多还是少,都能保持高效的计算效率。
- 当上下文长度极长(如 1M)且 Pack 内的子序列长度差异较大时,这种方法的显存占用会大幅增加,显著高于循环变长的实现。因此,我们无法直接使用原生变长的 Ring Attention 来训练具有超长上下文的大语言模型(如 GLM4-9B-Chat-1M)。
(3)分治变长
- 为了克服超长上下文训练的挑战,我们结合了上述两种变长策略,提出了一种新的分治变长序列并行方法。对于包含 128 个子序列的 Pack,我们将其分为若干个子 Pack,例如分为 4 个子 Pack,每个子 Pack 包含若干子序列。在这里,我们会尽量均匀地将子序列分配到各个子 Pack 中。
- 然后,我们分别对每个子 Pack 使用原生变长循环计算输出,最后将 Attention 的输出拼接在一起。分治变长序列并行在充分利用 GPU 并行计算能力的同时,降低了显存的峰值使用,使得变长训练能够扩展到超长上下文的训练中。
五、长文本训练框架的应用
项目:https://github.com/LargeWorldModel/LWM?tab=readme-ov-file
参考:在视频生成领域的应用
[1] 【视频理解】性能吊打GPT4!UC伯克利开源首个理解长视频的世界模型!
[2] 100万token,一次能分析1小时YouTube视频,「大世界模型」火了
[3] 模型篇 | RingAttention:构建百万长度视频和语言的世界模型
[4] 【Attention】UC伯克利的视频理解模型里,近乎无限上下文的RingAttention怎么实现的?
六、长文本生成训练-LongWriter
链接:https://github.com/THUDM/LongWriter
Reference
[1] GLM Long:如何将 LLM 的上下文扩展至百万级
[2] GLM-4-Long:长、无损、理解复杂语义、更便宜
[3] DeepSpeed-Ulysses (SequenceParallel)
[4] ring attention + flash attention:超长上下文之路
[5] 面向超长上下文,大语言模型如何优化架构,综述
[6] 我爱DeepSpeed-Ulysses:重新审视大模型序列并行技术
[7] 腾讯云TACO推出混合序列并行USP,大幅提升LLM和DiT训练性能
[8] https://github.com/Strivin0311/long-llms-learning
[9] Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
[10] https://medium.com/@ChatGLM/glm-long-scaling-pre-trained-model-contexts-to-millions-caa3c48dea85
[11] LLM的分布式并行训练方式总结
[12] kimi chat大模型的200万长度无损上下文可能是如何做到的.zhihu
[13] GLM Long: Scaling Pre-trained Model Contexts to Millions:https://medium.com/@ChatGLM/glm-long-scaling-pre-trained-model-contexts-to-millions-caa3c48dea85
[14] Large Language Model Based Long Context Modeling Papers and Blogs:https://github.com/Xnhyacinth/Awesome-LLM-Long-Context-Modeling?tab=readme-ov-file#21-Sparse-Attention
[15] 某乎:大语言模型是如何在预训练的过程中学习超长文本的呢?
[16] 长文本训练理解
[17] Blockwise Parallel Transformers&Ring Attention论文笔记
附录



















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











