










note
- 增强大模型推理能力的四种范式:推理时间扩展、纯强化学习(RL)、SFT+RL、蒸馏(distillation) 。其实这几种方法本质就是SFT+RL:
- 低成本做事就直接推理时间扩展
- 稍微肯付出成本就蒸馏SFT,顺便搞点高质量COT SFT数据
- 高级点就先用GRPO等RL学习推理能力,在前面也能加个冷启动SFT会更好。但直接纯RL在较小模型可能不奏效。
- 最简单的方式其实是推理时间扩展或者蒸馏,但是这个其实的成功率,其实还是依赖于基座模型本身。
- 小模型直接进行RL未必奏效,将DeepSeek-R1-Zero中相同的纯RL方法直接应用于Qwen-32B,测试纯RL是否可以在比DeepSeek-R1-Zero小得多的模型中诱导推理能力。结果表明,对于较小的模型,蒸馏比纯强化学习更有效。
- 使用高质量推理数据进行SFT在使用小模型时可能是一种更有效的策略。https://arxiv.org/abs/2501.12948
- 判断是否适合使用RL的原则:越难标注(或定义)好答案的任务,越适合 RL。
- 人们越难标注的任务(比如数学题,代码题),用 RL 的 ROI 是越高的。这种「很难产生好答案,但很容易进行判别结果是否正确」的任务,是 RLer 最喜欢的任务场景!
- 绝大多数任务是不存在「标准答案」的(这意味着大概率需要训练一个 RM),在这类任务下抉择是否要使用 RL 往往比较困难。判断:那些「宏观标准容易定义,但细节难以精确」的任务,比较适合 RL。比如数据的标准没法一步理想化确定的情况,我们应该在满足 High Level 的大标准前提下,只比较模型生成结果的好坏。
- 训RL需要强大的心理准备(包括但不局限于训练框架、调参稳定、Reward Hacking 这些问题)
文章目录
零、推理LLM模型
现在大多数被称为推理模型的LLMs在其回复中都包含一个“思考”或“思维”过程。

推理模型旨在擅长解决复杂任务,如解决谜题、高级数学问题和具有挑战性的编程任务。然而,对于简单的任务(如摘要、翻译或基于知识的问题回答)并不是必需的。如果将推理模型用于所有任务,会导致效率低下且昂贵,并且有时由于“过度思考”而更容易出错。

一、推理时间扩展(Inference-time scaling)
推理时间扩展 ,一种无需训练或以其他方式修改底层模型即可提高推理能力的技术。推理时间扩展不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增加,大规模部署的成本会更高。不过,对于已经很强大的模型来说,提高性能仍然是明智之举。o1可能利用了推理时间扩展,这有助于解释为什么与DeepSeek-R1相比,它在每token基础上的成本更高。
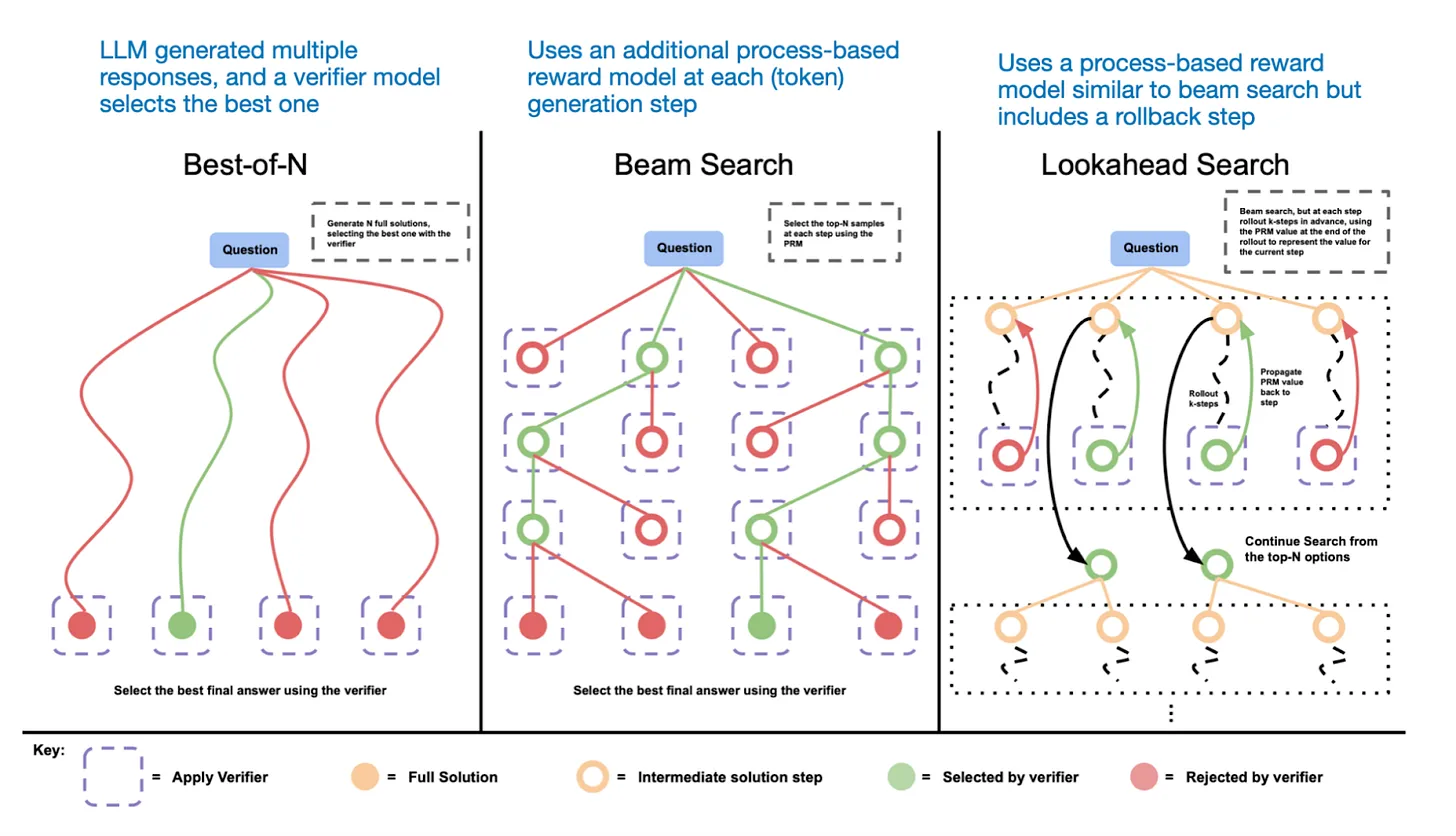
- 一个直接的推理时扩展方法是提示工程。一个经典例子是思维链(CoT)提示,在输入提示中加入“逐步思考”之类的短语。鼓励模型生成中间推理步骤,而不是直接跳到最终答案,会在更复杂的问题上通常(但不总是)会导致更准确的结果。
- 另一种推理时间扩展的方法是使用投票和搜索策略。
- 一个简单的例子是多数投票,让LLM生成多个答案,然后通过多数投票选择正确答案。
- 同样,可以使用束搜索和其他搜索算法来生成更好的回答。
二、纯强化学习(RL)
纯强化学习(RL) ,如DeepSeek-R1-Zero,它表明推理可以作为一种学习行为出现,而无需监督微调。纯RL对于研究目的来说很有趣,因为它提供了对推理作为一种新兴行为的洞察。然而,在实际模型开发中,RL+SFT是首选方法,因为它可以产生更强大的推理模型。可能o1也是使用RL+SFT进行训练的,即o1从比DeepSeek-R1更弱、更小的基础模型开始,但通过RL+SFT和推理时间缩放进行了补偿。

三、监督微调SFT+RL
监督微调(SFT)加上RL,这产生了DeepSeek的旗舰推理模型DeepSeek-R1。RL+SFT是构建高性能推理模型的关键方法。DeepSeek-R1是一个很好的案例,展示了如何做到这一点。

参考实验结果,Deepseek R1(使用SFT+RL)比Deepseek-R1-zero(只使用RL)的效果更好:

四、蒸馏(distillation)
蒸馏(distillation) ,一种很捷径的方法,尤其是用于创建更小、更高效的模型。然而,蒸馏的局限性在于它不会推动创新或产生下一代推理模型。例如,蒸馏总是依赖于现有的、更强大的模型来生成监督微调(SFT)数据。

蒸馏方法:
- 一种是数据蒸馏(ds也是用这种),在数据蒸馏中,教师模型生成合成数据或伪标签,然后用于训练学生模型。这种方法可以应用于广泛的任务,即使是那些 logits 信息量较少的任务(例如开放式推理任务)。
- 一种是Logits蒸馏,Logits 是应用 softmax 函数之前神经网络的原始输出分数。在 logits蒸馏中,学生模型经过训练以匹配教师的 logits,而不仅仅是最终预测。这种方法保留了更多关于教师信心水平和决策过程的信息。
- 一种是特征蒸馏,特征蒸馏将知识从教师模型的中间层转移到学生。通过对齐两个模型的隐藏表示,学生可以学习更丰富、更抽象的特征。
Reference
[1] Understanding Reasoning LLMs:https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
[2] 再看增强大模型推理能力的四种范式及蒸馏微调范式具体实现
[3] 一文理解推理大模型-Understanding Reasoning LLMs
[4] How to distill Deepseek-R1: A Comprehensive Guide
[5] R1爆火之后,思考到底什么任务适合用RL做?何枝NLP
[6] DeepSeek R1 最新全面综述,近两个月的深度思考


















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











